








































.svg)





New
Acceldata Launches Autonomous Data & AI Platform for Agentic AI Era. Learn More →
Platform Overview

Data & AI Observability
Agentic Data Engineering
Data Warehousing
Agentic Runtime
Agentic Data Management
Hadoop Modernization
Platform Overview
Everything you need to build, govern, and scale data and AI workloads—one unified platform.
xLake Architecture
Manage your data estate under one platform
Explore Integrations


Data & AI Observability
Monitor, detect, and resolve data and AI issues with end-to-end observability across pipelines.
Explore
Agentic Data Engineering
Build, orchestrate, and run data pipelines with intelligent agents that automate the entire engineering workflow.
Explore ADE
Data Warehousing
Query your lakehouse in-place with Velox-accelerated performance. 10x faster than traditional warehouses.
Explore Data Warehousing
CAPABILITIES






Agentic Runtime
Distributed training, high-throughput inference, and GPU notebooks—everything you need for production AI.
Explore
CAPABILITIES






Agentic Data Management
Build, deploy, and manage intelligent agents to automate and optimize data operations.
Explore ADM

Industries
Browse solutions to help you solve the complex business challenges unique to your industry.
Explore Case Studies
Resources
Browse materials to help you access the tools, guides, and insights essential to your workflows.








Company
Learn about our mission, leadership, and vision driving modern data operations forward.












Products

Industry
Resources
Company

Back
Platform Overview
Data & AI Observability
Agentic Data Management
Agentic Data Engineering
Data Warehousing
Data Science
Data Platform Modernization
Back
Industries
Browse solutions to help you solve the complex business challenges unique to your industry.
Explore Case Studies
Back
Resources
Browse materials to help you access the tools, guides, and insights essential to your workflows.
Back
Company
Learn about our mission, leadership, and vision driving modern data operations forward.
Back
Platform Overview
Everything you need to build, govern, and scale data and AI workloads—one unified platform.
xLake Architecture
Manage your data estate under one platform
Explore Integrations
Back
Data & AI Observability
Monitor, detect, and resolve data and AI issues with end-to-end observability across pipelines.
Explore
Back
Agentic Data Management
Build, deploy, and manage intelligent agents to automate and optimize data operations.
Explore ADM
Back
Agentic Data Engineering
Build, orchestrate, and run data pipelines with intelligent agents that automate the entire engineering workflow.
Explore ADE
Back
Data Warehousing
Query your lakehouse in-place with Velox-accelerated performance. 10x faster than traditional warehouses.
Explore Data Warehousing
CAPABILITIES
Back
Agentic Runtime
Distributed training, high-throughput inference, and GPU notebooks—everything you need for production AI.
Explore
CAPABILITIES
Products
Platform Overview
Data & AI Observability
Agentic Data Management
Agentic Data Engineering
Data Warehousing
ML & AI Applications
Business Applications
Data Platform Modernization
Platform Overview
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin mi
Explore Platform
Data & AI Observability
Monitor, detect, and resolve data issues with end-to-end observability across pipelines.
Explore ADOC
Agentic Data Management
Monitor, detect, and resolve data issues with end-to-end observability across pipelines.
Explore ADM
Agentic Data Engineering
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin mi nibh
Explore ADE
Data Warehousing
AI-powered observability and optimization for Hadoop and big data environments.
Explore Data Warehousing



ML & AI Applications
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin
Explore ML & AI Applications




Data & AI Observability
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse so
Explore Business Applications
Open Data Platform
An open-source data platform for Hadoop modernization, flexibility, and long-term control.
Explore ODP
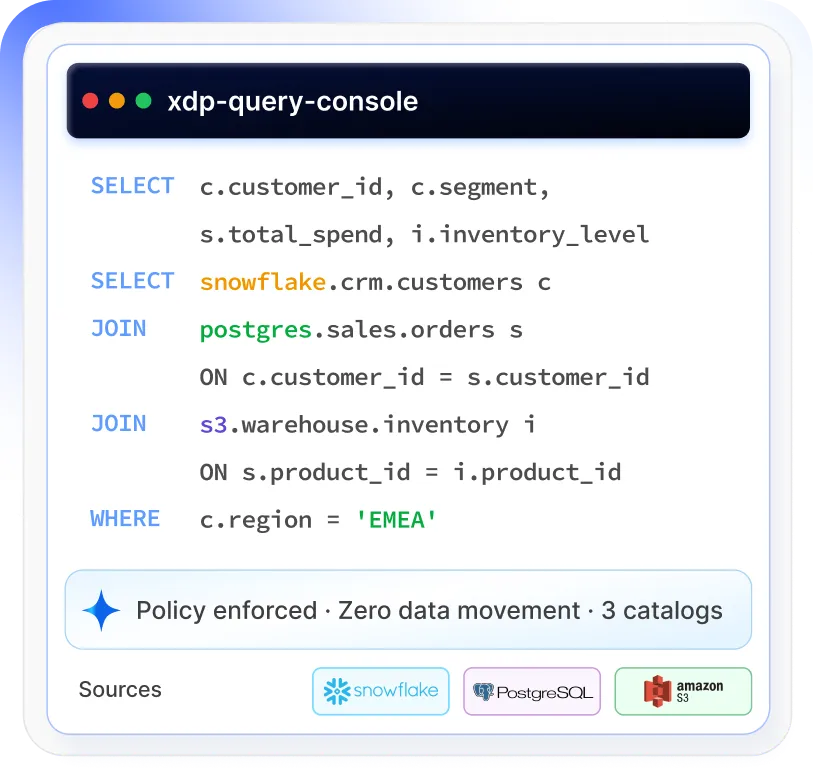
Federated Queries. Heterogeneous Sources. Zero Data Movement.
Governed SQL across your entire data estate. On-prem, cloud, or hybrid. No replication. No vendor control plane.

TRUSTED BY ENTERPRISE DATA TEAMS WORLDWIDE












Query Any Source. Govern at the Query Layer. Own Your Compute.
xLake's federated query engine runs on Trino — extended with native governance, unified catalog integration, and customer-controlled Kubernetes execution.
No proprietary formats.
No forced cloud dependency.
No bolt-on governance tools.
One SQL statement.
Multiple heterogeneous catalogs.
Zero data movement required.
How It Works
xLake connects your sources through a governed query layer — no pipelines, no data movement, no proprietary formats.
1


Connect Your Sources

Register cloud warehouses, object storage, operational databases, and on-prem systems via standard connectors. Data stays where it is.
2
Submit a Single SQL Query
Write standard SQL. xLake's Trino engine builds an optimized distributed execution plan across every registered catalog.
3
Policy Enforced Before Execution
Access controls and catalog visibility are evaluated at the query layer — natively — before a single byte is read.
4
Execution on Your Infrastructure
Queries run on your Kubernetes clusters — EKS, AKS, GKE, or on-prem K8s 1.20+. You control resource limits and cost ceilings.
5
Results Return. Nothing Replicated.
Results go directly to the requesting system. No intermediate copies. No sync jobs. No replication pipelines.
6
Every Execution Is Observable
Granular logs capture which catalogs, connectors, and nodes handled each stage. When something fails, you see exactly where.
What Sets xLake Apart

Governance Built In — Not Bolted On
Policy is enforced at the query layer — natively. No external tools, no separate contracts, no gap between discovery and enforcement. Unity Catalog delivers a single governed metadata layer across Spark, Trino, Jupyter, and Airflow.

Your Compute. Your Clusters.
Execution runs on your infrastructure — EKS, AKS, GKE, or on-prem Kubernetes. Vendor-hosted compute means they own your cost structure and your exit options. xLake inverts that.

No Replication Tax
Data stays where it lives. Teams eliminating replication-dependent architectures see 50–65% storage cost savings — no duplicate datasets, no sync jobs.

98% Workload Portability
Existing Trino SQL workloads move across cloud and on-prem environments without refactoring. Your queries travel with you.
Execution-Layer Observability
When a cross-source join fails or slows, you see exactly where — which catalog, which connector, which node. Not just lineage. Full execution-layer traceability.
The Business Case
Federated query without architectural control creates hidden costs — in storage, tooling sprawl, and workload lock-in. xLake eliminates that.
Outcome
What xLake Delivers

Storage cost reduction
50–65% by eliminating replication for cross-source querying
OpEx reduction
10–15% from open-standard interoperability
Workload portability
98% query reuse across cloud and on-prem
Governance tooling
Native policy enforcement — no external tools required
Deployment compatibility
EKS, AKS, GKE, and K8s 1.20+ on-prem

Built for Engineering Leaders Who Can't Afford Lock-In
Federated query is an architectural requirement — not a differentiator.
xLake delivers a governed, portable, open-standard query layer. Policy enforced at execution. Compute on your clusters. Data stays where it lives.
Dominate with Data
40%
reduction in pipeline
downtime
downtime

30%
faster time-to-model
deployment
deployment
25%
lower cluster costs
99.9%
SLA adherence on
migrated workloads
migrated workloads
Got Questions? Get Clarity
Does xLake require us to move or copy data into a central repository?
No. xLake is built on the principle of zero data movement. Queries execute against your sources in place — whether they live in a cloud warehouse, object storage, an operational database, or an on-prem system. Results are returned directly to the requesting application. No intermediate copies, no sync jobs, no replication pipelines.
How does governance work if data never moves to a central location?
Governance is enforced at the query layer, not the storage layer. Before a single byte is read, xLake evaluates access controls and catalog visibility natively — as part of query execution, not as a downstream audit step. This closes the gap that exists when governance tooling is separate from the query engine.
What infrastructure do we need to run xLake?
xLake runs on your Kubernetes clusters. It is compatible with EKS, AKS, GKE, and any on-prem Kubernetes environment running version 1.20 or later. You control resource limits, scaling rules, and cost ceilings. xLake does not require vendor-hosted compute or a cloud-provider control plane.
How much SQL refactoring will our teams need to do?
Minimal to none for most workloads. xLake's query engine is built on Trino, which uses standard SQL. Existing Trino SQL workloads are compatible at a 98% rate across cloud and on-prem environments. Teams do not need to rewrite queries when moving between environments or adding new sources.
Can xLake connect to both cloud and on-prem sources in the same query?
Yes. That is a core use case. xLake maps cloud warehouses, object storage, operational databases, and on-prem systems into a unified metadata layer through standard connectors. A single SQL statement can span multiple heterogeneous catalogs — regardless of where those sources physically reside.
How do we diagnose performance issues or failures in a federated query?
xLake provides execution-layer observability, not just lineage. Granular metrics and routing logs capture which catalogs were accessed, which connectors were invoked, and which nodes executed each stage of a query. When a cross-source join fails or slows, you can trace the issue to the specific catalog, connector, or node — rather than working backward from an opaque error.
Ready to get started
Explore all the ways to experience Acceldata for yourself.
