
























































.svg)




































Most lakehouse implementations fail not because of bad storage or compute decisions, but because metadata is treated as an afterthought. Teams invest months designing medallion layers, choosing between Iceberg, Delta Lake, or Hudi, and tuning Spark jobs.
Then they discover that nobody knows which tables are production-ready, lineage stops at the warehouse boundary, and schema changes break downstream pipelines because no system tracked the dependency.
A lakehouse combines the flexibility of a data lake with the structure of a warehouse. But that combination only works if metadata is accurate, current, and consistent across every engine, layer, and team that touches the data.
Without a strong foundation of AI-ready data, 60% of enterprise AI projects are destined for cancellation by 2026, per Gartner's projections. A significant part of that gap traces back to poor metadata practices that leave data undiscoverable, ungoverned, and difficult to trust.
When metadata falls behind, you get analysts querying stale bronze tables, governance policies applied to the wrong assets, and engineers debugging pipeline failures with no lineage to guide them.
This guide explains how to manage metadata across lakehouse architectures in a way that actually holds up in production.
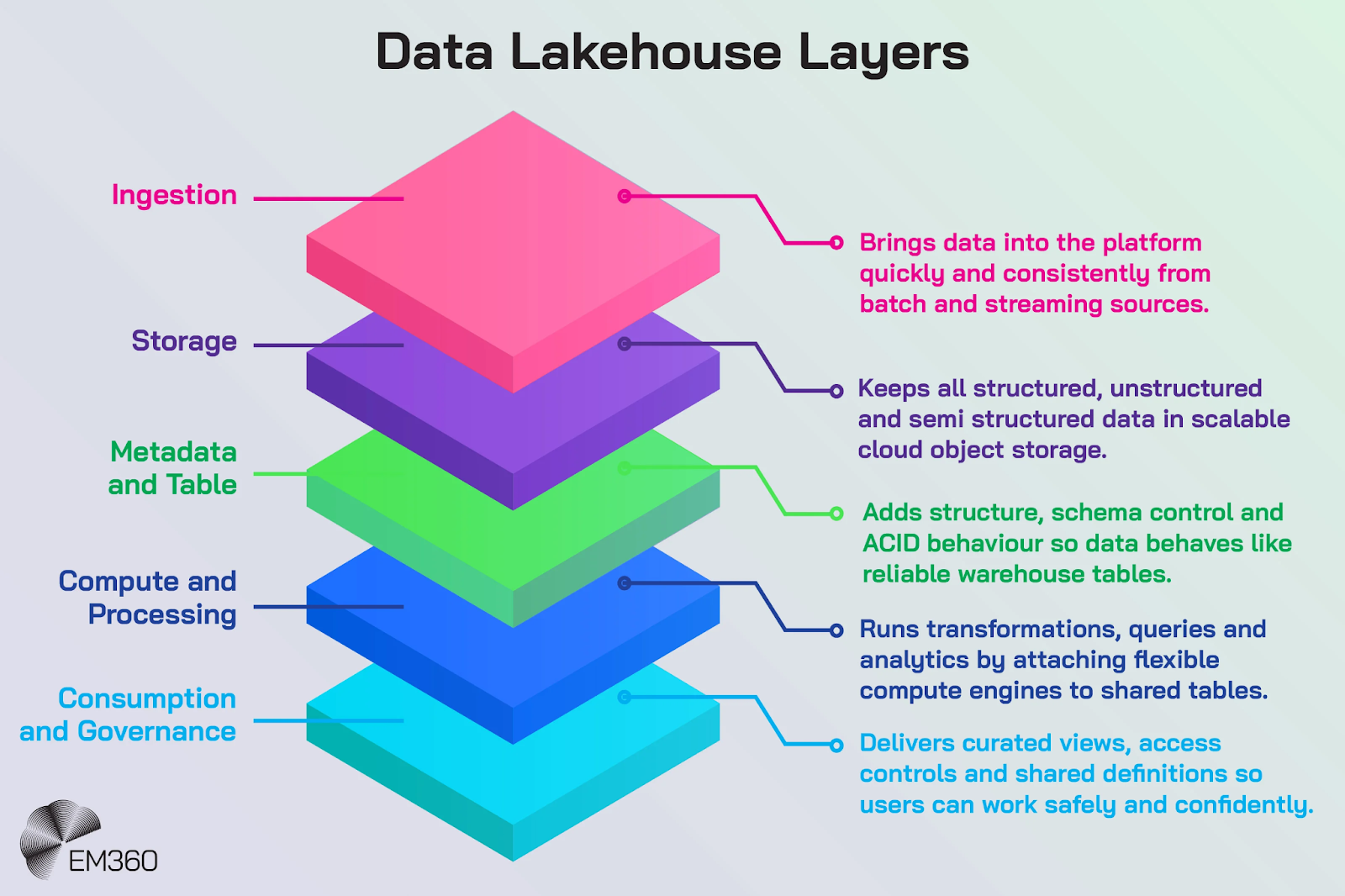
Why Metadata Management Is Critical in Lakehouse Architectures
Lakehouse architectures were designed to remove the long-standing trade-off between flexible data lakes and structured warehouses. They support open storage, multiple query engines, streaming pipelines, and machine learning workloads in one ecosystem. But the same flexibility that makes lakehouses powerful also makes them difficult to manage.
As lakehouse environments grow, enterprises must coordinate ingestion pipelines, open table formats, orchestration tools, semantic layers, feature stores, access controls, and cloud services. Without centralized metadata, teams lose visibility into how these systems connect. Data may still be available, but trust begins to weaken when ownership is unclear, lineage is incomplete, or freshness cannot be verified.
Metadata acts as the control layer that ties these moving parts together. It links technical assets with business meaning and helps teams answer practical questions: where did this dataset originate, how was it transformed, which reports rely on it, and who can use it? That visibility makes governance more scalable and makes operations more efficient.
In real environments, this has a direct impact. When a dashboard breaks, metadata helps teams trace the issue upstream faster. When a schema changes, metadata helps identify downstream dependencies before reports or models fail. When users search for a trusted dataset, metadata provides the ownership, definitions, and usage context needed to choose the right one
The Rise of Lakehouse Architectures
Lakehouse adoption has accelerated as enterprises look for scalable alternatives to traditional warehouses. Open table formats like Delta Lake, Apache Iceberg, and Apache Hudi have made it possible to run SQL analytics, machine learning workloads, and real-time processing directly on cloud object storage.
For example, a media streaming company may store raw video logs, clickstream data, and customer interactions in a central lakehouse. Analysts use structured tables for reporting, while data scientists train recommendation models on unstructured event data.
Without metadata, teams lose track of data ownership, transformation logic, and downstream dependencies. What begins as flexibility quickly becomes operational risk.
Why Metadata Becomes the Control Layer
In lakehouse environments, metadata is not just documentation. Metadata management provides the foundation for:
- End-to-end lineage, showing how data flows from ingestion to analytics and AI models.
- Governance enforcement, ensuring policies, access rules, and compliance requirements are applied consistently.
- Data discovery, helping analysts and engineers find trusted datasets quickly.
- AI readiness, enabling feature tracking, training data versioning, and model explainability.
What Is Metadata Management for Lakehouse Architectures
Metadata management for lakehouse architectures refers to the systems, processes, and technologies used to organize, track, govern, and operationalize metadata across a unified lakehouse environment.
In simple terms, metadata management answers the most critical operational questions in a lakehouse:
- What data exists, and where is it stored?
- Where did this data come from, and how was it transformed?
- Who owns this dataset, and who can access it?
- Which dashboards, reports, or AI models depend on it?
- Is this data reliable, fresh, and compliant?
How Metadata Works Inside a Lakehouse Environment
Lakehouse architectures rely on open storage layers and decoupled compute engines. While this improves flexibility and scalability, it also distributes metadata across multiple systems. Table schemas may live in a metastore, pipeline metadata in orchestration tools, usage metrics in BI platforms, and governance rules in separate security systems.
Metadata management for lakehouse architectures unifies these fragmented signals into a centralized control layer that provides:
- Technical metadata such as schemas, partitions, file formats, and storage locations
- Operational metadata, including pipeline health, freshness, and processing status
- Business metadata like dataset descriptions, ownership, and KPIs
- Governance metadata covering classifications, policies, and access controls
- AI and ML metadata, such as feature lineage, training datasets, and model dependencies
Why Metadata Management Is Different in Lakehouses
Traditional metadata tools were mostly built for centralized warehouse environments with relatively stable schemas and tightly coupled systems. Lakehouses work differently. Data can live in object storage, be processed by multiple compute engines, and change frequently as new pipelines and workloads are introduced.
This means metadata management in lakehouses must be more active and more interoperable. It cannot stop at static cataloging. It has to reflect constant change across ingestion, transformation, analytics, and AI workflows. It also has to support structured and unstructured data across hybrid and multi-cloud environments.
In this context, metadata becomes more than reference information. It becomes operational intelligence. It helps teams understand platform behavior, identify risk, assess downstream impact, and apply governance without slowing down data access.
Lakehouse Architectures – How Does It Look to You?
Every organization builds lakehouse architectures differently. That is why metadata management must adapt to multiple patterns instead of relying on one rigid model.
Common Lakehouse Architecture Patterns
Most implementations follow one of three patterns. The medallion architecture moves data through bronze, silver, and gold layers with stricter transformations at each stage.
The single-zone lakehouse skips layering and relies on table formats like Iceberg or Delta to enforce the schema directly. The federated lakehouse distributes ownership across domains while sharing a common catalog, aligned with data mesh principles.
Each creates different metadata demands. Medallion produces metadata at every layer transition. Single-zone concentrates it in the table format. Federated requires consistency across independent domains. The pattern you run determines where metadata gaps are most likely to appear.
Cloud-Native vs Hybrid Lakehouses
Cloud-native lakehouses run on a single provider with metadata services tightly integrated into storage and compute. AWS with Glue Catalog. Azure with Purview. GCP with BigLake. Setup is simpler, but metadata formats may not transfer across providers.
Hybrid lakehouses span on-premises and cloud, or multiple clouds. A bank might keep sensitive data on-premises while running analytics in AWS. A retailer might use Databricks for engineering and Snowflake for BI. In these setups, each environment has its own catalog, access model, and schema tracking. Without a unifying metadata layer, teams see what exists in one environment but not how it connects to another. Most hybrid lakehouse struggles start at the metadata level, not compute or storage.
Open Formats and Decoupled Compute
Open table formats like Iceberg, Delta Lake, and Hudi add a metadata layer on top of files in object storage. They enable ACID transactions, schema enforcement, and time travel. This lets multiple engines like Spark, Trino, and BI tools query the same data without copying it.
But decoupled compute creates a coordination problem. If Spark writes new partitions and the BI tool's catalog has not been refreshed, reports show stale results. If a schema change registers in one catalog but not another, queries break silently. Open formats solve storage well. They do not automatically solve metadata consistency across engines. That requires a synchronized catalog and near real-time change propagation.
Where Metadata Lives in Each Pattern
Lakehouse metadata is spread across three layers. The table format (Iceberg, Delta, Hudi) holds structural metadata like schemas, partitions, snapshots, and file statistics.
The catalog (Hive Metastore, Glue, Unity Catalog, Polaris) holds registration metadata: which tables exist and where they live. The governance layer (observability platforms, tools like Purview or Collibra) holds business metadata: ownership, sensitivity tags, lineage, and quality scores.
The problem is that these layers often operate independently. A schema change in the table format may never reach the governance layer. An ownership update in the catalog may not reflect in lineage views. Managing lakehouse metadata means keeping these layers connected and current, not just individually populated.
How Do You Manage Unstructured Data in a Data Lakehouse? Open Source Metastore Recommendations?
This is one of the most common questions on Reddit and Quora when teams move to lakehouse architectures. And for good reason. Unstructured data is where most lakehouse projects either scale successfully or spiral into chaos.
Unstructured data includes images, videos, documents, PDFs, log files, audio recordings, sensor feeds, and application logs. In many US enterprises, unstructured data now represents over 80 percent of total data volume, driven by IoT, customer interactions, application telemetry, and AI workloads.
Unlike structured tables, unstructured assets do not come with predefined schemas, which makes discovery, governance, and quality management far more complex.
Why Unstructured Data Is Harder to Manage in Lakehouses
Lakehouse architectures make it easy to store massive volumes of unstructured data in low-cost object storage. But storage alone does not make data usable.
Common challenges include:
- Lack of consistent metadata for files and objects
- No clear ownership or business context
- Limited lineage between raw assets and downstream analytics
- Difficulty applying governance and security policies
- Poor discoverability across teams
Best Practices for Managing Unstructured Data in a Lakehouse
Successful teams treat unstructured data as first-class citizens instead of dumping it into storage and hoping for the best.
Here is what works in production environments:
1. Automated Metadata Extraction
Modern lakehouse platforms automatically extract technical metadata such as file type, size, creation time, and source system. More advanced systems also capture semantic signals like content tags, language, or data sensitivity.
2. Centralized Metadata Indexing
Instead of scattering file information across multiple tools, leading organizations centralize metadata into a unified catalog layer. This makes unstructured assets searchable, traceable, and auditable.
3. Lineage Tracking Across Formats
Unstructured data rarely stays raw. It is processed, transformed, embedded into features, or converted into structured outputs. Metadata management connects raw files to downstream tables, dashboards, and AI models.
4. Governance and Access Controls
Unstructured data often contains sensitive information such as personal identifiers, audio recordings, or customer documents. Metadata systems help classify data automatically and enforce role-based access.
Key Metadata Management Capabilities Needed for Lakehouse Architectures
When evaluating metadata platforms for lakehouse environments, US enterprises should focus on capabilities that ensure scale, governance, and operational trust.
Lakehouse environments combine open storage, multiple compute engines, real-time pipelines, and AI workloads. That complexity requires a metadata layer that can operate across systems, formats, and teams.
Use this checklist to evaluate whether a platform is truly lakehouse-ready.
Source
1. Automated Data Discovery and Classification
- Identify and tag PII, financial data, healthcare records, and other sensitive fields automatically
- Reduce manual effort and improve compliance readiness
2. End-to-End Lineage Tracking
- Capture source-to-dashboard data flows across ETL pipelines, warehouses, and BI tools
- Ensure visibility into transformations, dependencies, and downstream impacts
3. Real-Time Metadata Freshness
- Continuously update schema changes, pipeline runs, and dataset status
- Prevent stale metadata from impacting analytics, governance, and policy enforcement
4. Role-Based Access Controls and Policy Enforcement
- Integrate with enterprise identity systems
- Enforce fine-grained access permissions and dynamic policies across datasets
5. Audit Logging and Evidence Readiness
- Maintain detailed logs of data access, schema modifications, and governance actions
- Simplify regulatory reporting and audit preparation
6. Search and Discovery Layer
- Centralized catalog with business glossary, tags, and ownership visibility
- Reduce time to find trustworthy data across multi-cloud environments
7. Regulatory Framework Support
- Map metadata to SOC 2, HIPAA, GDPR, CCPA, or other relevant standards
- Enable defensible audits and compliance reporting
8. Integration With Existing Data Stack
- Connect to cloud warehouses, ETL/ELT tools, BI platforms, and GRC systems
- Avoid fragmentation and improve operational efficiency
9. Scalability and Performance
- Handle millions of metadata assets and thousands of pipelines
- Support multi-region deployments without latency or operational drag
10. Security and Compliance Certifications
- SOC 2 Type II, ISO 27001, GDPR readiness, encryption at rest/in transit
- Ensure the metadata platform itself meets enterprise security standards
What Enterprise-Grade Metadata Looks Like in Practice
Platforms like Acceldata combine observability, lineage, governance, and automation into a unified metadata layer. Instead of treating metadata as documentation, it becomes an operational control plane that drives trust, reliability, and AI readiness across lakehouse architectures.
This approach allows organizations to:
- Reduce manual troubleshooting
- Improve data trust
- Scale AI initiatives faster
- Maintain compliance without slowing innovation
Quick Evaluation Summary
If your metadata platform cannot:
- Ingest metadata automatically
- Track lineage end to end
- Support unstructured data
- Integrate with observability
- Enforce governance
- Scale across clouds
- Support AI workloads
Then it is not fully equipped for modern lakehouse architectures.
Metadata Management for Lakehouse Architectures in the US
In the US, metadata management for lakehouse architectures isn’t just about scale or performance; it’s critical for regulatory compliance, security, and enterprise governance.
Industries like healthcare, finance, retail, and government face complex rules, and without accurate metadata, even the best lakehouses can become black boxes of pipelines, dashboards, and untracked datasets.
Compliance and Regulatory Expectations
US organizations must comply with evolving regulations:
- CCPA/CPRA: Control and report on consumer personal data
- HIPAA: Protect health information with strict controls
- SOX: Maintain immutable records and audit trails for financial reporting
Metadata helps enforce compliance by capturing lineage, tagging regulated fields, maintaining audit trails, and managing retention/deletion policies. Automated rules can enforce classification and approvals before data is published, reducing manual work while improving governance.
Integration With US Data Stacks
Enterprises rely on multi-cloud and hybrid environments like AWS Glue & SageMaker Catalog, Azure Databricks with Unity Catalog, Google BigQuery & BigLake, and BI tools such as Power BI, Tableau, and Looker. Metadata platforms must:
- Consolidate assets across platforms
- Unify schema, lineage, and access policies
- Enable search, discovery, and governance across services
Scale, Performance, and Security
US enterprises often handle petabytes of data and millions of metadata assets. Key requirements include:
- Real-time updates during streaming ingestion
- Horizontal scaling for multi-region, multi-cloud setups
- Low-latency lineage and impact analysis
- Efficient indexing for search and discovery
Why Metadata Matters
Metadata management is the keystone for US enterprises, enabling them to:
- Reduce compliance risk with classification and policies
- Build trust through automated lineage and ownership
- Strengthen security with policy-aware access
- Accelerate analytics and AI with robust discovery
Metadata Management vs Metastore in Lakehouse Architectures
Many teams confuse metastores with full metadata management platforms. They serve different purposes.
Metastores remain important building blocks, but they are not enough to manage enterprise-scale lakehouse environments.
Turning Metadata Into Your Lakehouse Advantage
Metadata management for lakehouse architectures is no longer optional; it’s the operational backbone that drives trust, governance, and faster analytics. Enterprises that centralize metadata across pipelines, dashboards, and unstructured assets gain real-time visibility into data flows, reduce incident resolution times, and improve analytics adoption.
Healthcare and financial services organizations see similar gains. With regulatory requirements like HIPAA and SOX, metadata-driven governance enables automated audit trails, policy enforcement, and sensitive data classification.
With end-to-end visibility, automated compliance, and trust in analytics and AI pipelines, your teams can move faster, reduce operational overhead, and scale confidently.
Take control of your lakehouse metadata today. Book a demo with Acceldata and see how smarter metadata drives faster insights, stronger governance, and real business outcomes.
FAQs About Metadata Management for Lakehouse Architectures
What is metadata management for lakehouse architectures?
Metadata management for lakehouse architectures is the process of organizing, governing, and operationalizing metadata across open storage, compute engines, and analytics layers. It enables lineage, discovery, quality monitoring, and compliance at scale.
How does metadata management differ in lakehouses vs warehouses?
Lakehouses require metadata systems that handle open formats, unstructured data, and decoupled compute engines. Warehouses usually operate in closed ecosystems with simpler schema management.
Metadata management for lakehouse architectures—where should teams start
Start by centralizing asset discovery, enabling lineage tracking, and establishing ownership and governance policies. These foundational steps create immediate operational value.
Lakehouse Architectures – How does it look to you?
Every lakehouse looks different based on data sources, cloud platforms, and analytics tools. Metadata management provides consistency across these variations by unifying visibility and governance.
How do you manage unstructured data in a data lakehouse?
Unstructured data is managed using metadata tagging, schema inference, automated classification, and object-level lineage tracking. This approach makes files like images, logs, and documents searchable, governed, and analytics-ready.
Are open source metastores enough for lakehouse metadata management?
Open source metastores manage table schemas but do not handle business metadata, governance workflows, lineage visualization, or operational intelligence. Most enterprises require additional metadata platforms.
What metadata capabilities are critical for AI and analytics?
Critical capabilities include automated lineage tracking, data quality monitoring, feature metadata management, and contextual tagging. These ensure AI models and analytics workflows use reliable, trusted, and explainable data inputs.
How should enterprises in the US approach lakehouse metadata management?
US enterprises should adopt metadata strategies that support regulatory compliance, privacy controls, and multi-cloud interoperability. Prioritizing automation, security metadata, and scalability ensures long-term governance and analytics performance.
Summary
This article explained metadata management for lakehouse architectures, why it is critical for modern data platforms, how enterprises manage unstructured data, and what capabilities matter most. You also learned how US organizations approach metadata at scale and how centralized metadata platforms go beyond basic metastores to deliver governance, trust, and AI readiness.









