
























































.svg)




































Data flows through modern businesses like electricity—essential, constant, and potentially dangerous when uncontrolled. Yet, 25% of organizations lose over $5 million annually to poor data quality, with 7% losing more than $25 million.
The result? Data scientists spend a staggering 80% of their time wrestling with messy data instead of uncovering valuable insights. This is akin to trying to build a skyscraper on quicksand. Enter data modeling: the architectural blueprint that transforms chaotic information into a structured, efficient, and reliable foundation.
From entity-relationship diagrams to normalization and schema design, this article explores the essential blueprint for building high-performance databases that transform raw data into business intelligence.
What is Data Modeling?
Data modeling is the process of structuring and organizing data within a database to ensure accuracy, consistency, and efficiency. It defines how data is stored, accessed, and related, providing a clear blueprint for database design and management.
Why data modeling?
- Prevents duplication and inconsistencies, ensuring data integrity.
- Optimizes query performance by defining structured relationships.
- Strengthens data governance, maintaining consistency across applications.
- Simplifies complex data relationships using entity-relationship diagrams (ERDs).
- Enhances scalability by enforcing well-defined schema design principles.
A well-modeled database reduces inefficiencies, improves data reliability, and supports seamless business operations.
Types of Data Models
Just as architects move from rough sketches to detailed blueprints before construction, database design evolves through stages of growing precision and detail before implementation.
Data modeling employs three distinct levels of abstraction: conceptual, logical, and physical. Each builds upon the previous stage to transform business requirements into a fully operational database.
These levels serve as a bridge between business vision and technical implementation. Each layer adds specificity while maintaining alignment with business goals.
The following progression illustrates the shift from high-level concepts to concrete database implementation:
Data Modeling Process
Building an effective database starts with structured data modeling. Let's apply this process to an online bookstore that manages customers, book inventory, and orders.
- Identify entities: Map out key objects that the business interacts with. The bookstore needs customers, books, orders, and payments as core entities.
- Establish relationships: Map how entities connect to each other. A customer can place multiple orders, but each order links to a single customer, creating a one-to-many relationship. Similarly, an order can contain multiple books, and each book can appear in many different orders, forming a many-to-many relationship.
- Define attributes: Specify properties for each entity. The customers' entity includes attributes such as customer_id, name, and email. The books' entity contains attributes such as book_id, title, author, and price.
- Normalize data: Structure data to reduce redundancy and improve efficiency. Instead of storing book details in every order, create a separate books table and link orders to books through a book_id reference. This prevents data duplication and optimizes storage.
- Validate and optimize: Evaluate the model to ensure it meets business requirements and operates efficiently. Add indexes to frequently queried fields such as book titles and customer emails. Implement foreign key constraints to maintain data integrity across relationships.
This structured approach ensures the bookstore's database remains scalable, efficient, and easy to query, thus supporting seamless customer transactions and inventory management.
Data Normalization: Ensuring Efficient Data Storage
Poorly structured databases quickly become bloated, inconsistent, and inefficient. Consider an online electronics retailer tracking thousands of orders daily. Storing customer details and product information in each order record leads to significant redundancy, inefficient storage use, and slower query performance.
Normalization addresses these issues by organizing data into efficient, non-redundant tables while preserving relationships between them.
Key Normal Forms (NF)
- First Normal Form (1NF) – Eliminates duplicate columns and ensures each column contains atomic (indivisible) values.
- The retailer ensures that a product list in an order is split into separate rows instead of being stored as a comma-separated list.
- Second Normal Form (2NF) – Ensures every non-key attribute depends entirely on the primary key, eliminating partial dependencies.
- Instead of storing customer addresses in the orders table, the retailer moves this information to a separate customers table, linking it with a customer ID.
- Third Normal Form (3NF) – Removes transitive dependencies, ensuring non-key attributes do not depend on other non-key attributes.
- If supplier details are included in the products table, they are moved to a separate suppliers table, avoiding unnecessary dependencies.
Example: Normalization in action
Unnormalized table (Redundant and inefficient)
3NF optimized tables (Efficient and scalable)
Orders table
Customers table
Products table
This structured approach minimizes redundancy, reduces storage costs, and ensures faster queries as the business grows.
Entity-Relationship Diagrams (ERDs): Visualizing Data Relationships
Entity-relationship diagrams serve as visual blueprints of database structure. They map how data interacts, helping architects and developers design, scale, and optimize databases effectively.
Let's explore this through a food delivery system similar to DoorDash, which manages customers, restaurants, orders, and delivery drivers.
Core components
1. Entities
- Customers, restaurants, orders, drivers, and menu items
2. Attributes
- Customers: Customer ID, name, email
- Restaurants: Restaurant ID, name, location
- Orders: Order ID, status, timestamp
- Drivers: Driver ID, name, vehicle
- Menu Items: Item ID, name, price
3. Relationships
- A customer places multiple orders, but each order belongs to one customer
- An order contains multiple menu items, and menu items can be part of multiple orders
- A driver delivers multiple orders, but each order is assigned to one driver
- Each restaurant offers multiple menu items
Here's how the entity-relationship diagram would look like:
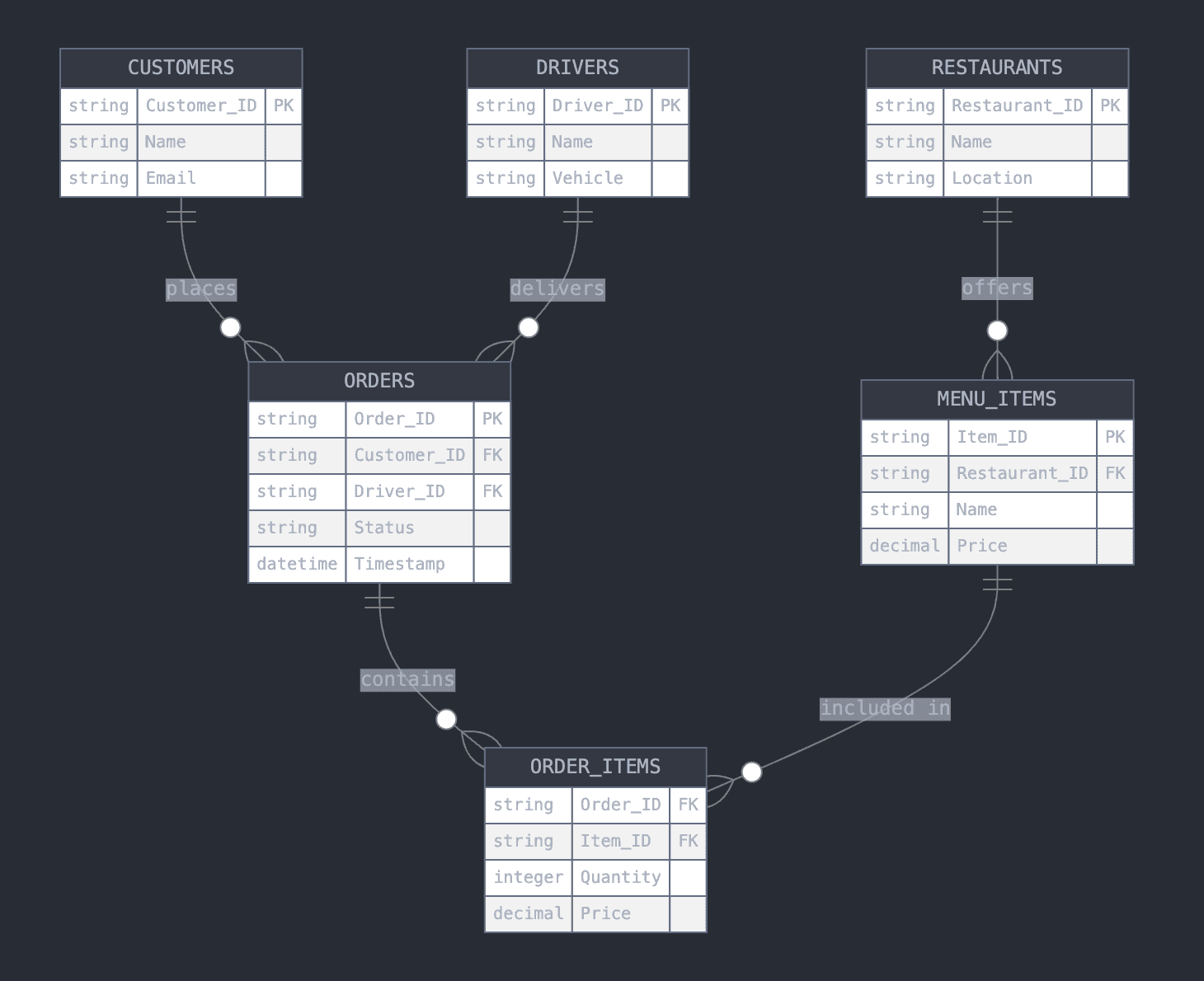
This structure enables efficient order tracking, menu updates, and delivery logistics while maintaining data integrity and scalability. ERD ensures clear relationships between all components, creating a foundation for seamless operation as the platform grows.
Data Modeling Techniques
Different businesses adopt different approaches to structure their data. A bank processing millions of daily transactions has vastly different needs than a retail company analyzing historical sales trends.
The right data modeling technique ensures optimal performance for each specific use case.
Key data modeling techniques
1. Hierarchical model
- Organizes data in a tree-like structure with parent-child relationships
- Ideal for applications where data follows a strict hierarchy
- American Airlines uses this model in IBM's IMS database for reservation systems, managing passenger and flight records.
2. Relational model
- Uses tables and optimizes SQL to enforce strict relationships between data points
- Ideal for applications requiring ACID compliance and structured queries
- Powers MySQL at Airbnb, managing customer bookings, payments, and property listings.
3. Object-oriented model
- Stores data as objects rather than rows and columns
- Well-suited for complex relationships and JSON-like or unstructured data
- Uber implements this model with MongoDB to store rider-driver data for faster matching.
4. Dimensional model
- Optimized for analytics in data warehouses
- Applies denormalization of tables to improve query performance in reporting systems
- Netflix employs this model with Snowflake to analyze user engagement and enhance content recommendations.
Each model serves specific business needs, from transaction processing to analytics, ensuring data is structured optimally for its intended use.
Challenges in Data Modeling
Well-structured databases can face performance bottlenecks, scalability issues, and inconsistencies. Addressing these challenges early ensures data models remain efficient and manageable as business needs evolve.
By anticipating these challenges and implementing appropriate solutions, businesses can ensure their data models remain robust, scalable, and easy to maintain.
Best Practices in Data Modeling
A well-designed data model reduces redundancy, improves query performance, and ensures long-term scalability. Here are five key practices that leading companies use to build high-performance databases:
- Balance normalization: Follow the Third Normal Form (3NF) but apply denormalization selectively for performance optimization. Amazon uses denormalization in its product catalog data to accelerate search and recommendation queries.
- Plan for growth: Design with indexing, partitioning, and optimized query strategies from the outset to ensure efficient performance. Facebook partitions user databases by region for efficient scaling of its global user base.
- Establish data standards: Implement consistent naming conventions, data types, and indexing strategies. JPMorgan Chase maintains strict data governance for financial transaction consistency.
- Document everything: Maintain current ER diagrams, schema definitions, and metadata catalogs. Netflix uses automated schema documentation to track changes across engineering teams.
- Leverage automation: Use modern tools for database design and maintenance. Spotify uses ScienceBox Cloud, an internal platform that enables data scientists to efficiently analyze large datasets using cloud-based JupyterLab notebooks, accelerating insights and improving collaboration across teams.
Following these practices helps companies build databases that remain scalable and efficient as business needs evolve.
From Chaos to Clarity: Power of Data Modeling with Acceldata
Effective data modeling is the foundation of scalable, high-performance databases.
Businesses can optimize storage, accelerate queries, and enable reliable decision-making by structuring data through conceptual, logical, and physical models. Efficient normalization and the use of entity-relationship diagrams further enhance data management.
Without a well-designed schema, companies risk redundant data, slow performance, and scalability bottlenecks—challenges that can impede growth in an increasingly data-dependent ecosystem.
This is where Acceldata steps in.
Acceldata's data observability platform directly addresses these core data modeling challenges. It monitors schema changes, identifies normalization issues, and alerts teams to potential performance bottlenecks before they impact business operations.
Through automated documentation, governance tools, and real-time performance analytics, Acceldata helps enterprises:
- Maintain optimal database structure across growing data volumes
- Ensure consistent data modeling practices across teams
- Identify and resolve schema inefficiencies proactively
- Track and optimize query performance
- Automate data governance and documentation
Ready to build resilient, high-performing databases? Book a demo with Acceldata today to optimize your data modeling and management.









