
























































.svg)




































In the era of big data, efficient data management and query performance are critical for organizations that want to get the best operational performance from their data investments. Snowflake, a cloud-based data platform, has gained immense popularity for providing enterprises with an efficient way of handling big data tables and reducing complexity in data environments. Big data tables are characterized by their immense size, constantly increasing data sets, and the challenges that come with managing and analyzing vast volumes of information.
With data pouring in at high volume from various sources in diverse formats, ensuring data reliability and quality is increasingly challenging, but also critical. Extracting valuable insights from this diverse and dynamic data necessitates scalable infrastructure, powerful analytics tools, and a vigilant focus on security and privacy. Despite the complexities, big data tables offer immense potential for informed decision-making and innovation, making it essential for organizations to understand and address the unique characteristics of these data repositories to harness their full capabilities effectively.
To achieve optimal performance, Snowflake leverages several essential concepts that are instrumental in handling and processing big data efficiently. One is data pruning, which plays a vital role by eliminating irrelevant data during query execution, leading to faster response times by reducing the amount of data that is scanned. Simultaneously, Snowflake's micro-partitions, small immutable segments typically 16 MB in size, allow for seamless scalability and efficient distribution across nodes.
Micro-partitioning is an important differentiator for Snowflake. This innovative technique combines the advantages of static partitioning while avoiding its limitations, resulting in additional significant benefits. The beauty of Snowflake's architecture lies in its scalable, multi-cluster virtual warehouse technology, which automates the maintenance of micro-partitions. This process ensures efficient and automatic execution of re-clustering in the background, eliminating the need for manual creation, sizing, or resizing of virtual warehouses. The compute service actively monitors the clustering quality of all registered clustered tables and systematically performs clustering on the least clustered micro-partitions until reaching an optimal clustering depth. This seamless process optimizes data storage and retrieval, enhancing overall performance and user experience.
How Micro-partitioning Improves Data Storage and Processing
This design enhances data storage and processing efficiency further improving query performance. Additionally, Snowflake's clustering feature enables users to define clustering keys, arranging data within micro-partitions based on similarities. By colocating data with similar values for clustering keys, Snowflake minimizes data scans during queries, resulting in optimized performance. Together, these key concepts empower Snowflake to deliver unparalleled efficiency and performance in managing big data workloads.
Inadequate table layouts can result in long-running queries, increased costs due to higher data scans, and diminished overall performance. It is crucial to tackle this challenge to fully harness the capabilities of Snowflake and maximize its potential. One major challenge in big data table management is the data ingestion team's lack of awareness regarding consumption workloads, leading to various issues that negatively impact system performance and cost-effectiveness. Long-running queries are a significant consequence, causing delays in delivering critical insights, especially in time-sensitive applications where real-time data analysis is vital for decision-making. Moreover, the team's unawareness can lead to increased operational costs as inefficient table layouts consume more computational resources and storage, straining the organization's budget over time.
Optimize Snowflake Performance
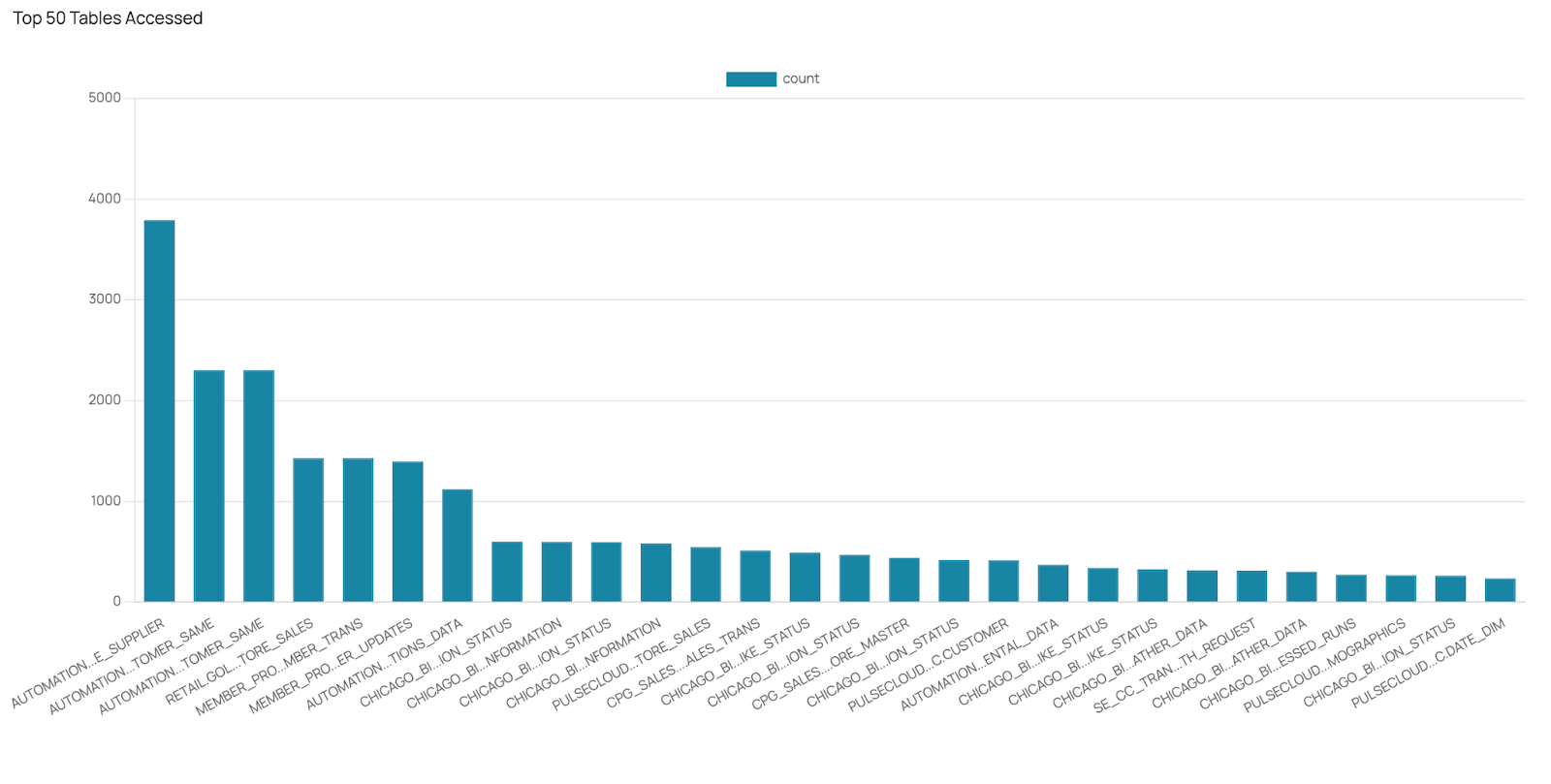
The first step in optimizing Snowflake performance is to analyze consumption workloads thoroughly. Acceldata’s Data Observability Cloud (ADOC) platform analyzes such historical workloads and provides table level insights at the size, access, partitioning and clustering level.
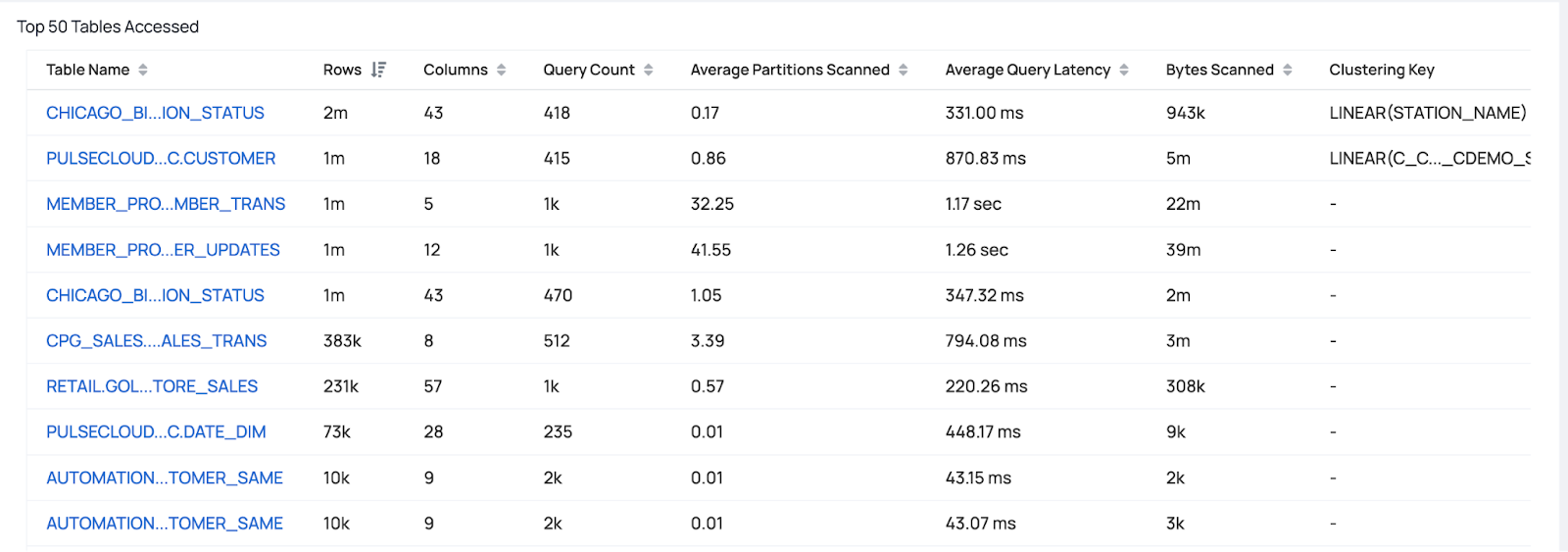
Understanding the queries executed most frequently and the filtering patterns applied can provide valuable insights. Focus on tables that are large and frequently accessed, as they have the most significant impact on overall performance.
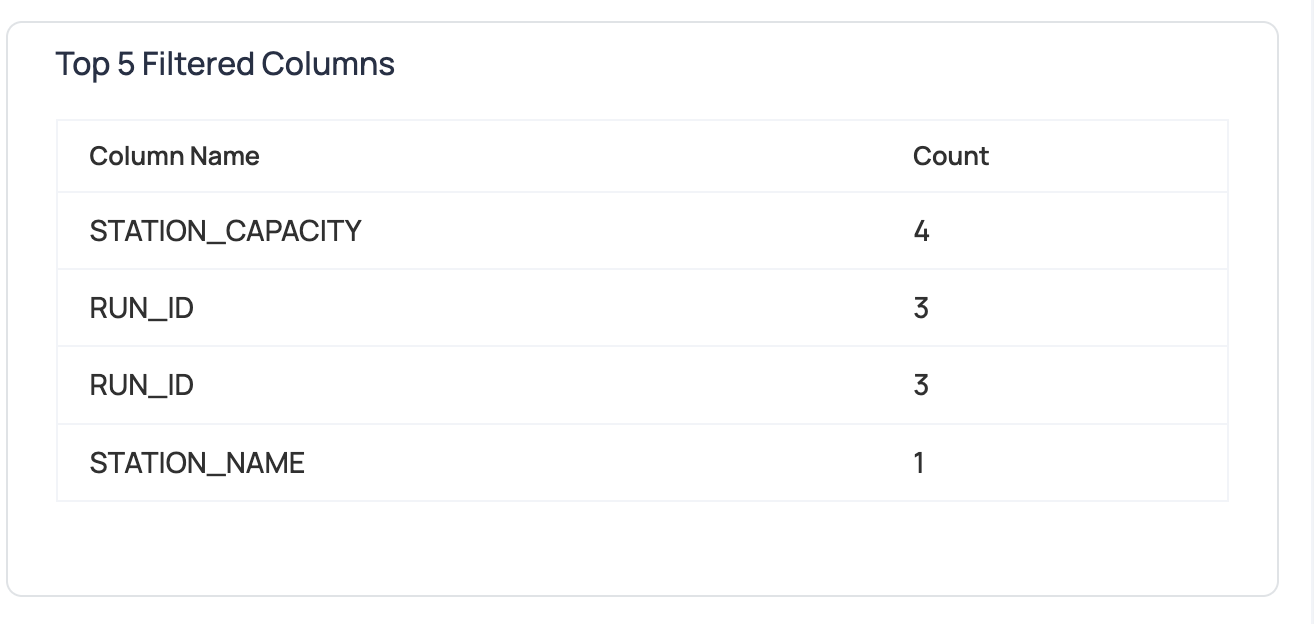
ADOC’s advanced query parsing technology has the ability to detect the columns that are accessed via WHERE or JOIN clauses. Utilize visualizations and analytics tools to identify which columns are accessed and filtered most frequently.
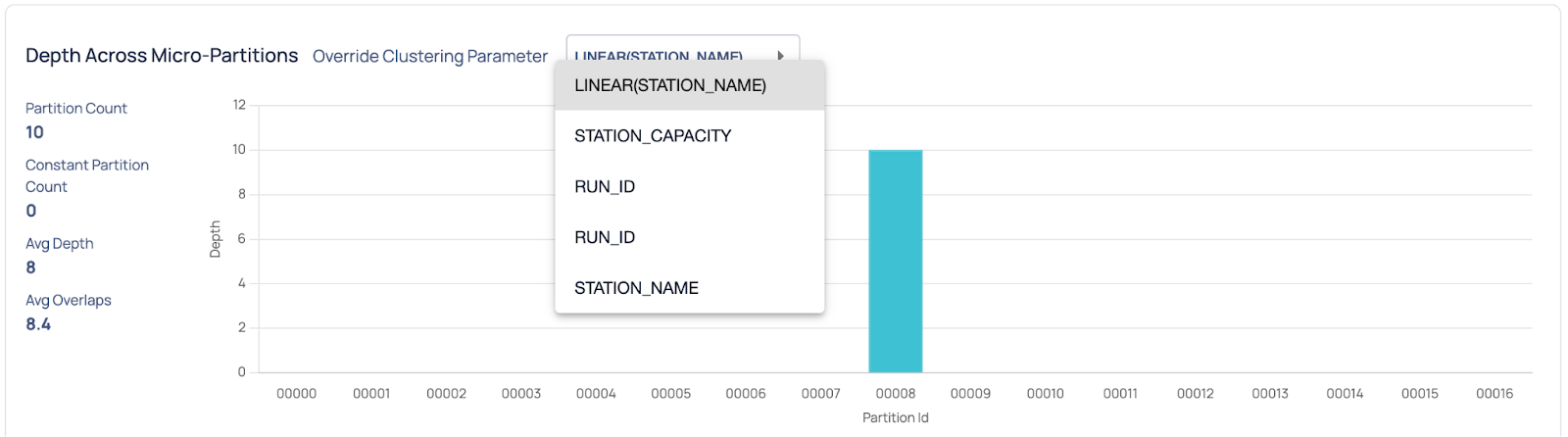
ADOC also fetches CLUSTERING_INFORMATION via the Snowflake table system functions and shows the table clustering metadata in a simple and easily interpretable visualization. This information can guide the decision-making process for optimizing the table layout.
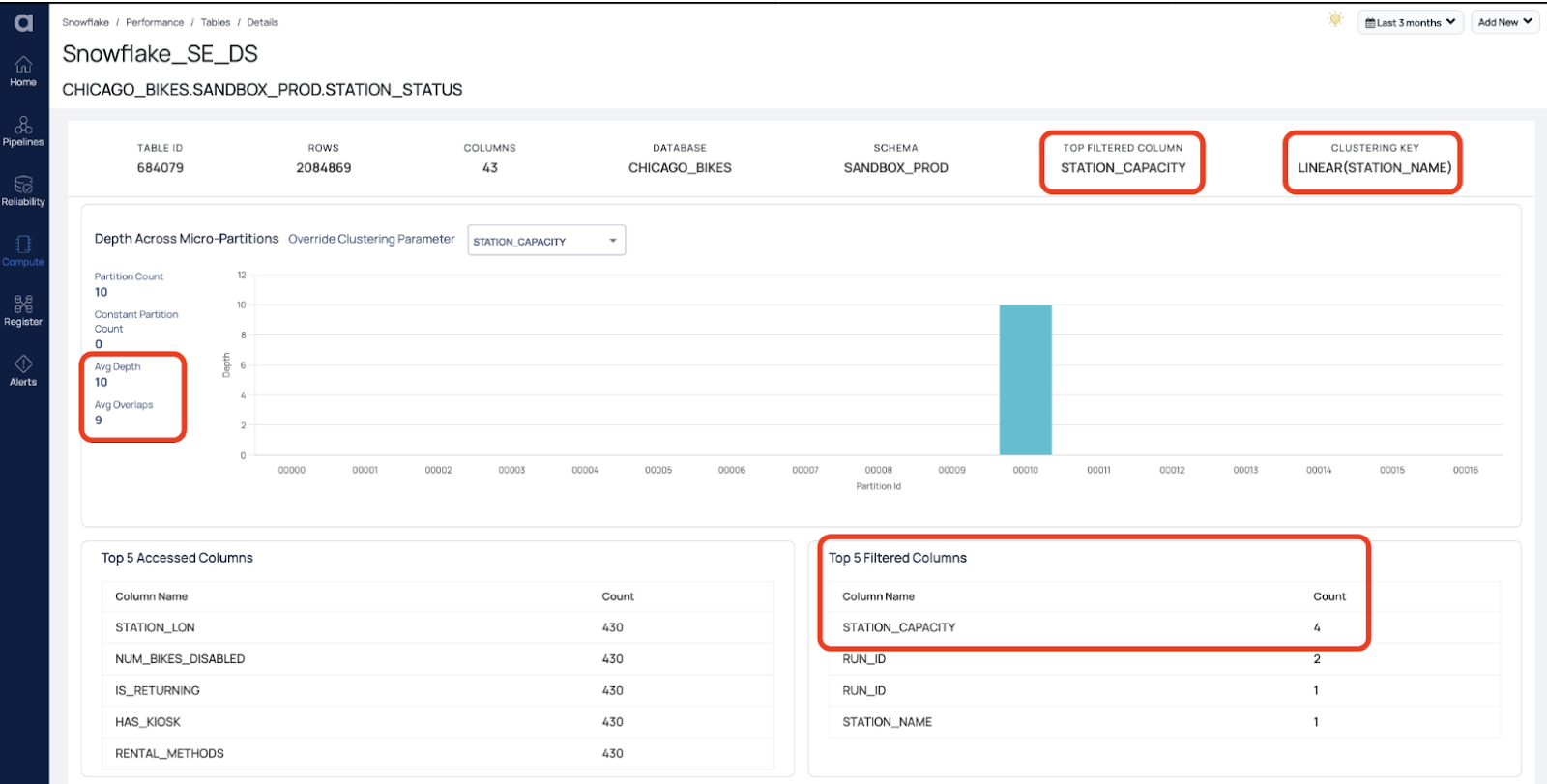
Understand the extent of overlap and depth for filtered columns. This information is crucial for making informed decisions when defining clustering keys.

The ultimate goal is to match clustering keys with the most commonly filtered columns. This alignment ensures that relevant data is clustered together, reducing data scans and improving query performance.
Snowflake's prowess in managing big data tables is unparalleled, but to fully reap its benefits, optimizing performance through data pruning and clustering is essential. The collaboration between the data ingestion team and the teams using the data is vital to ensure the best possible layout for tables. By understanding consumption workloads and matching clustering keys with filtered columns, organizations can achieve efficient queries, reduce costs, and make the most of Snowflake's capabilities in handling big data efficiently.
Take a tour of the Acceldata Data Observability platform to see how it helps data teams optimize their Snowflake workloads.
Photo by Frederik Merten on Unsplash








.webp)
.webp)



