.svg)





New

Explore the future of AI-Native Data Management at Autonomous 26 | May 19 --> Save your spot

Everything you need to build, govern, and scale data and AI workloads—one unified platform.


Monitor, detect, and resolve data and AI issues with end-to-end observability across pipelines.
Build, orchestrate, and run data pipelines with intelligent agents that automate the entire engineering workflow.
Query your lakehouse in-place with Velox-accelerated performance. 10x faster than traditional warehouses.






Distributed training, high-throughput inference, and GPU notebooks—everything you need for production AI.






Build, deploy, and manage intelligent agents to automate and optimize data operations.

Browse solutions to help you solve the complex business challenges unique to your industry.
Browse materials to help you access the tools, guides, and insights essential to your workflows.
Learn about our mission, leadership, and vision driving modern data operations forward.


Browse solutions to help you solve the complex business challenges unique to your industry.
Browse materials to help you access the tools, guides, and insights essential to your workflows.
Learn about our mission, leadership, and vision driving modern data operations forward.
Everything you need to build, govern, and scale data and AI workloads—one unified platform.
Monitor, detect, and resolve data and AI issues with end-to-end observability across pipelines.
Build, deploy, and manage intelligent agents to automate and optimize data operations.
Build, orchestrate, and run data pipelines with intelligent agents that automate the entire engineering workflow.
Query your lakehouse in-place with Velox-accelerated performance. 10x faster than traditional warehouses.
Distributed training, high-throughput inference, and GPU notebooks—everything you need for production AI.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin mi
Monitor, detect, and resolve data issues with end-to-end observability across pipelines.
Monitor, detect, and resolve data issues with end-to-end observability across pipelines.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin mi nibh
AI-powered observability and optimization for Hadoop and big data environments.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse sollicitudin
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse so
An open-source data platform for Hadoop modernization, flexibility, and long-term control.

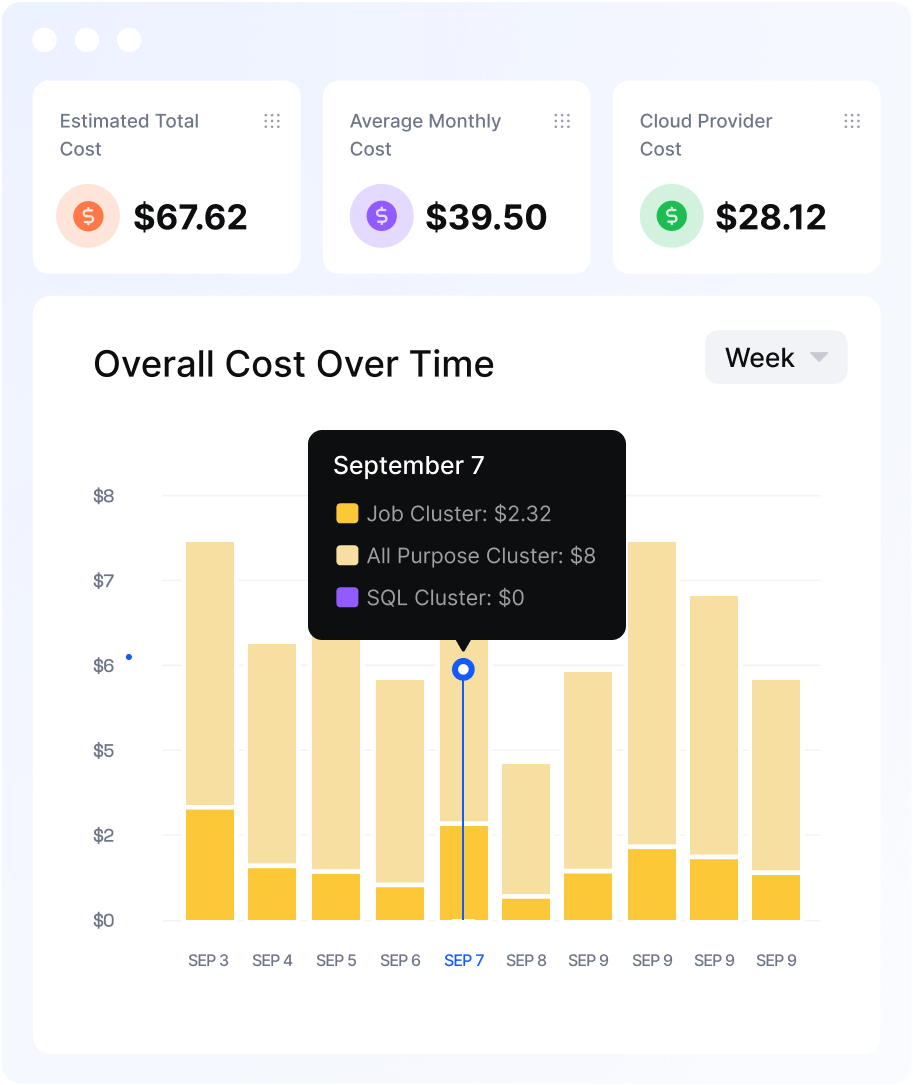
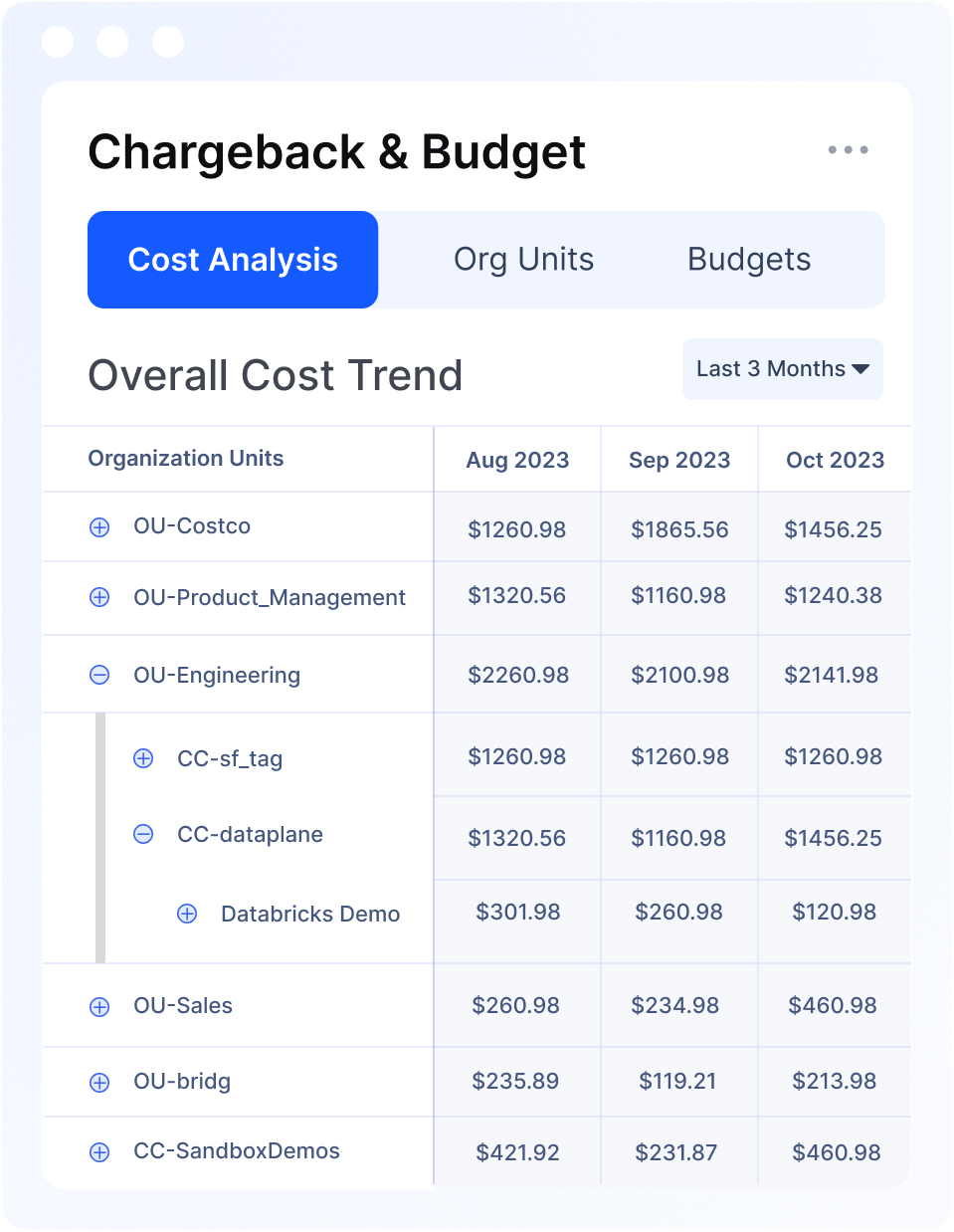
Unify data quality, pipeline reliability, and compute optimization across your Databricks Lakehouse—powered by agentic intelligence.











Acceldata helps Databricks users unify data quality, achieve pipeline reliability, and optimize compute with Acceldata's intelligent observability.



What’s Breaking Your Databricks Pipelines? Data quality, lineage gaps, and AI drift stall even the best architectures.

Acceldata’s Agentic Data Management delivers always-on intelligence across the full Databricks stack.







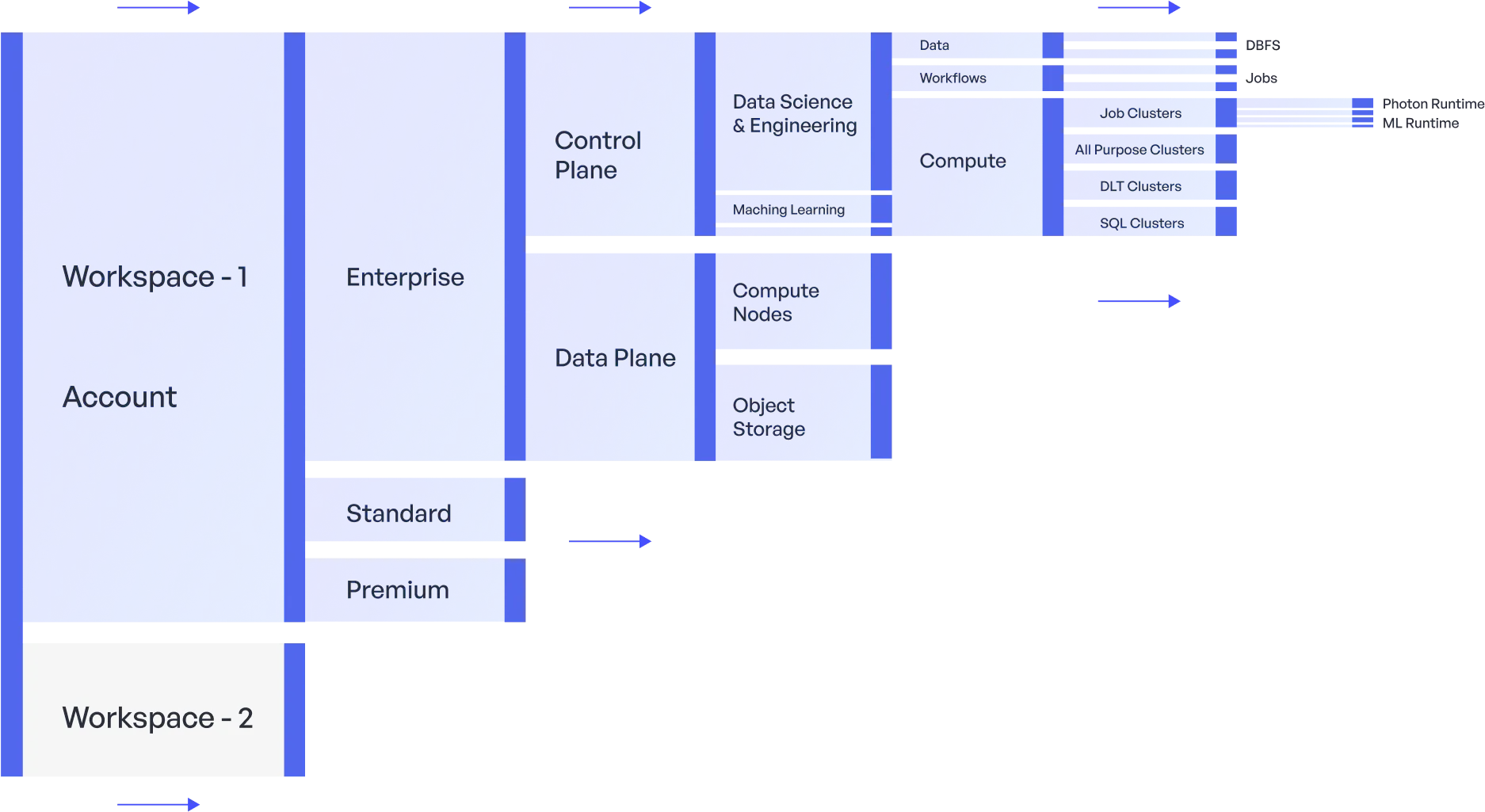
Built to fit your architecture. Choose the right deployment for your scale.


reduction in pipeline downtime.
faster time-to-model deployment.
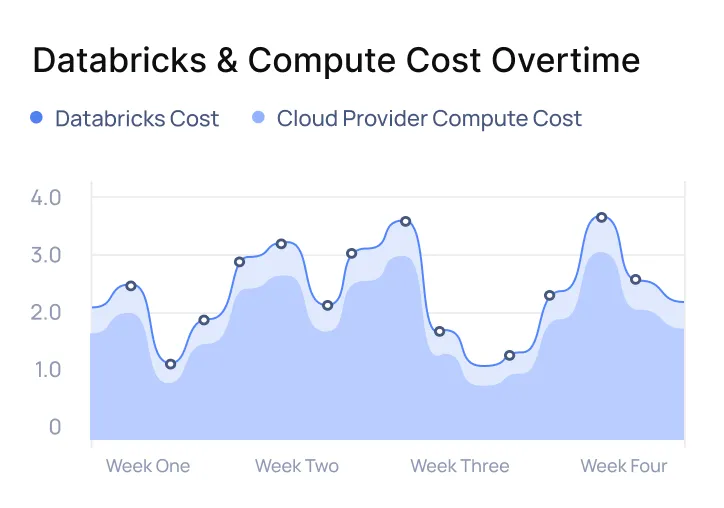
lower cluster costs.
SLA adherence on migrated workloads.
Acceldata integrates with Databricks, data warehouses, BI tools, and orchestration platforms for end-to-end reliability.
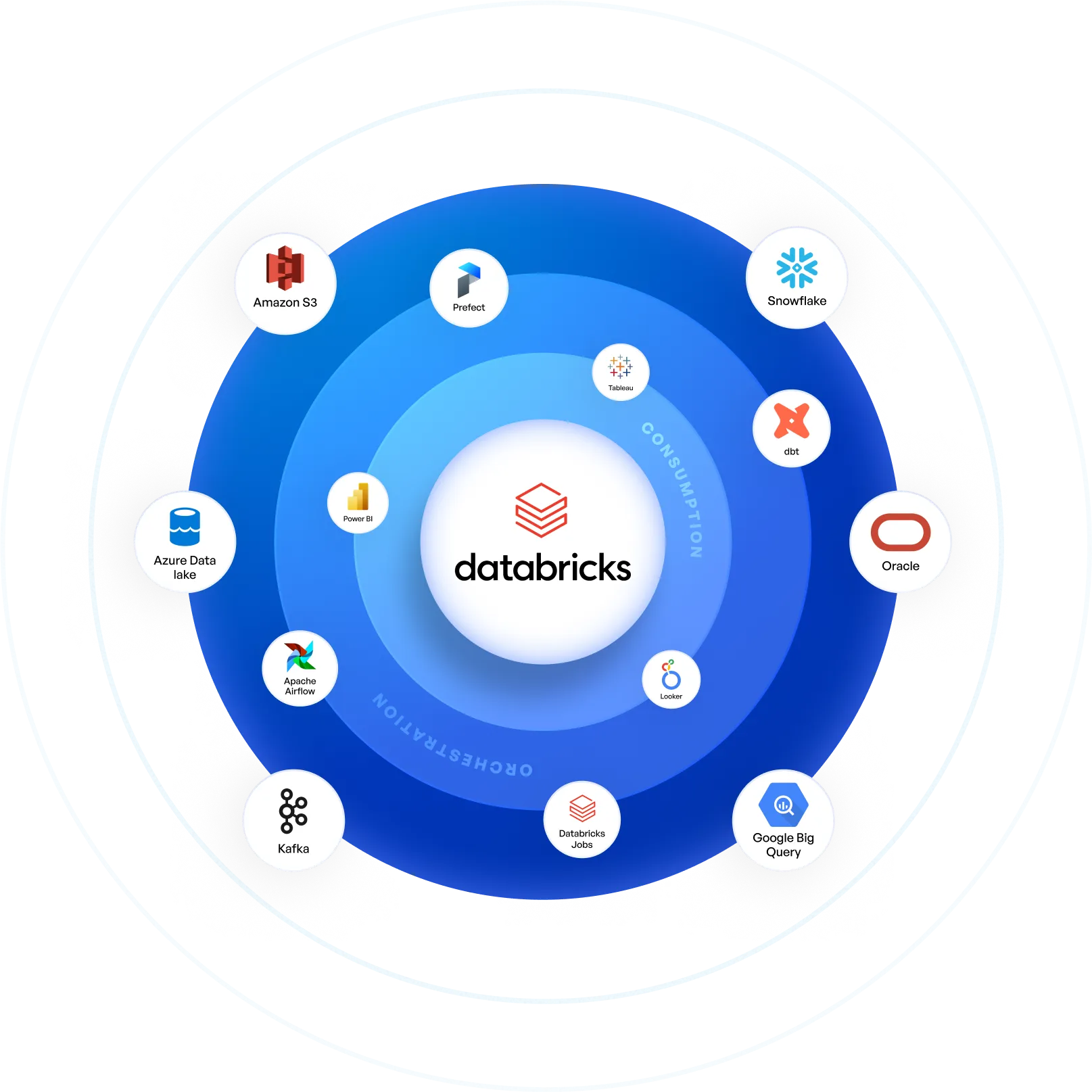 See All Integrations
See All Integrations
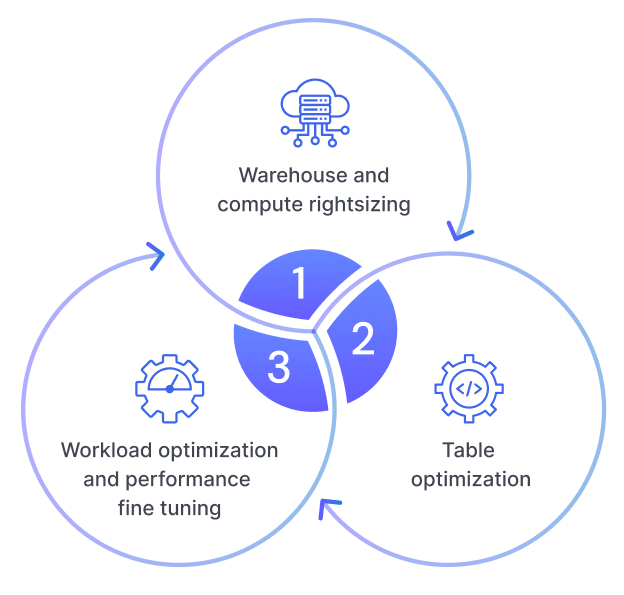
Absolutely. Acceldata identifies overprovisioned clusters, idle workloads, and inefficient Spark jobs—then recommends actions to right-size resources and reduce costs.
By continuously monitoring data quality and detecting drift in training datasets, Acceldata ensures your ML models remain accurate, reliable, and production-ready.
Yes. Acceldata provides full end-to-end lineage from ingestion to output, enabling rapid root-cause analysis across Spark jobs and datasets.
You can choose between native PushDown mode (runs on Databricks for efficiency) or ScaleOut mode (external Spark engine for high-volume workloads).
Most teams gain visibility into data health and job performance within hours. Full observability—including agentic alerts, lineage, and cost insights—can be activated within days.
Traditional tools detect problems; Acceldata's agentic observability reasons over them, recommends fixes, and enables self-healing pipelines.












































.webp)














.webp)
.webp)

.webp)
.png)



.webp)


.png)
.png)
.png)