
























































.svg)




































Simple application performance monitoring (APM) and uni-dimensional data observability tools cannot deal with the complex and fungible data needs of modern enterprises. They need a comprehensive, multi-layered data observability solution to validate data and derive maximum benefits from their data investments.
“Today, there are more than 50 mainstream data platforms. So, data observability can no longer be a one-size-fits-all solution. There are now multiple dimensions to data observability.”
— Vidya Raman, Principal at Sorenson Ventures
With the right data observability platform, data teams can ensure reliable data, avoid data outages, and manage data pipelines, because this approach is the only way to gain comprehensive visibility into the health and activity of an enterprise’s data pipelines.
Data Observability for Cloud Environments
At it's core, data observability helps enterprises deal with data complexity. It makes the state of your data and data systems that transform your data, more observable, at any point across its time or data lifecycle.
In this context, a multi-layered approach speaks to the ability of a data observability solution to address a wide range of use cases and enable a better understanding of data as complex and multidimensional, as opposed to focusing on one data dimension, such as data quality or data downtime.
Cloud environments need data observability to can help data teams observe and optimize a wide range of complex data systems, technologies, and use cases from a single unified view. It can also help them address multiple data priorities such as quality, security, scalability, and data reliability.
Data Observability Helps Reduce Pipeline Complexity
A cloud data observability solution, such as the Acceldata Data Observability Platform, can help enterprises monitor data pipelines, ensure data quality management, and data systems. This allows enterprise data teams to understand their data at any point, across the data life cycle, from ingestion all the way up to consumption.
Acceldata also integrates with all modern data sources that include Amazon S3, Azure, DataBricks, HDFS, HiIve, Kafka, Oracle, Redshift, Spark, Snowflake, and Tableau.
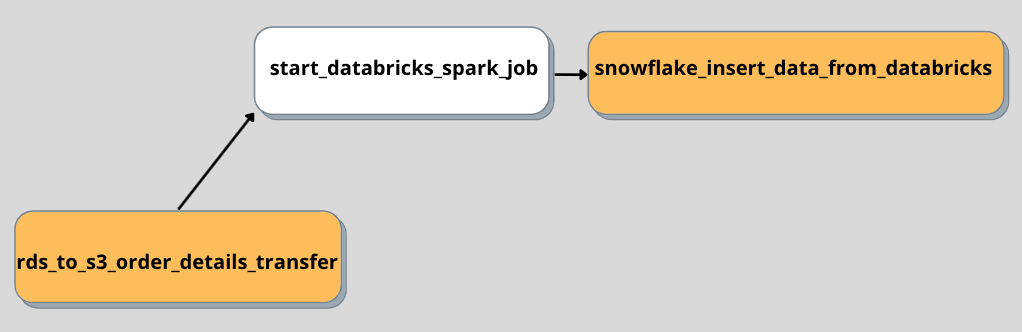
To understand the capabilities of Acceldata, let’s look at a sample data pipeline in Airflow.

To understand what’s actually going on here, let’s break down this image into three parts.

The above image shows how a dataset gets created. And the below image shows how it gets written to RDS locations after a JOIN operation.

And, the below image shows how the data gets transformed, using a Databricks job and how the final data is moved back into a Snowflake repository, ready for consumption.
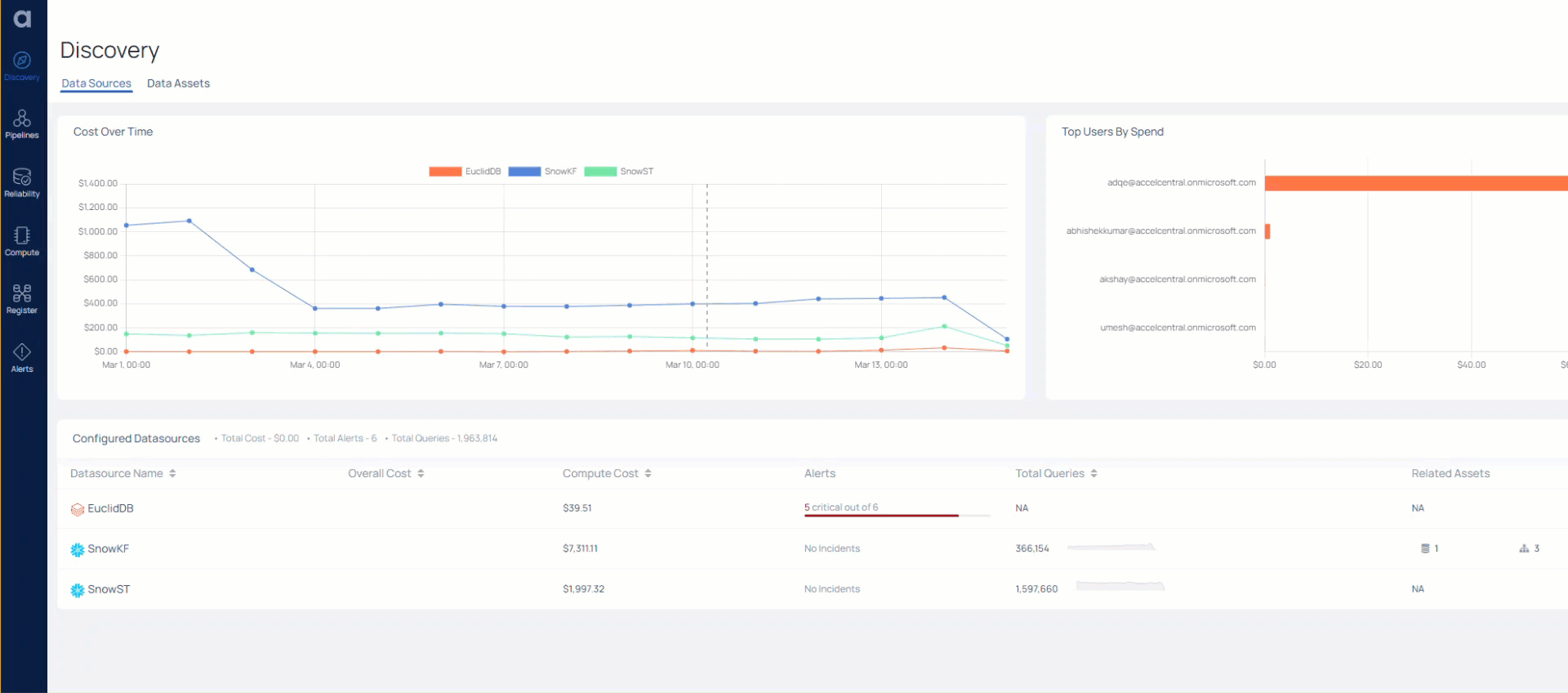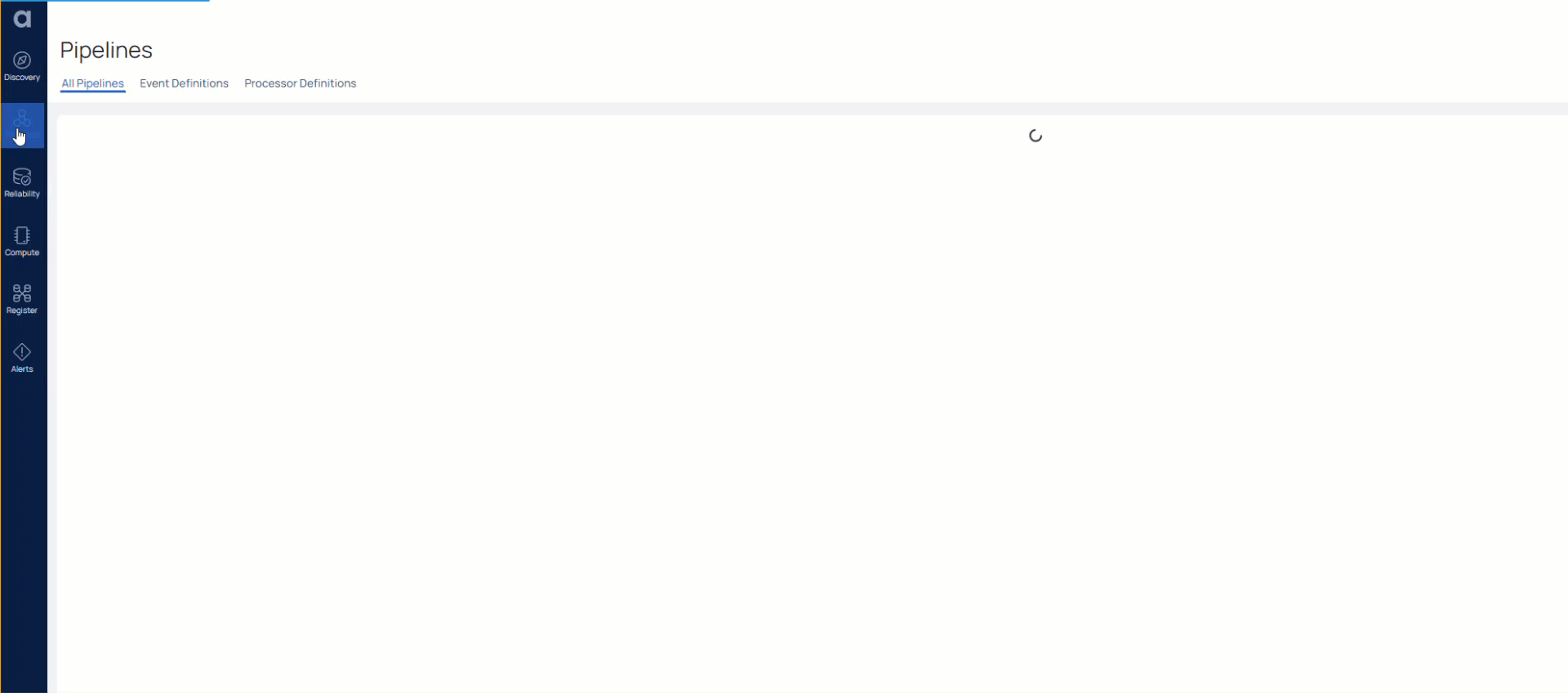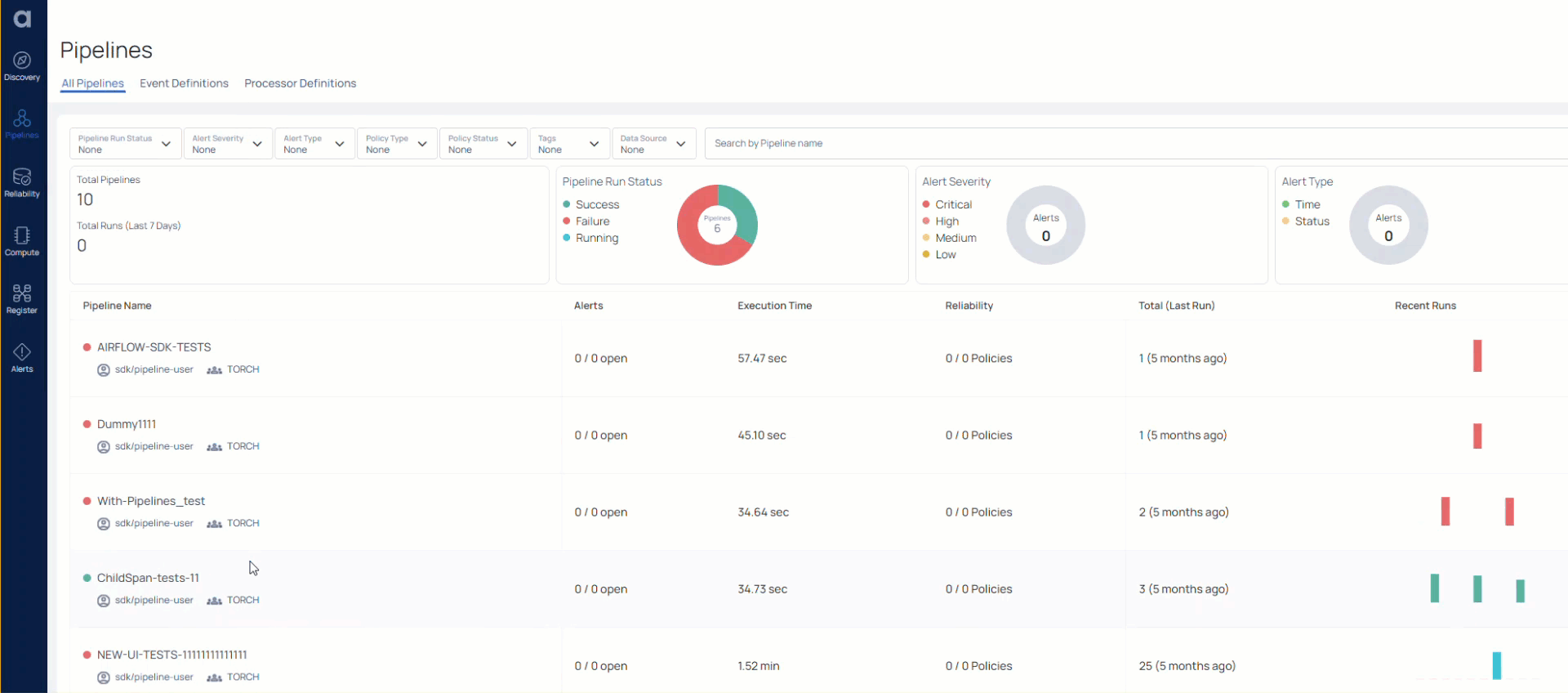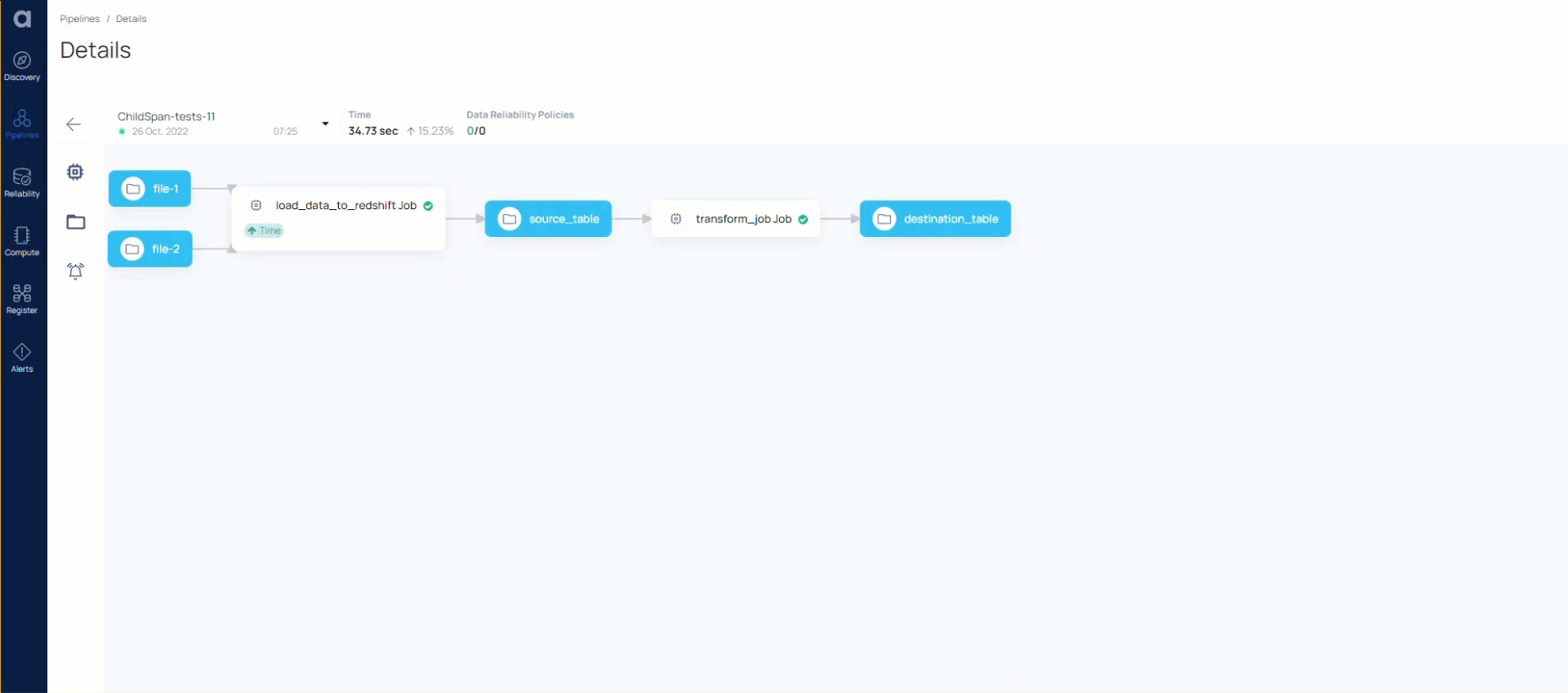
The Acceldata Data Observability Platform helps you look at the same data pipeline, at a deeper level, with a more comprehensive view of all data and data-related operations.

In the above image, the red boxes represent various compute jobs, while the green boxes represent all the various data elements, RDS locations, and data tables that interact with the compute elements.
Acceldata also provides SDK integration. This allows you to go under the hood and log any critical or additional events, that might be needed in production or operations.
In addition to this granular view of how data gets transformed, across various points in the data life cycle, Acceldata also gives you performance information of data pipelines.
For example, it can tell you about the time required to execute a pipeline. Or it can inform you of any errors or warnings.
It also gives you a detailed view of successful as well as unsuccessful runs/ executions/ results of a particular pipeline, across time. This allows you to do a comparative analysis of pipelines and understand why a certain pipeline failed or hasn’t performed too well.

Any complex data pipeline will work with a range of different technologies, so there are several points of potential failures. Acceldata gives developers the ability to look at log events and metadata to investigate any pipeline errors that might have occurred.
It also allows you to go one step further, and explore a particular event in greater operational detail. You can understand what queries were used and how long did a query execution take.

Beyond operational details, Acceldata also allows you to look at the data operations in more granular detail. It helps you answer questions such as:
- When was the data last updated?
- What kind of data or reconciliation policies were configured?
- Are there any data and schema drift warnings to look out for?
In essence, you can ensure that you’re working with data that you want to work with. Because you understand how your data has changed across multiple operations.
But that’s not all. In addition to the features we talked about, Acceldata also provides several other advanced capabilities that include:
- A 360-degree view of all your data elements with relation to quality and your operations
- Automated anomaly detection and recommendations based on our proprietary ML scans
- Ability to understand where a particular piece of data came from and how it transformed
Why Do Enterprises Need Cloud Data Observability?
Enterprises need a data observability solution to improve data pipeline reliability, avoid unexpected data outages and scale data infrastructure.
A data observability solution such as Acceldata can help data teams take a holistic view to monitor and correlate data events across their application, data, and infrastructure layers. Acceldata also can leverage machine learning algorithms, to automatically detect and avoid data-related problems. But most importantly, it enables enterprises to analyze and use their data in real-time.
Enterprises rely on complex data pipelines, but without a unified view of data pipelines, they can be quite fragile and unreliable. Acceldata offers enterprises a unified view of their entire data life cycle, making it more transparent and observable. This helps data teams create effective and robust data pipelines.
Acceldata also integrates with technologies such as HBase, HDFS, Hive, Kafka and Spark - to provide a unified view of all your data systems. This helps enterprises identify bottlenecks, excess overheads, and resource overloads. This translates into improved pipeline reliability, optimizing data infrastructure and lower data handling costs.
"Acceldata’s data observability saved us millions of dollars. They improved our data pipeline reliability, helped us optimize HDFS performance, consolidate Kafka clusters and reduce cost per ad impression.”
— Ashwin Prakash, Data Analytics Lead, PubMatic
Optimize Data Scaling with Data Reliability from Acceldata
Modern enterprises need to scale rapidly. In addition to managing data, pipelines and compute resources, they also need a data observability solution to make data and application layers more observable. This can help enterprises identify root cause problems and build scalable systems that are reliable.
Without a cloud data observability solution, enterprises are flying data-blind and they risk spending millions of dollars on data handling and infrastructure, all of which can be avoided.
This is what happened with PhonePe (Walmart subsidiary), a startup that provides instant payment systems to more than 350 million customers across India. Acceldata helped PhonePe implement the Acceldata Data Observability Platform, our compute performance processing and reliability solution, and within a day, began to identify anomalies within their environment.
Over the next 18 months, Acceldata helped PhonePe scale its data infrastructure by 2,000%. But more importantly, even during this period of hyper-growth, PhonePe used Acceldata to save $5MM in annual data handling costs while maintaining over 99.97% availability across its Hadoop infrastructure.
"Acceldata supports our hyper-growth and helps us manage one of the world’s largest instant payment systems. PhonePe’s biggest-ever data infra initiative would never have been possible without Acceldata.”
— Burzin Engineer, Founder & Chief Reliability Officer, PhonePe (a Walmart subsidiary)
Get a demo of the Acceldata Data Observability Platform and learn how to scale and optimize your enterprise data efforts.
Photo by Daniele Levis Pelusi on Unsplash








.webp)
.webp)



