
























































.svg)



































.png)
Data teams need to focus on effectively managing data sources in their data environment to ensure data quality, accessibility, and reliability. With a disciplined approach to implementation, management, and continuous optimization of cloud data sources, teams can establish standardized processes for data ingestion, integration, and transformation, ensuring consistency and accuracy of data.
Modern data environments adhere to rigorous SLAs and policies as a way to reduce complexity and streamline data operations. But meeting those SLAs when new data sources are constantly being added is challenging at any time, but especially when it needs to be done at scale for an ever-growing number of sources.
Data observability provides the necessary framework for management of data sources because it provides real-time visibility into the health, performance, and quality of data pipelines and sources. It enables data teams to proactively monitor and detect anomalies, errors, and bottlenecks in data ingestion and processing.
With data observability, teams can ensure the reliability, accuracy, and timeliness of data, identify and resolve issues promptly, and maintain the overall integrity of the data environment.
Managing a Diverse Set of Data Sources
The emergence of diverse and complex data sources leads to a richer data experience for enterprises. In today's complex and evolving data landscape, data comes in various formats, structures, and from multiple sources such as social media, IoT devices, external APIs, and others. These new data sources hold immense potential for generating valuable insights, but organizations must navigate the operational aspects of incorporating them effectively into their workflows and must maintain performance and reliability benchmarks.
Data engineering teams are typically equipped to manage the diversity of data sources and their associated data formats, even though it can be complex, requiring data teams to implement data integration mechanisms that can handle the various types of data efficiently. Ensuring data quality and reliability from these sources may pose challenges, as different sources may have varying levels of accuracy, completeness, and consistency. Additionally, data teams must have a way to manage privacy, security, and compliance concerns when dealing with data from external sources.
Data teams require data observability when incorporating new data sources into their data environment because it ensures the assurance of data quality. It allows these teams to closely monitor the data pipelines associated with the new sources, enabling data validation checks and the identification of any anomalies or inconsistencies. By implementing observability, the team can rapidly detect and address any issues that may arise with the newly added data sources, thus maintaining a high overall quality of data.
The usage of data observability also facilitates performance monitoring. As new data sources are integrated, all of that data has to immediately be monitored for data pipeline performance and reliability. Observability enables data engineers to track key metrics such as data latency, throughput, and processing times. By monitoring these metrics, the team can identify bottlenecks or performance issues that could impact the smooth flow of data. This, in turn, allows them to optimize the pipelines, ensuring better efficiency and responsiveness.
Using Data Observability to Align Data Sources and SLAs
Data sources abide by SLAs and policies that govern how data is treated and transacted. Data observability plays a crucial role in aligning Service Level Agreements (SLAs) with new data sources by providing real-time monitoring and analysis capabilities. Through continuous monitoring, organizations can track the performance, quality, and reliability of data from these sources. Real-time analysis allows them to identify any deviations or anomalies, enabling proactive measures to be taken to ensure adherence to SLAs.
Identifying and addressing gaps in SLAs for new data sources is another important aspect of data observability. By closely monitoring data from these sources, organizations can compare the actual performance against defined SLAs. Any gaps or discrepancies can be quickly identified and addressed. This may involve optimizing data pipelines, improving data quality processes, or enhancing infrastructure to meet the SLA requirements.
The Acceldata Data Observability Cloud (ADOC), for example, enables organizations to identify trends and patterns in the data from new sources, allowing them to make informed adjustments to SLAs. By analyzing the behavior and characteristics of these sources, organizations can refine SLAs to account for variations in data volume, velocity, or quality.
This level of comprehensive data observability empowers organizations to establish feedback loops between data teams and stakeholders. This enables continuous communication and collaboration to align SLAs with evolving data sources. Regular evaluations and feedback on the performance of new data sources help organizations make necessary adjustments to SLAs and ensure ongoing alignment.
The challenge, however, is to establish and maintain consistency across all your data sources. At the same time, data environments don’t adhere to simple, binary approaches, so data teams also need the flexibility to make changes to policies where appropriate, for the required time, and at scale. ADOC includes the capabilities required for data teams to continuously monitor your data environment to detect issues where data activity doesn’t adhere to SLAs and policies. It also allows data teams to rapidly change SLAs when needed.
Managing Data Sources in Acceldata
ADOC provides continuous monitoring of your cloud environment to ensure its uninterrupted operation through two key features: Data Reliability and Data Compute. Data teams can assess the data quality within an environment, track infrastructure costs, and monitor other essential requirements. It empowers you to set thresholds for critical components of your environment and receive timely alerts when those thresholds are met or exceeded. ADOC offers comprehensive monitoring and management capabilities to optimize the performance and stability of your cloud environment.
The Data Reliability capability in Acceldata ensures the presence of high-quality data in your systems. It enables you to establish policies that align with your organization's requirements, allowing you to maintain data integrity and certify assets, among other functionalities.
On the other hand, the operational intelligence that comes from Acceldata’s Compute and Infrastructure functionality provides a visual representation of data from your Data Source. It offers a graphical view of various critical metrics pertaining to your environment. Alerts can be configured on crucial metrics, triggering incidents when these metrics exceed defined thresholds.
It's important to note that the availability of Data Reliability and Compute capabilities may vary across different Data Sources. Some Data Sources support both capabilities, while others may only support one. ADOC currently supports multiple Data Sources, each with its corresponding set of capabilities.
The following table provides an overview of the data sources currently supported by ADOC and the associated capabilities for each source:
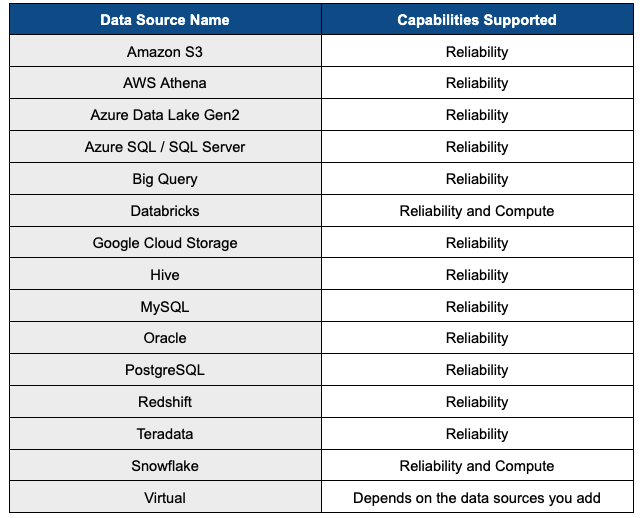
This table outlines the compatibility of each Data Source with the Data Reliability and Compute capabilities provided by ADOC, helping you understand the specific functionalities available for each supported source.
Adding Data Sources in Acceldata
To integrate and set up data sources in ADOC, you can easily add and configure them. Once a data source is configured, ADOC ensures continuous monitoring and provides comprehensive insights into your data source usage and other relevant information.
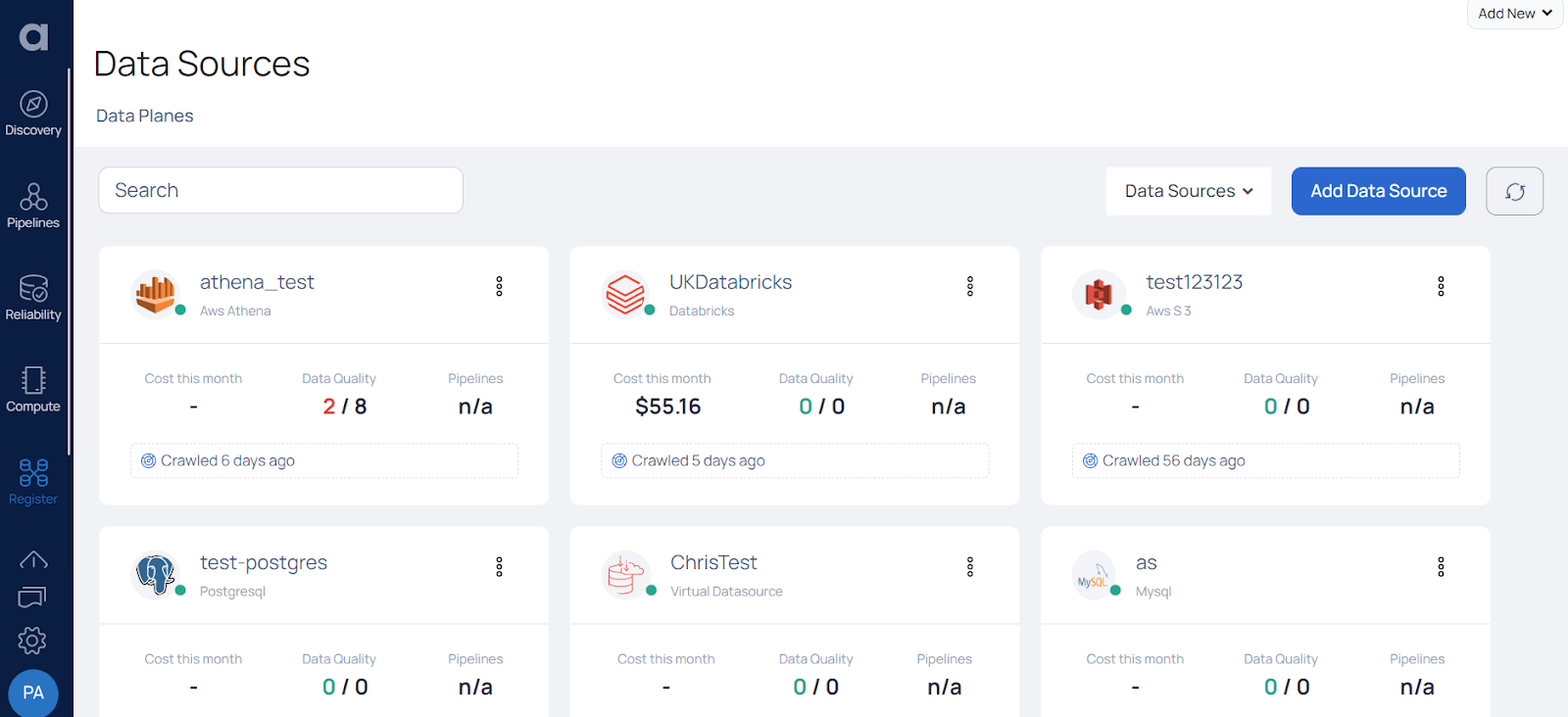
ADOC allows you to create multiple instances of the same Data Source. For instance, if you have three Snowflake accounts, you can create three separate instances of the Snowflake Data Source, each representing a specific account. This allows for clear organization and management of multiple data sources, as illustrated in the accompanying image.
As for ease of set-up, it doesn’t get much simpler than this:
- Click on the Data Sources tab
- Click Add Data Source. The Select the Data Source type wizard is displayed
- Select a Data Source
NOTE: In the notes provided below, are links to documentation for specific data sources.
Additionally, you can easily filter data sources to get as comprehensive or narrow a view as you need. Applying filters is also simple and fast, as you can see:
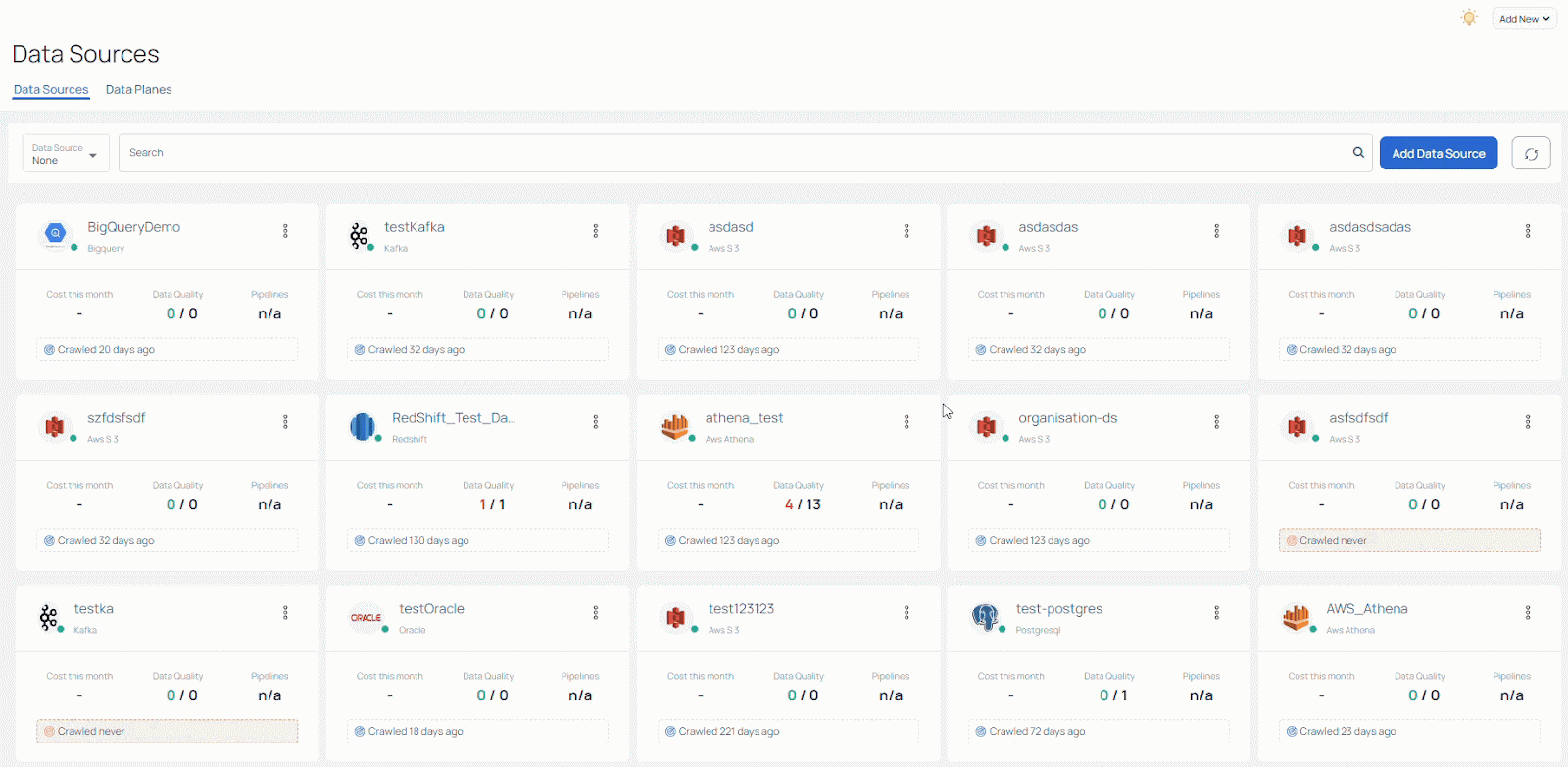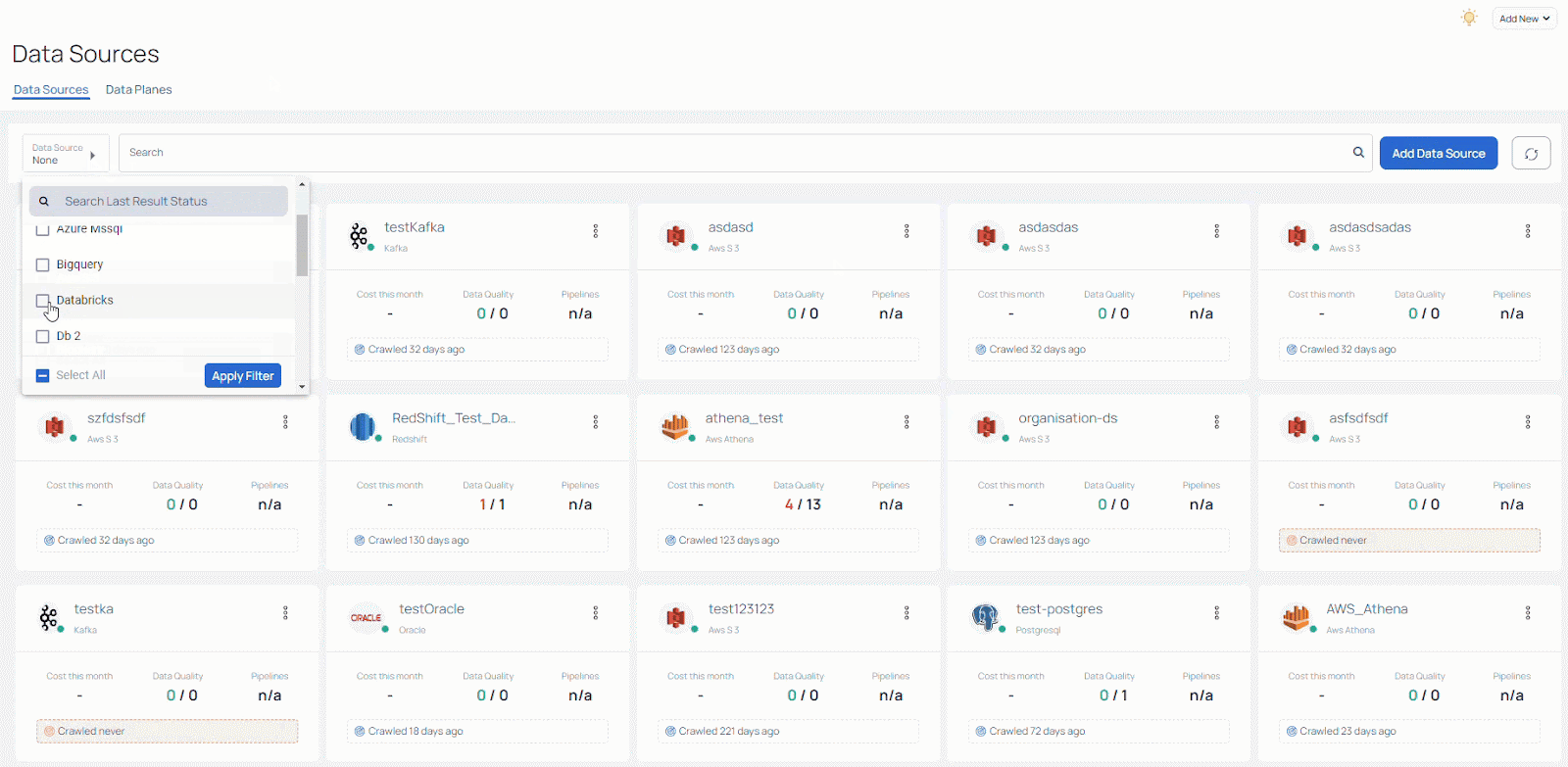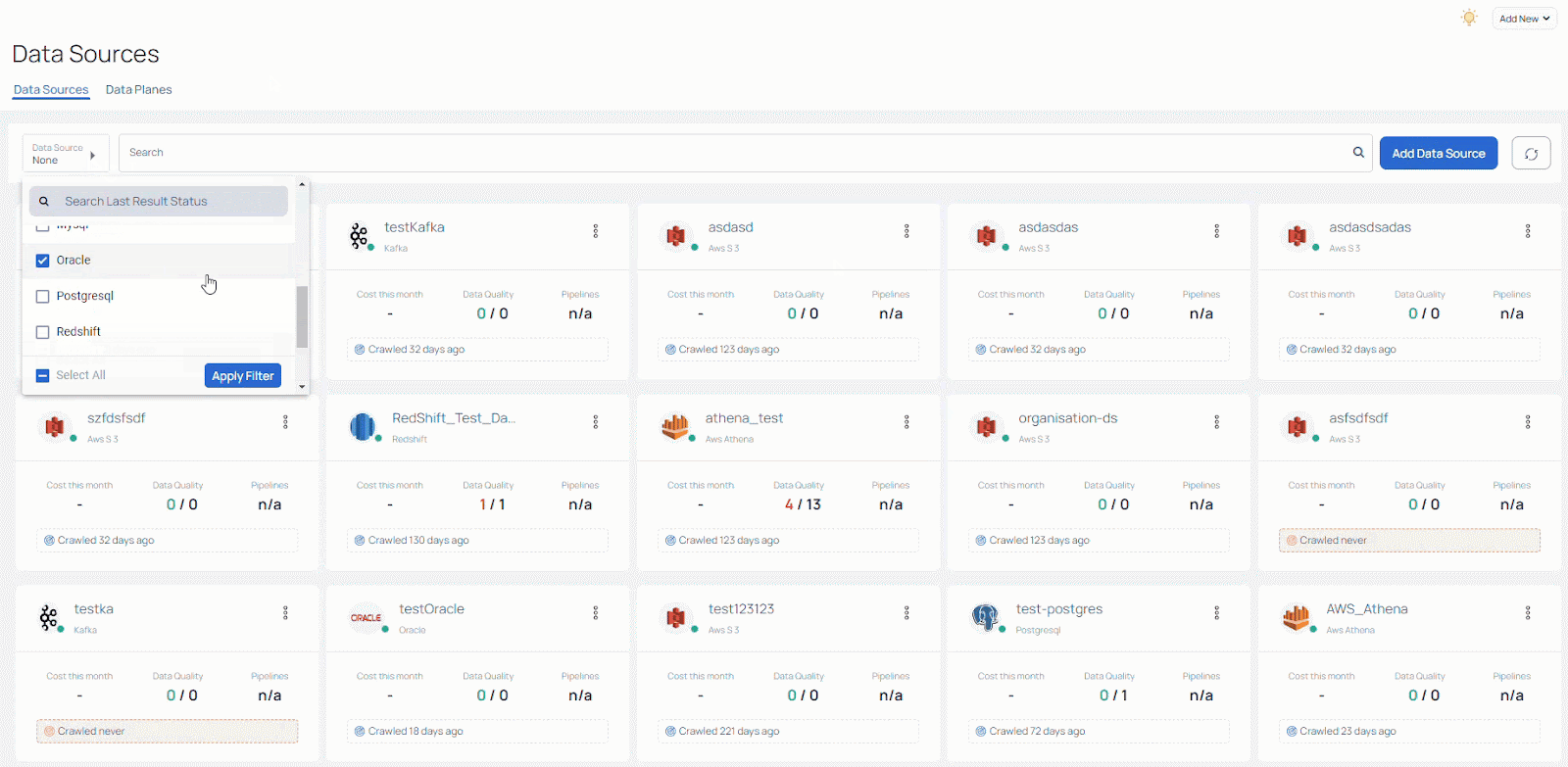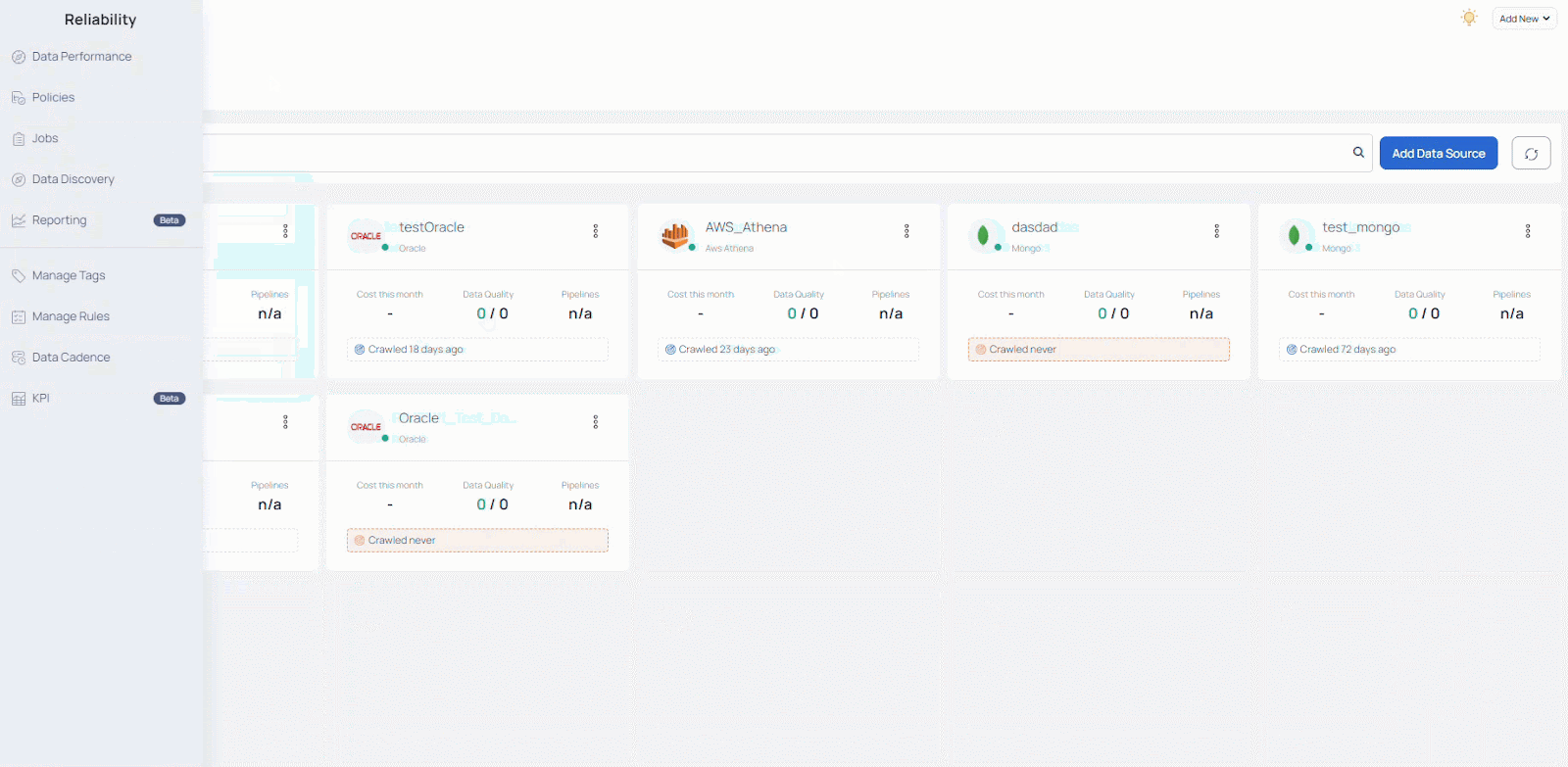
Acceldata also provides functionality to manage all aspects of your data sources that have been added to ADOC. These include the following (details are available for all of these in our documentation):
Editing configurations: this includes identifying specific workspaces within your Databricks environment, which you can see here:

Crawling data sources: by utilizing the Start Crawler option (as you can see in the image below), you initiate the crawling process on your data source which provides insights into the schema of the asset, the basis of which is used for implementing schema checks (which is the backbone of setting up profiling and data quality policies). It provides a way to catalog data sources for use in the platform.
To review the status of the crawl activity, simply click on the Data Source card. This action allows you to verify the date of the last crawl. In the event that you haven't initiated a crawl for a specific Data Source since adding it to ADOC, you will see a message indicating that it has never been crawled.
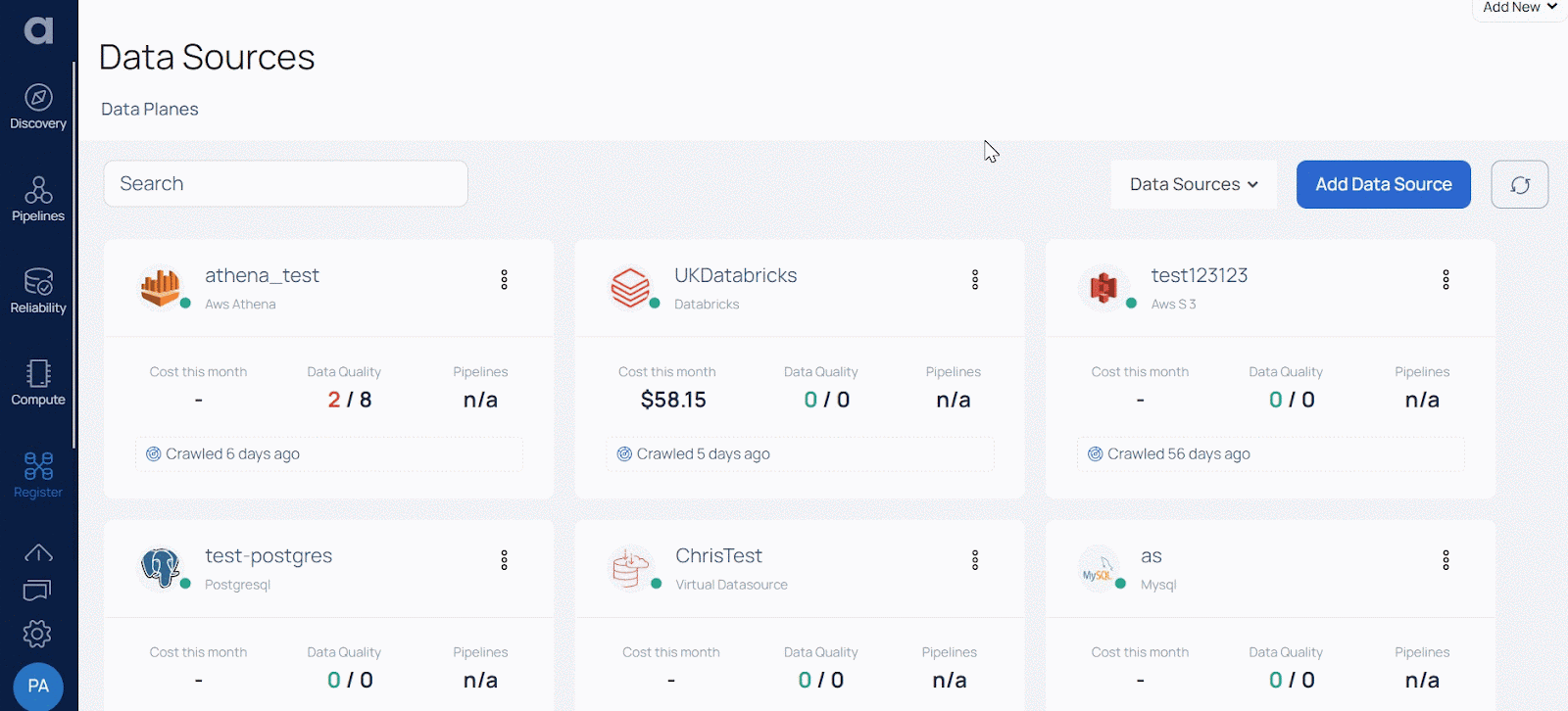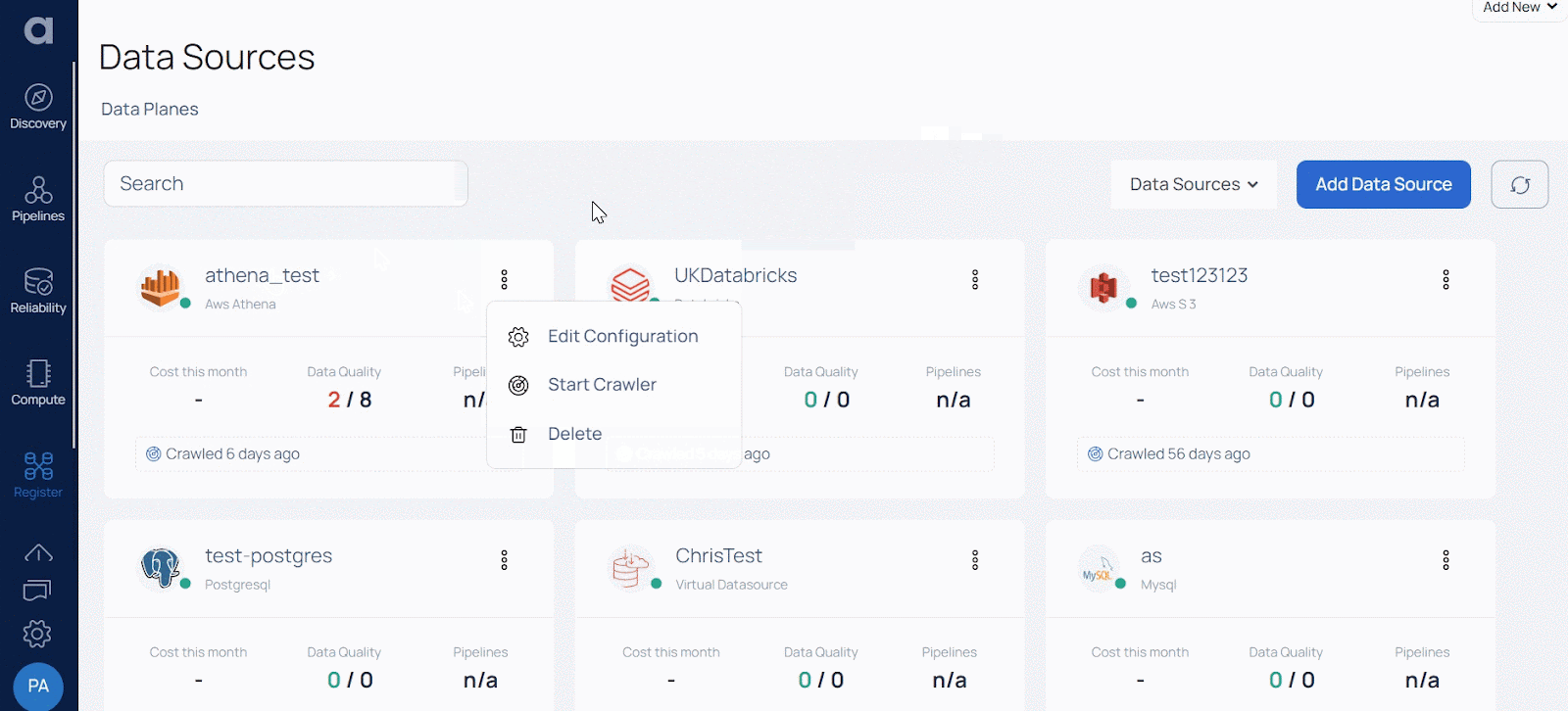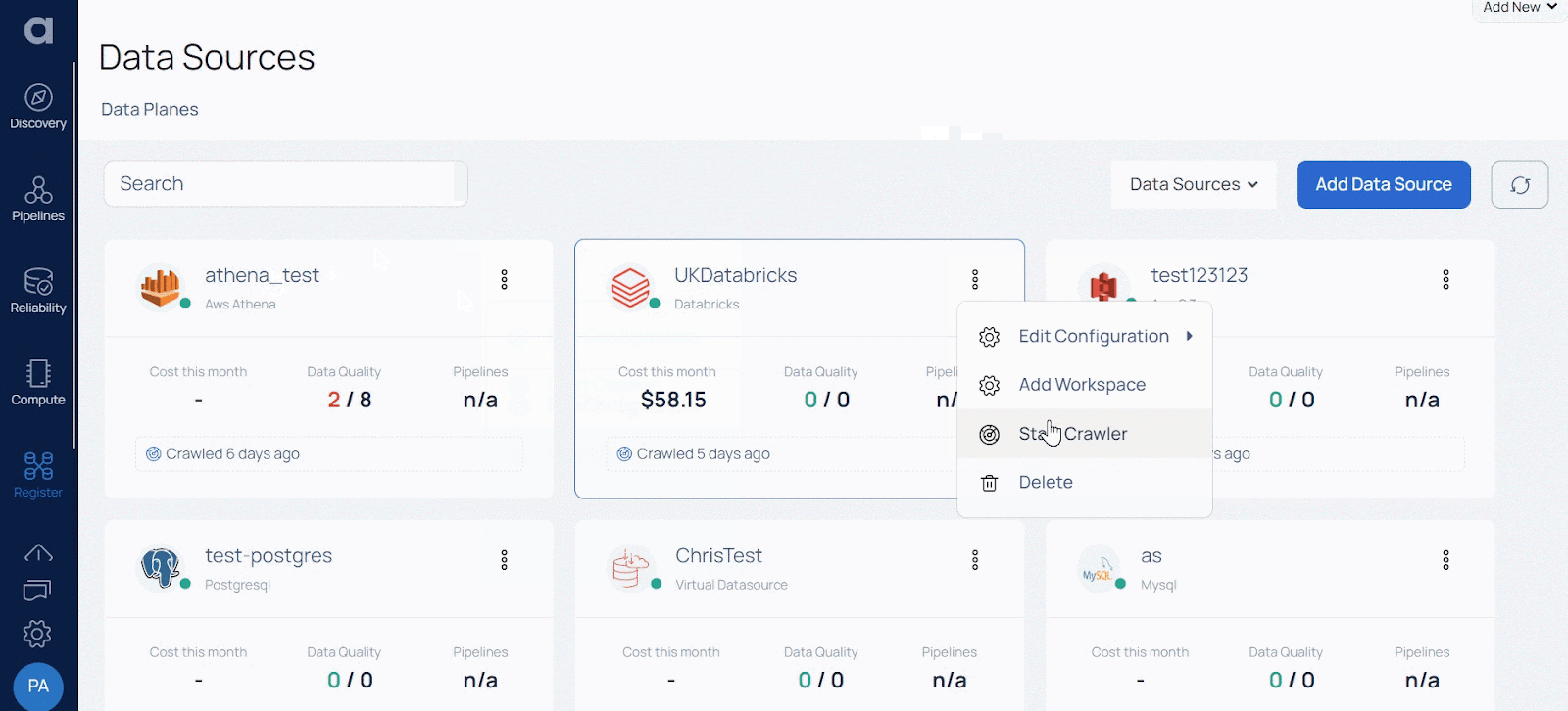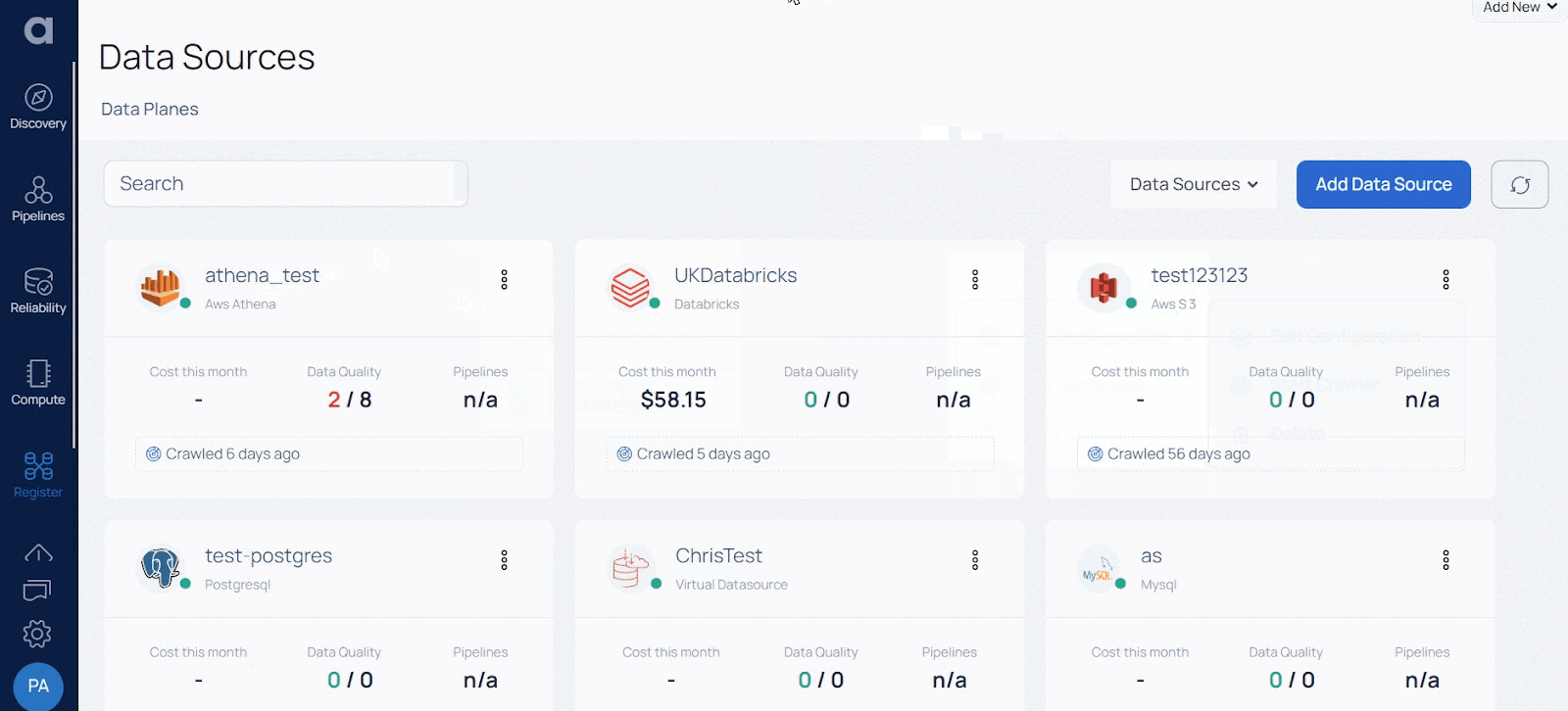
Service monitoring for data sources: starting from version 2.7.0, you have the ability to access the real-time logs generated by the analysis service operating on the dataplane side. This feature allows you to conveniently view the ongoing logs for data sources that are produced by the crawlers. With this enhanced functionality, you gain valuable insights into the operational status and activities of the analysis service and data source crawlers.
Photo by Krissia Cruz on Unsplash









