
























































.svg)




































Service Level Agreements (SLA) are the root canals of the business technology world. Everyone dreads them — the dragged-out meetings, hard-nosed negotiations, and endless SLA contract revisions.
Yet, for organizations that have made major enterprise investments in the cloud, SLAs are required for any area where mission-critical business operations are at the mercy of a technology service.
Enterprises which depend on data to make smarter decisions and boost customer interactions in real or near-real time typically need SLAs to ensure data reliability as part of a data observability platform.
What is Data Reliability?
Data reliability is defined as the dependable, speedy delivery of accurate, complete, usable data to applications and/or their users. In other words, data is reliable when the data is high quality and also travels smoothly through data pipelines on time, and without incident.
When data is unreliable, business executives puzzle over inaccurate results, data scientists need to identify alternate data sets, and data engineers must figure out the sources of bottlenecks or corrupted data.
And data quality management issues can be more difficult to solve now than in days past. That’s because in the modern era, data pipelines are larger, more complex, and more fragile than when data warehouses operated in environments that were less complex.
Outages, corrupted data, and other problems can occur in more places and at a higher rate. Tracing the root causes and fixing issues can be extremely time consuming. That leaves data engineers without time to scale or optimize more strategic data initiatives requested by the lines of business.
Data-driven enterprises cannot afford unreliable data. To eliminate it, they must create binding data reliability SLAs while arming their data engineers with a modern data observability platform that provides the necessary insights to understand how their data operates.
So what should a data reliability SLA include? The following should be considered.
Enterprise Data SLIs and the SLOs
Shakespeare wrote “brevity is the soul of wit.” But the immortal bard wrote plays, not SLAs. A one-page SLA promising five nines of uptime isn’t going to cut it.
A good SLA must be comprehensive. It must clearly define the service level indicators (SLIs) — also referred to as the metrics or key performance indicators (KPIs) — upon which all parties have agreed. For a data reliability SLA, the parties could include:
- The DataOps team — data engineers, data quality engineers, and data architects all led by a Chief Data Officer
- Data scientists led by a Chief Analytics Officer
- Site reliability engineers (SREs) led by the CIO, and
- Business unit leaders there to articulate the high-level business objectives and requirements
Among the operational SLI/KPI metrics would be:
- Minimum data pipeline volumes
- Maximum latency for real-time streaming data
- Data pipeline uptime
The SLA could also include response metrics such as:
- Time to detect bad or unreliable data
- Time to resolve data reliability issues
Agreeing upon these KPIs is a great first step, but KPIs also need to bind the service provider team. So the SLA must also explain how the SLI metrics will be tracked, including which tools or technologies will be employed. This is important, because data governance and observability solutions are not equal.
You need to ensure that your solution can actually track the SLIs you need, as well as ensure that your service level objectives (SLOs) — the targets that the data engineers must meet — are achievable with the available technology. Finally, the compensation or penalties for failed SLOs/SLAs must be agreed upon and spelled out. These could be service reimbursement fees or decreased budgets for the DataOps team.
Creating an SLA will require uncomfortably frank discussions and hard-nosed negotiations between multiple parties. Getting everyone to agree will take time and may result in (temporarily) bruised feelings. But that’s better than the inevitable lack of trust and blame-shifting that will result when problems occur. To avert that, discussions also need to include these topics:
Data Engineering and Data Operations Roles
Business systems are complicated these days. Sometimes a data pipeline breaks or gets bottlenecked because of a problem in the data source. Sometimes it’s a change or an invisible upgrade to the analytics application that causes the breakage. It’s not always clear. What’s clear is that the business isn’t getting the information it needs and it is the job of data engineers and data operations teams to fix them.
The most important role to be designated is a data reliability incident manager. Incident managers are familiar to anyone coming from IT or DevOps. A data reliability incident manager is the same; they lead the troubleshooting response when a bottleneck or data error occurs. Their responsibilities include:
- After insuring the entire data operations team is informed, pulling in stakeholders on the applications performance team and the business end users;
- Figuring out the severity of the data downtime
- Creating and maintaining the record of affected data assets or data pipelines
- Leading the response and assigning tasks
It is good practice to rotate the role of data incident manager among multiple team members. This avoids burnout and educates every data team member on how to handle problems when they arise.
Using the Right Data Tools
As mentioned earlier, the data governance and reliability tools that your business owns can determine what SLIs you can track, and what SLOs are feasible to achieve.
Say that all parties have agreed to use time to detect data reliability problems as a key metric. If your data engineers are using an antiquated data monitoring platform, it may take longer to detect slowdowns in data pipelines or the emergence of bad data.
Also, many older data health monitoring solutions are focused only on scanning data at the point of ingestion. But many data reliability problems emerge after data has been repeatedly aggregated, transformed, and uploaded through data pipelines into analytic applications. Such tools may not be able to detect most data reliability problems.
What’s needed is a modern data observability platform that helps your organization scale its data infrastructure while optimizing for performance, cost and capability, and maintaining high data reliability. To ensure data reliability, the platform must constantly and automatically scan your end-to-end network of data pipelines for data quality degradation such as missing or incorrect data and structural changes such as schema or data drifts. And it must provide one-click recommendations to fix or prevent such problems.
How Can You Ensure Data Reliability?
The Acceldata Data Observability Platform provides a modern solution for data reliability. Part of Acceldata’s Data Observability Platform, the data reliability solution provides continuous, automated monitoring for data reliability that can help you detect and fix issues as soon as they arise, and also predict potential bottlenecks or spot data quality erosion before it causes a data incident and creates distrust for your data with your data scientists and end users.
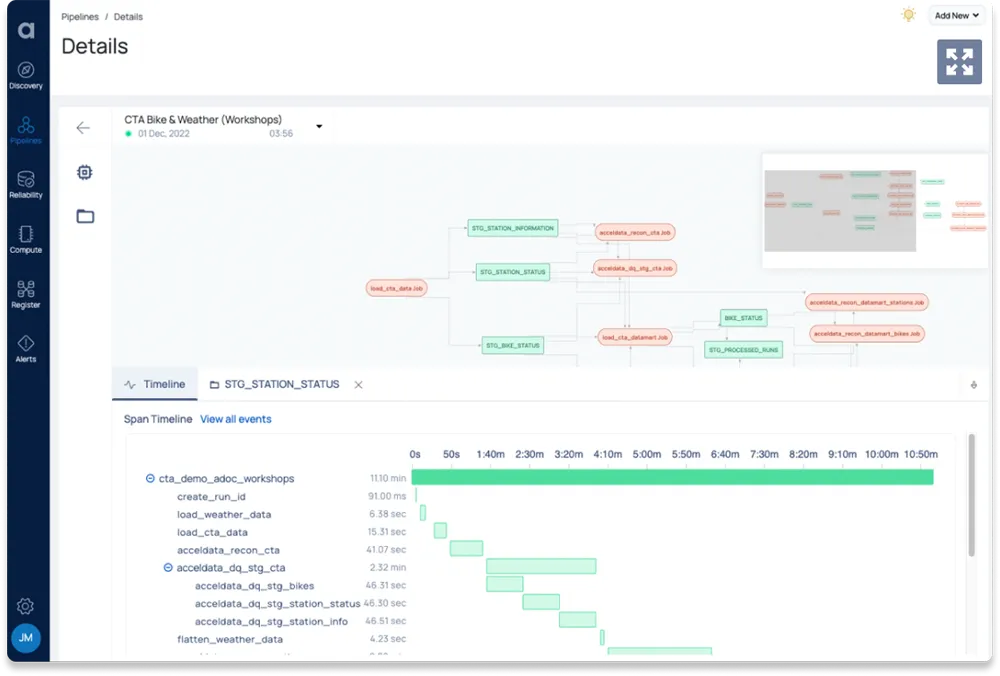
Get a demo of the Acceldata Data Observability Platform and learn see how to ensure data reliability for your environment.
Photo by Aditya Vyas on Unsplash









