
























































.svg)




































The Acceldata Engineering team sought a way to identify Kafka Producer-Topic-Consumer relationship metrics, which resulted in us building our own Kafka utility, named Kapxy.
The following provides insight into our journey, and it explains how we identified the need for the utility, and how we developed it. We’ll also demonstrate how it’s being used in Acceldata Pulse, our compute performance monitoring solution that helps data teams optimize data processing reliability, scale, and cost.
Kafka Definitions
First, let’s establish some definitions to help you understand the context for how, and where, Kapxy is used.
We’ll start with a general definition of Kafka, which is a fast, scalable, distributed and fault-tolerant publish-subscribe messaging system. It's used as a real-time event streaming platform to collect big data and to do real-time and batch analysis.
Kafka has three basic components named Producer, Consumer and Broker. These three components work together to achieve the publish-subscribe messaging system. Let’s look more closely at these, and other Kafka components:
Producer
A Kafka producer is the Kafka component that's responsible for producing messages or events. The Producer connects to the Kafka Broker and pushes a message to a particular Broker Topic.
Topic
A Kafka Topic is a logical grouping of messages. All relevant messages or events will be Produced to a single Topic in a Kafka Broker.
Broker
A Kafka Broker is a Kafka Server that listens on a particular port and consumes the messages/events from the Producer and keeps it in-memory for the consumers to consume them from the respective Topics.
Consumer
A Kafka consumer is the component that connects a Kafka broker and consumes the messages/events from the respective Topic.
Kafka observability
When it comes to Kafka observability and monitoring, we expect the JMX port to be exposed and the following are the generic metrics that we collect:
Customer feedback
The metrics outlined above are displayed in the Acceldata Pulse dashboard. However, after talking to a number of our customers, we discovered that the information they most want was missing from these charts. They wanted to plot the relationship between each of the three Kafka components (Producer, Topic, Consumer) in a chart, and we initiated a project to supply that
Hitting a dead end
We managed to get the Topic-Consumer relationship metrics from the exposed JMX port, which tells us which consumers are consuming from which Topics.
The first place we looked for the Producer-Topic relationship metrics was in APIs and JMX metrics. But the most valuable insights came from answers we found on Stack Overflow, all of which pointed to the fact that the Producer-specific information we were looking for was not available as Kafka's implementation has this limitation. Here are some of those responses:
It's not possible. A Kafka broker doesn't have any information about connected producers even because the producer could not provide any identity information on connection; for this reason there is no command line tool for doing that. (Know existing producers for a Kafka topic)
There is no way to achieve this as Kafka does not store any metadata about producers centrally so there is no chance to collect all that information. (Is there any way to get all producer's IP for every Kafka topic?)
There is no command line tool available that is able to list all producers for a certain topic. This would require that in Kafka there is a central place where all producers and their metadata are being stored which is not the case (as opposed to consumers and their ConsumerGroups). (How to list producers writing to a certain Kafka topic)
One of the Stack Overflow answers suggested that they managed to get the list of Producers via Kafka Broker JMX metrics but NO Topic related information attached to it.
You can view the MBeans over JMX, perhaps using jvisualvm (though you'll have to add the mbean browser plugin to it). Once you connect to the broker, look in the following mbean path: kafka.server -> Produce -> [contains your list of producers] (How to list producers in kafka)
We sought a way to modify Producers so they send metadata (e.g., which Topic it is producing for messages/events) to our Pulse server and later use that information to plot our charts. But one big caveat with this approach is to ask customers to make changes to their producer's source code. Many customers won't like this idea of adding our SDK to their source-code and few of the instances the producers were not in control of our customers that they cannot ask for this modification.
A journey to the center of the Kafka implementation
In search of the Producer-Topic relationship metrics, we started to deep dive through the Kafka's internal implementation documentation and network protocols.
Kafka uses a binary wire protocol over TCP. Since the Kafka protocol has changed over time, clients and servers need to agree on the schema of the message that they are sending over the wire. This is done through API versioning. Before each request is sent, the client sends the API key and the API version. These two 16-bit numbers, when taken together, uniquely identify the schema of the message to follow. The server will reject requests with a version it does not support, and will always respond to the client with exactly the protocol format it expects based on the version it included in its request.
- List of Kafka Protocol primitive types: Apache Kafka
- List of constant error codes: Apache Kafka
- List of API Keys: Apache Kafka
Since we're interested in the Producer-Topic relationship metrics, the "Produce" API immediately got our attention (Apache Kafka). Each of these Produce requests got a "[topic_data]" field in them. The "[topic_data]" consists of two fields including the "name" field which is basically the Topic name.
As per Kafka's protocol implementation, each request has a request header attached to them. The produce request header got a field "client_id" which is basically our "Producer ID".
Now, in a single Produce request we're able to get the metrics that we wanted. Producer ID and the Topic names that the producer is producing the messages/events into.
Into the packet
To validate this idea of extracting the required metrics from the Kafka network packet we used wireshark and tried dissecting the packet sent to the Kafka broker port.
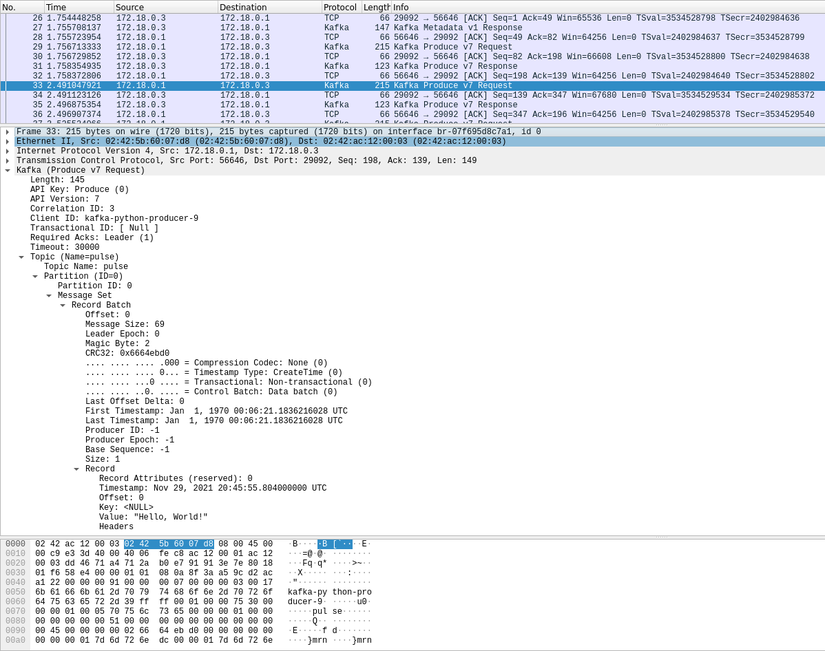
At Acceldata, we have developed all of our agent utilities in Go because of it's excellent support for statically linked cross-compilation and the availability of the extensive packages. We developed a custom connector we call (named “kapxy”) using the package "gopacket" (https://github.com/google/gopacket). You can just connect to preview and extract the information from the captured packets.
Pulse’s Kafka spider chart
From the metrics that we started collecting from the network packets sent to Kafka broker using our newly developed Kapxy utility and the JMX metrics that we already collect from the Kafka broker server, we were able to figure out the relationship between the Kafka Producer-Topic-Consumer components and plot the below chart.
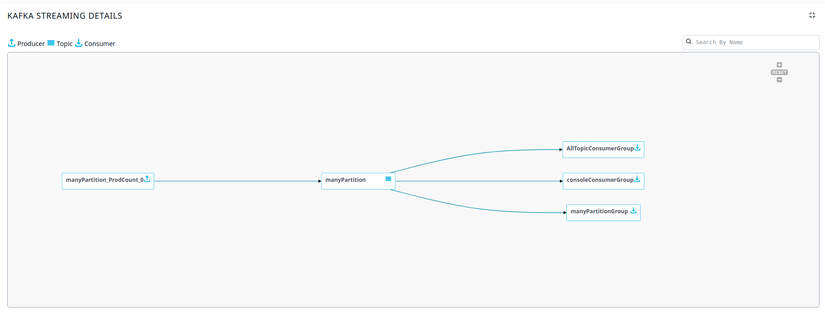
This new visualization that we added to Pulse’s Kafka dashboard helps our customers understand which producers are producing the messages/events to which topics and which consumers are consuming the messages/events from which topics.
For more information about Kafka observability, we encourage you to peruse Acceldata Documentation.







