
























































.svg)



































.png)
The Super Bowl ended two months ago, which means we’re in the midst of NFL Free Agency, the annual shuffle of professional football players hopeful for bigger bucks in greener pastures.
By contrast in the corporate world, the employee shuffle never stops. But since the pandemic, it’s taken on a different flavor. Workers, especially in the tech industry, are harder to find than ever, due to the “Great Resignation”.
This goes double in booming fields such as data engineering. Driven by the shift to remote work, companies have accelerated their efforts to become data-driven enterprises. Once viewed as mere data plumbers, data engineers are now properly valued as the linchpins of any business’s drive to digitize and infuse their operations with data.
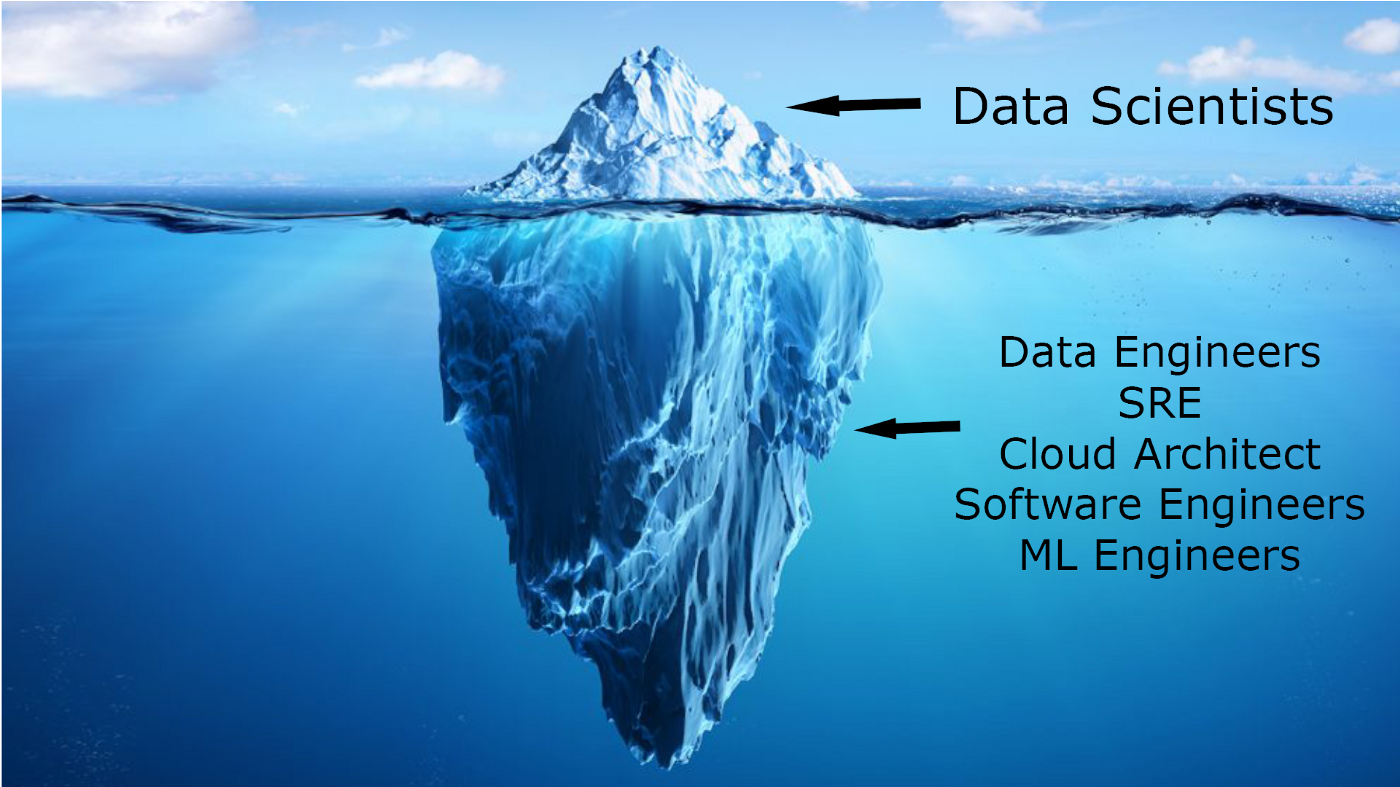
Data Engineers > Data Scientists
Data engineers have replaced data scientists as the fastest-growing, well-paying, and, um, sexiest tech job today.
Considering the hype behind data science even five years ago, this is an incredible flip. It would be like an offensive tackle suddenly garnering more attention and higher salary offers than a strutting wide receiver or the lantern-jawed quarterback. That may never happen in NFL free agency, but it has happened in the area of data ops hiring.
CEOs are finally recognizing that before there can be any fancy AI or ML applications, beautifully-rendered forecasts, or data-driven workflows, you first need someone to find, clean, and merge the data, build the data pipelines, and then monitor that the data remains reliable and flowing.
As one data engineer put it: “Many people realized that before doing fancy Machine learning stuff, you need to be mature on your data = you need data engineers.”
Joe DosSantos, chief data and analytics officer at data analytics software company Qlik, told Fortune magazine recently that for every data scientist at Qlik, there are two data engineers. Others are putting the ratio closer to 4:1 or 5:1 in favor of data engineers.
“I had a team filled with data scientists and started shifting to more data engineers. The data engineering team works far better and solves real world problems far faster,” echoed a user on Quora who claimed to be a manager at a large management consulting firm. “You need data engineers, more than data scientists, to enable the data pipelines and integrated data structures.”
Incredibly Competitive Hiring
Alas, the field of data engineering is so new and, until recently, had such bad PR (see “data plumbers”) that the pool of data engineers is tiny.
“There is a talent crunch everywhere,” according to Daniel Rojas Ugalde, an AI manager with Ernst & Young, who recently wrote a blog post on Medium entitled Why can’t we find enough data engineers? “I’ve been doing 5–10 interviews weekly. No stone is being left unturned. We even expanded our search from 1 to 6 countries. We still can’t find enough.”
“The number of job ads for data engineers is crazy,” confirmed a data engineer who recently interviewed with eight hiring companies in one month. He ended up getting three offers, all offering different levels of remote work.
So if you are like 99 percent of data operations managers out there today, your situation is:
- Your company has major plans to transform your data infrastructure
- But you lack the modern data tools to streamline this transformation
- Also, you need more data engineers to help execute these plans
- However, competition is fierce for not just good data engineers, but any data engineers
How can you solve points 2-4, in order to accomplish your overarching goal number one? Surprisingly, one good way is by ensuring that your data operations and engineering team is equipped with a modern multidimensional data observability platform.
Data observability is increasingly being recognized as the all-in-one tool chest of choice for data engineers. According to Ben Rogojan, aka SeattleDataGuy, the day-to-day worklife of a data engineer involves building and maintaining data pipelines, ensuring data is cleansed, governed, and of high quality, optimizing and maintaining high query performance, and monitoring and maintaining the overall data infrastructure. These are all tasks that can be radically simplified by a unified data observability platform that provides visibility and control at every layer of your data infrastructure, in every repository and pipeline, no matter how far-flung and distributed.
Good, Ambitious Workers Expect Good Tools
Since the field is so young, the data engineers you’ll be interviewing and hiring will by and large be in their 20s and 30s. Some will be freshly-graduated data engineers. Others will be data scientists recognizing that the once rarefied skills of tuning ML models and feature engineering have become commodified and automated by pre-built cloud applications.
As a veteran data scientist wrote on Quora: “The race now is actually to remove all the math to the point where even a marketing guy can just click a few boxes and get back [ML] test results from Microsoft Azure, Google Cloud or Amazon AWS.”
Still other data scientists-turned-data-engineers recognize that “80 percent of data science is data cleaning.” They are going to where the business needs are.
Whatever their route to the field, one thing is for sure: they want the best tools.
Every ambitious software engineer knows the importance of good technology. In order to advance in their career, they need to be able to efficiently create and maintain complex, revenue-generating, business-critical applications and systems. This is how you earn the reputation of a prized 10x engineer.
Attaining 10x superstar status is impossible when your tools are substandard or even a hodge-podge of competent but non-unified point solutions.
“A junior engineer will spend 8 hours chopping with a dull axe,” wrote Michael Lin in a blog entitled How to be a 10x engineer. “The senior engineer spends an hour picking the right chain saw. And 5 minutes cutting the tree.”
Or think of it this way. If you were a young network engineer, would you rather join a company that was deploying 5G, SD-WAN and Wi-Fi 6, or one that was still holding onto MPLS WAN circuits and copper-based DSL?
If you were a budding desktop engineer, would you rather manually load system images onto 5-year-old Dell towers, or use automated system update and remote troubleshooting tools to maintain a fleet of M1 MacBooks?
If you were an ambitious software developer, would you rather be building modules for old-school monolithic, on-premises business applications like SAP and Oracle, or working in a modern, cloud-native, microservices-based architecture?
You get the picture. A multidimensional data observability platform empowers your data engineers to move beyond being plumbers of data science and actually become 10x engineers. It also provides vital proof to your potential hires that you value their potential and are willing to invest in all areas of the business for future success.
Avoid the Temptation of Point Solutions
As data engineering becomes a proven and widely accepted profession, the scope of responsibilities has expanded. It’s gotten such that many new specialities and job titles have emerged under the umbrella of data engineering. They include:
- ML engineer
- Data reliability engineer
- Analytics engineersu
- Data platform engineer
A few older ones have also been subsumed under data engineering, such as:
- Database administrator
- Data analyst
For each of these specialized job titles, new point solutions are emerging that claim to be best-of-breed for their function. And for the older job functions now falling under data engineering, there is no shortage of legacy software past their sell-by date.
The temptation is to empower your individual team members and let them choose what they think are the best tools for the job. However, when your data engineering tools are not integrated, your data ops team members are not coordinated. And leads to poor efficiency, high manual work and lack of automation, high data management costs, wasteful data silos, and much more.
True Heroes of the Modern Data Team
Data engineers are the real heroes of the data team, just without the hero complex.
They aren’t data plumbers and handymen. They envision, deploy, and maintain the data infrastructure that is responsible for 95 percent of the success of every ML and analytics project.
Without the right tools, it is time-consuming to gather, process, and clean data, establish data pipelines, and guarantee that they stay high-performing and error-free.
That's why we at Acceldata developed a multidimensional data observability and management platform that automates much of the fix-it tedious labor that takes time out of the data engineer’s day.
This frees them up to focus on operational machine learning initiatives as well as other revenue-generating and mission-critical tasks.
Data engineers are the folks who get things done everyday. They’re so much more than mere “plumbers of data science,” and they deserve the best technology.
To learn about how Acceldata can turn your data engineers into 10x engineers and superstars, request a demo here.








.webp)
.webp)



