
























































.svg)



































There are untold blogs and articles about how valuable data is, how it drives the enterprise forward, and how it can be used to make better decisions.
Complex data pipelines criss-cross the enterprise with numerous data consumers along these data pipelines who make assumptions about data, it’s validity, uniqueness and freshness. One can have the most elegant function, model or application — but the outcome is only as good as the input.
Data quality management has never been more important. If you are part of an enterprise that depends on complete, accurate and non-latent data, then this blog is for you. We will briefly cover the multiple dimensions of data quality, which modern enterprises need to ensure.
What is Data Quality?
Before we get into the details about data quality dimensions, let’s define data quality. Two definitions of data quality are as follows:
- Data that correctly describes the real-world or reality is of good quality
- Data that is fit for the use-case can be considered good quality
While data is used to build applications and business use-cases, we make assumptions about data. A forecasting model for a stock expects the last five years of earnings data figures in a particular sequence of related fields.
An anomaly detection algorithm expects time-series data available for the last several weeks. If these assumptions are violated then the following scenarios play out: The code checks inputs against expectations and executes an alternate code path. This could be to warn the user of the issue in advance.
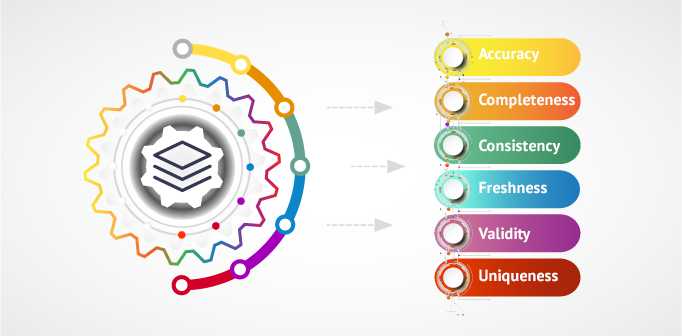
The 6 Dimensions of Data Quality
The code continues on, and produces a result which is likely incorrect, or there’s a crash. Such a crash typically has a cascading effect on downstream systems. In the world of no-SQL, streaming and Big Data, Data quality has tremendous importance. The most important dimensions for defining data quality are as follows. These data quality dimensions are important as we build businesses on data:
- Accuracy — Is the right account balance a dollar or a million dollars?
- Completeness — Does data in question describe the fact completely or is it missing key elements, such as the name of a person?
- Consistency — Is this consistent with the rest of the data points stored elsewhere in the system?
- Freshness — How old is the data element you are working with? Does this reflect the new reality of the business or is it stale already?
- Validity — Does data follow and conform to the schema definition, does it follow business rules, or is it in an unusable format?
- Uniqueness — Is this the only instance in which this information appears in the database?
In order to achieve this, you need to establish checkpoints across your data pipeline. Such checks can prevent data downtime, eliminate data reliability challenges and provide early warnings to contain damages due to falling data quality.
Whether you are working with structured data in tables, or whether you are working with unstructured data in a hybrid data warehouse, managed by a metastore, you should consider setting up a quality program to ensure high quality data assets for everyone. We will define the way in which enterprises can deploy a data quality program in our next blog. In summary, if you are setting up your data quality processes through observability, you should track the following objectives:
- Prevent, pre-empt non-conformance of data schema, continuously validate data and preferably automatically.
- When data errors occur, ensure that the cause of failure is reported along with the error, and possibly with a way to remediate the problem.
- Failure notification without the contextual information is never enough to fix the problem or to prevent it from happening again.
Data Quality Needs Data Reliability
Continue reading about data quality dimensions and how to set up the right level of observability by also ensuring data reliability.







