
























































.svg)




































Streaming data has become a requirement for enterprises to build and operate great data products, and Apache Kafka is far and away the standard for real-time streaming.
While adopting Kafka is becoming essential, data teams are increasingly using data observability to reduce their Kafka costs.
Kafka started off as open-source software installed on a server. Complex and highly-configurable, early Kafka adopters learned first-hand how difficult, time-consuming and expensive managing Kafka clusters could be. Those staying with on-premises Kafka are adopting solutions such as data observability platforms to empower them with automated visibility and control over their environments.
Other companies are turning to the cloud, where a range of options abound, each offering different levels of concierge service for Kafka. To oversimplify things, let’s divide the Kafka services into two basic categories:
Kafka-as-a-service, in which your Kafka clusters are lifted-and-shifted to a hosting provider such as AWS, Cloudera, Red Hat (IBM), or Azure, which handles much of the infrastructure management, including provisioning, configuring and maintaining servers. For security, each customers’ Kafka instances are hosted on their own physical servers in a single-tenant architecture. Though in the cloud, customers still retain most of the control over their Kafka environment — meaning they still have the responsibility to manage it, too.
Fully-managed Kafka, pioneered by Confluent Cloud. Confluent Cloud removes nearly all the operational hassle out of running Kafka, while providing the instant scalability and no-fuss reliability that developers love. As Confluent Cloud evangelist Kai Waehner outlines in a self-admitted flattering way, if the Kafka software is a car engine, then hosted Kafka or Kafka-as-a-service is a car, making Confluent Cloud the equivalent of a self-driving car.
How the Cloud Does — and Doesn’t — Cut Your Costs
Despite being the standard bearer for fully-managed Kafka, Confluent does actually offer Kafka in any flavor that customers want, including on premises, hybrid, and hosted/as-a-service. It recognizes that many customers are simply not ready to jump from one extreme — the full manual control and customizability of Kafka — to another extreme — little control over Kafka, and even less visibility, in serverless Confluent Cloud.
That flexibility combined with the technical credibility of its founders, who helped create Kafka when it was an internal project at LinkedIn, has helped Confluent gain market traction.
Since Kafka costs, apart from hardware, comes from managing and developing applications for it, then companies still have plenty of opportunities to streamline their Kafka environments and optimize their price-performance.
In the case of Kafka-as-a-single-tenant-service, operational complexity remains high for customers. Though hosting providers will automate tasks such as bringing on a new Kafka cluster, there are still many dashboards to monitor, deployment decisions to be made, bottlenecks and data errors to fix, storage to manage, etc. To alleviate this operational burden and help optimize the price-performance of your dynamic Kafka environment, hosted Kafka users will benefit greatly from the same continuous data observability as their on-premises and hybrid counterparts.
Do fully-managed Kafka users face the same operational costs? Confluent would argue no, saying that Confluent Cloud’s back-end economies of scale, near-zero administration requirements and instant, automatic elasticity for users translates into huge Total Cost of Ownership (TCO) savings — $2.6 million in savings over three years versus self-managing and deploying Kafka, according to a 2022 Forrester Total Economic Impact study commissioned by Confluent.

A Low Ops Dream to Some — A (Fiscal) Nightmare to Others
Confluent’s promise mirrors the one made by Snowflake, down to a $21 million-ROI-over-3-years study by Forrester. The low-ops, highly-scalable cloud data warehouse has been embraced by developers and data-driven companies. Enthralled by their new-found agility and time-to-market, many users mistook “low ops” as an excuse to do “no ops.” They ignored basic principles of value engineering and cloud fin ops, and neglected operational oversight, such as monitoring costs and setting up cost guardrails.
That came back to bite them in the form of billing “horror stories”. I shared a famous example in a recent blog about optimizing Snowflake usage about a company that misconfigured a $7 hours-long code test, resulting in a $72,000 charge from Snowflake instead. More prosaically, other Snowflake users found that cost-optimization was not automatic, and still required substantial effort and oversight on their part.
Snowflake users were forced to try out a variety of solutions, from Snowflake’s built-in Resource Monitors to visual third-party dashboards and reports and a host of other tools. However, even when cobbled together, these solutions are unable to provide users continuous visibility, forecasting, and control over their costs, not to mention other key areas such as data reliability and data performance.
Similarly, optimizing costs in Confluent Cloud’s dynamic pay-as-you-go charging model is neither simple nor automatic. Streaming data volumes can instantly spike up to 10 GB per second. Monitoring and preventing such potential cost overruns is not easy. While the Confluent Cloud Console can show preliminary usage in real-time, actual customer costs lag between 6 to 24 hours.
And while Confluent Cloud enables users to create real-time triggers and alerts around data performance problems, there are none for cost overruns. That can be a problem if a developer forgets to turn off a high-volume test streaming data pipeline, or if a conservative archiving policy leads to a buildup in storage charges. Confluent Cloud users may not notice until the hefty monthly bill arrives.
Moreover, users are starting to publicly state that despite whatever Confluent Cloud’s web calculator may say, the security blanket of a fully-managed service comes at a commensurate price.
How Data Observability Helps
For customers serious about monitoring and managing their Confluent Cloud environments, Confluent actually encourages them to look to a third-party provider.
That’s where an enterprise data observability platform like Acceldata can come in. Acceldata ingests cost and performance metrics via Confluent Cloud’s API, generates additional analytics through its own monitoring, and then combines the two to create further insights, alerts and recommendations. In particular, here are five ways that Acceldata helps users prevent cost overruns and optimize costs:
1) Ongoing visibility and alerts around the performance and usage of all Confluent Cloud data pipelines. With real-time streaming, the volume of events processed, sent, and stored can spike wildly, especially with the instant, multi-GB scalability of Confluent Cloud. Acceldata’s compute observability helps monitor for data spikes that can create bottlenecks or crashed processes. Acceldata also provides the real-time view that helps you select the right number of Partitions and Topics to optimize your cost-performance.
2) Producer-topic-lineage visibility. Acceldata’s Kapxy tool lets Confluent Cloud customers drill down further into the three key Kafka components — the Producer, Topic, and Consumer — so you can track your data on a more granular level from end to end. By giving an in-depth view of how data actually flows, customers can then accurately calculate usage and cost by pipeline, application, or department. This enables accurate cost chargebacks, ROI calculations, and supports data pipeline reuse and other value engineering efforts.

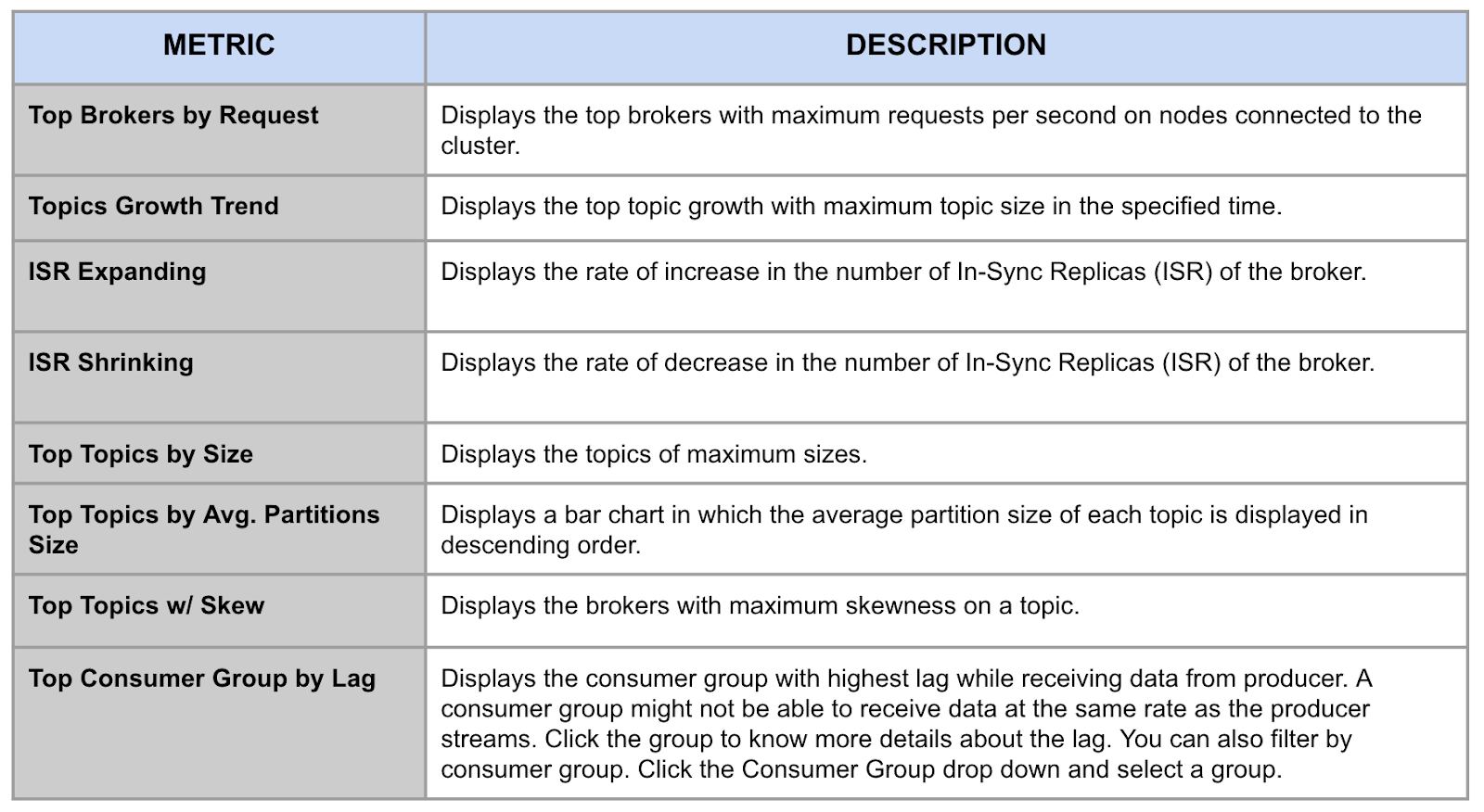
3) Monitor and prevent consumer lag. One of the biggest potential problems in Kafka is the gap between ingested data and data received by the downstream application or Consumer. If the gap grows too large, then data stored in the Kafka broker may automatically expire before it is successfully transmitted. Acceldata provides high-level visibility over your entire Confluent Cloud data pipeline for potential concerns such as offline and under-replicated Partitions, largest and most skewed Topics, whether the number of replicas going out of sync is growing, and Consumer groups with the most lag. You can drill into the Consumer groups or view individual events. All of this visibility will help you prevent Consumer Lag before it becomes an outright problem, forcing you to increase costly compute or storage to compensate.
4) Preventing data loss. As mentioned above, Consumer Lag and other bottlenecks not only directly increase your processing costs, they can also lead to data loss. That’s because users have control over how long data is stored by Kafka Brokers (servers). If data bottlenecks or delays go on too long, then data may be purged by the Broker before it is successfully transmitted onward to the Consumer applications. Acceldata’s monitoring dashboards help you diagnose the causes of data loss, while tools such as Kapxy pinpoint the exact data that has been lost and where.
5) Clean, validate and transform streaming data. Acceldata works with Kafka and Confluent Cloud pipelines to ingest, validate and transform events in real-time. This improves your data quality and reliability. And that reduces the need to search out and fix data errors, and troubleshoot the offending data pipelines and applications. This reduces your operational costs and boosts your ROI.
All five of these Acceldata benefits also help 6) Ease the initial migration of your old Kafka environment into Confluent Cloud. As a multi-tenant, highly-managed architecture with custom features not available in Kafka, the best-known being the ksqlDB, Confluent Cloud differs enough from single-tenant Kafka clusters on-premises or hosted that any migration will be a total refactoring of your environment from the ground up, not a simple lift-and-shift.
Looking to Reduce Kafka Costs? Meet Acceldata
Acceldata’s automated data preparation and monitoring help make the migration smooth and pain-free, while our recommendations help you rightsize your resources to match workload and SLA requirements so that you can balance performance with cost.
Using fully-managed Confluent Cloud does not allow companies to neglect operational oversight.
In fact, Confluent Cloud customers can benefit as much from the additional visibility and control from a continuous data observability platform like Acceldata as self-managed on-premises and hosted Kafka users.
Request a demo of the Acceldata Data Observability platform.









