
























































.svg)




































Too many system and data engineers focus exclusively on highly-granular performance metrics with query speeds being the dominant one, sometimes augmented by metrics such as data accuracy and data storage costs.
All of these metrics are valuable. But only to a point.
Each individual metric only gives limited visibility into the overall health of your data, data infrastructure, and data pipelines. Taken in isolation, they can be very deceptive, too. Similarly, businesses can boast very high query speeds, yet still suffer from poor data performance overall.
Or they try to improve one metric, and make another suffer. For instance, a business rushing to improve their query speeds could end up investing too much in cloud storage and bandwidth, causing their costs per TB to go through the roof.
Two-Fold Problem
There are two primary reasons for why data operation success is still measured using overly-granular metrics. One is technical, and the other is mindset.
Let’s start with technology. Classic data monitoring tools emerged during the heyday of classic BI (Business Intelligence), when companies operated a few, tightly-controlled data warehouses feeding a small set of relatively simple analytics applications. Relatively few things could go in this small data universe. That didn’t stop data monitoring tools from spitting out copious metrics and alerts, which the data engineers could react to, or in most cases safely ignore.
Other data engineers used Applications Performance Management (APM)-based tools to help manage their data warehouses. Like old-school data monitoring tools, APM-based observability tools tended to focus on low-level metrics and alerts that enabled teams to react to problems. They could get the job done, though their capabilities were crude — no surprise considering that applications, not data sources, remained their raison d’etre.
And like data monitoring tools, APM-based observability tools could not produce composite metrics with insight into the overall health of your data pipelines, or predictive metrics that could help teams forecast and prevent troublespots. Again, that sufficed when data operations were simple and had few requirements put upon them.
Today’s Data Pipelines — Useful, Complicated — and Fragile
No longer. Today’s data infrastructures are sprawling, complicated and utterly mission-critical.
Why did it change? For many reasons. First, the supply and demand for data exploded. There are now a massive number of new data sources: social media, IT logs, IoT sensors, real-time streams, and many more. To store them, enterprises embraced new forms of cloud-native storage such as data lakes. Data lakes are more scalable, easy to deploy, and cost-effective than on-premises data warehouses.
There is also a whole new generation of real-time analytics applications and interactive data dashboards making data much more accessible to your businesspeople, using them to inform mission-critical decisions.
To connect the two, data ops teams scrambled to build out networks of data pipelines tethered between data lakes and applications. These not only employed more technologies than ever (ELT, CDC, APIs, event streaming, and more) but were also used in much more demanding scenarios, including real-time operational AI, predictive analytics, and more.
Data pipelines suddenly became mission-critical, even as they became ever more complicated — and fragile. And conventional data monitoring and APM-born observability tools were totally not up to the task of helping data engineers manage data pipelines. Unsurprisingly, this is where most problems are emerging today — where the data is in motion, not where the data is at rest (such as a data lake or data warehouse).
Data engineers in many organizations have found themselves in an exhausting daily battle to find and fix bottlenecks, data slowdowns, inaccurate data, and other service level agreement (SLA) violations in their data pipelines.
They have also found that data pipeline problems tend to be holistic and system-wide. There is rarely a single root cause for a slowdown or other problem — there are many causes. And because data monitoring and APM tools are so focused on individual metrics and alerts, they weren’t giving engineers the system-wide visibility they needed to fix them. Nor did they utilize analytics themselves to crunch data in order to predict potential problems nor offer useful solutions.
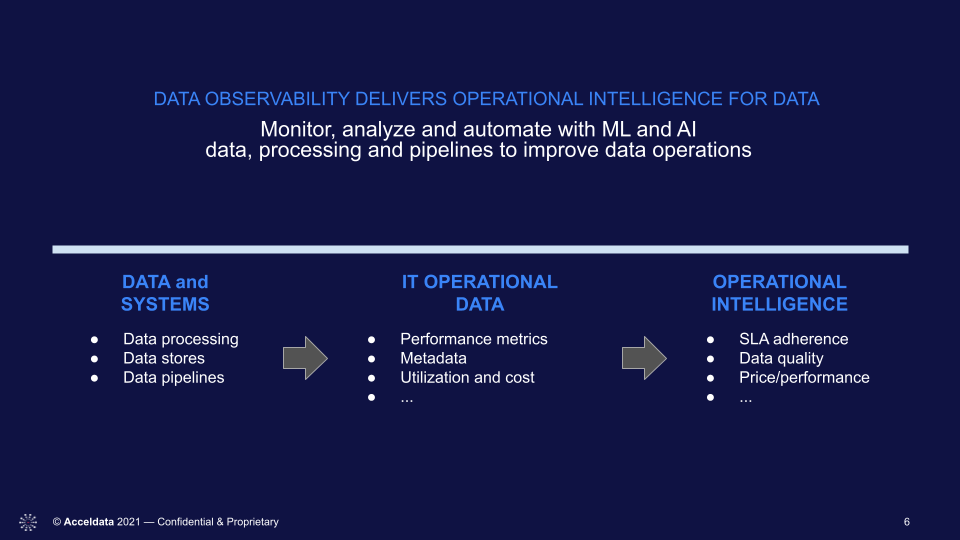
The Solution — True Data Observability
The general public woke up to the importance of the global supply chain after COVID-19 caused shortages in many products (I’m looking at you, toilet paper). Similarly, widespread data bottlenecks, unreliable data transmissions, and the inability for data engineers to manage and solve them, should collectively be a wakeup call for businesses to finally solve their data pipeline management problems.
Fortunately, a new generation of data management tools has emerged, ready to empower data ops teams. These data observability tools are built from the ground up to provide data engineers with the visibility, control, and predictive insight to quickly troubleshoot current problems and get ahead of potential issues.
Unlike the data monitoring and APM observability tools of yore, data observability tools provide a centralized, 360-degree view of your overall data performance. Rather than drowning you in reams of detailed metrics and false alarms, data observability tools correlate events across all of your data pipelines to provide a high-level dashboard showing the overall health of your systems. Armed with this intelligence, data engineers can troubleshoot system-wide data pipeline issues, drilling down into root causes and selecting the correct remediation tactics developed by the data observability platform’s internal machine learning engine. Or they can scout potentially-worrying trends and, again, take AI-recommended actions.
Or going back to the football analogy: data monitoring and APM observability tools only help teams with statistics like yards gained or penalties incurred. Data pipeline monitoring tools actually help you win the game.
Manage Data Pipelines More Efficiently with Acceldata
Founded in 2018, Acceldata is the modern data observability platform built to solve the problems of today’s data pipelines, not yesterday’s data warehouses.
Our three-level, ML-powered solution empowers data ops teams to ensure reliable delivery of data, friction-free scalability, and pipeline networks that are optimized not just for performance, but also costs and capabilities.
In other words, Acceldata keeps its eye on the ball to help you win the data performance game.
Get a demo of the Acceldata Data Observability Platform and learn how your data team can improve data operational intelligence.







