
























































.svg)



































.png)
Bad data - data that is of poor quality, is unreliable, not up-to-date, or otherwise is not governed by a high quality of data hygiene - imposes a significant financial burden on enterprise. It inflicts stress on data teams, especially when they realize, usually too late, that the data they’re working with has contributed to bad decision-making and poor outcomes.
Vigilance is necessary for maintaining data quality, but the operational aspects of managing data shouldn't keep data engineers up at night. With the right approach, data teams can establish and maintain data reliability and ensure their pipelines and operational systems are equipped to support their complex requirements—and, in turn, avoid data anxiety.
The anxiety that data teams feel usually comes from not having complete awareness of how data is entering their environments and how it's behaving and performing. Data engineers are hard-pressed to maintain continuously optimal data operations when they're always thinking about the complexities of data pipeline health, efficient use of their data lakehouses, and wondering if they're overpaying for services from data warehouse and data lake platforms like Snowflake and Databricks.
Curbing their anxiety necessitates insights into their data operations, risk, and performance. As many data teams know, when they use data observability as a foundation of their systems, they can comprehend their data in a detailed manner, optimize their data supply chains, scale their data operations, and ultimately, consistently deliver trustworthy data.
Data observability plays a pivotal role in aligning data operations with key business objectives for data teams. By providing a unified and comprehensive perspective on data, processing, and pipelines at any given moment in the data lifecycle, it facilitates the automatic detection of data drift and anomalies within extensive collections of unstructured data. Ultimately, data observability clarifies and provides context on the condition of an enterprise's data and the systems responsible for data transformation.
In order to optimize their data operations, enterprise data teams should establish and adhere to specific processes that can be achieved through these best practices:
1. Align Business Needs with Data Operational Goals
Enterprises with well-organized and thoughtful data and business teams strive to align their technological operations with their business objectives. However, establishing the necessary processes to ensure reliable outcomes often entails managing a multitude of disparate tools and procedures. Accomplishing this task without the appropriate tools is virtually impossible, and that lack of control is major anxiety producer. Manually measuring and tracking data metrics consumes significant time and effort for data teams, and that builds up a queue of unfinished work that's intended to help improve data operations. Often, in an effort to relieve stress on already overburdened teams, they will forgo tracking and reviewing whether data operations effectively contribute to meeting business needs. The emphasis becomes less about business goals and outcomes and more about just no missing any data issues.
Data observability serves as a valuable tool for data teams, enabling them to monitor workloads and identify both constrained and surplus resources. Additionally, AI-driven features within data observability facilitate the prediction of future capacity requirements by considering factors such as available capacity, buffer, and projected workload growth. These predictions are not merely futuristic or theoretical in nature. Data engineers also know that data blind spots will eventually create problems - another source of stress.
2. Get Comprehensive Insights into Data Pipelines Across the Complete Data Lifecycle
As business operations continue to evolve, becoming increasingly tailored, advanced, and intricate, data teams face the challenge of constructing intricate data pipelines that integrate multiple data sources with diverse functionalities. However, this complexity introduces a greater number of potential points of failure.
Today, data pipelines are continuously ingesting data from structured, semi-structured, and unstructured databases. They are pulling data from a variety of third-party sources and online repositories, including lakehouses, data warehouses, and things like query services. These include Snowflake, Hive, Databricks, BigQuery, and others. The magnitude of what they perform, and the corresponding repercussions of how they can help or hurt business operations can be overwhelming.
You can get a sense for this in the image below, which shows how broad the array of data sources can be. It illustrates how quickly things can become unmanagemeble, and why data teams need to have insights and always-on access to information about data source performance. What you see here is the Acceldata Data Observability Cloud’s management console for managing and filtering these different data sources.
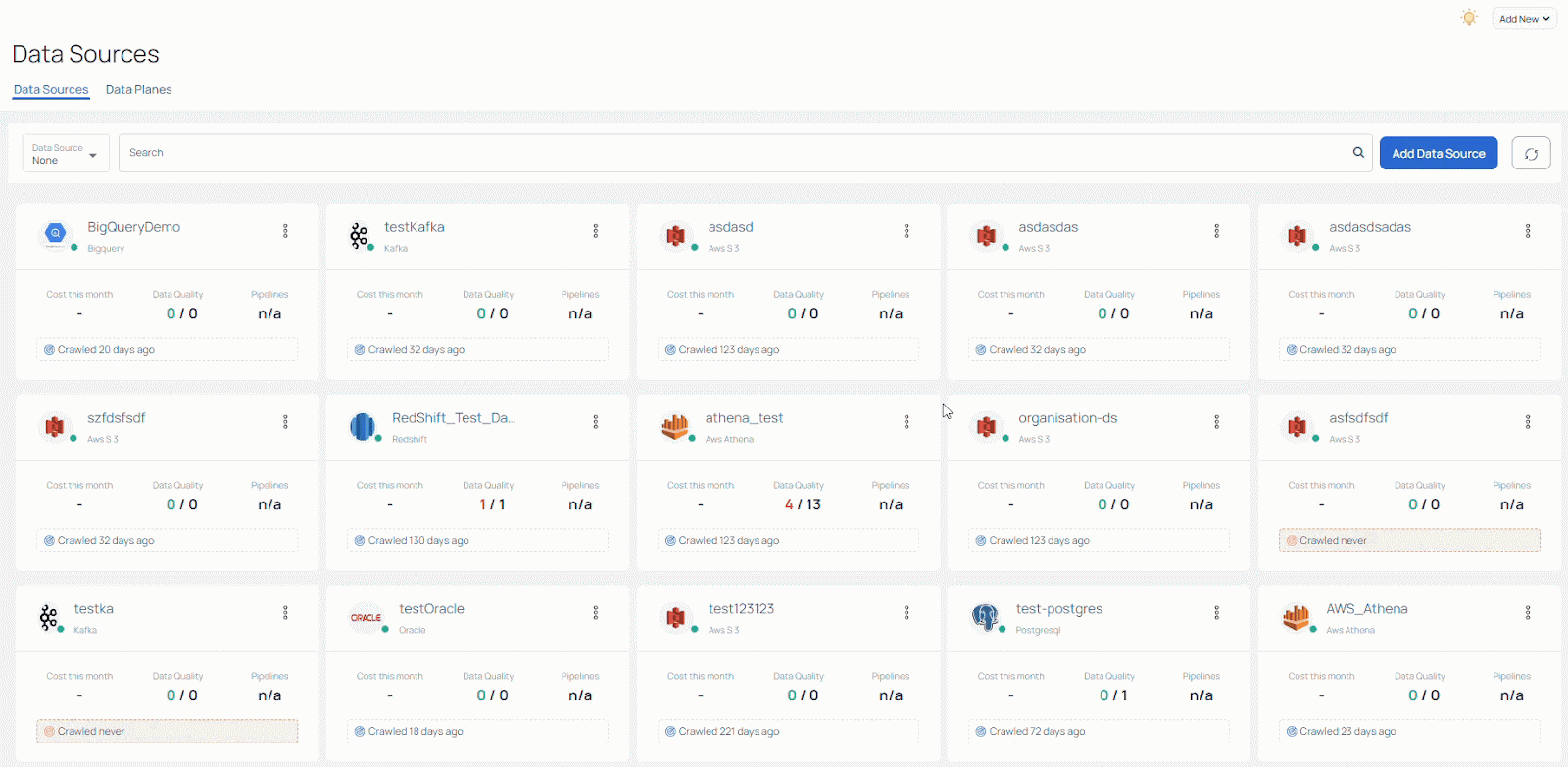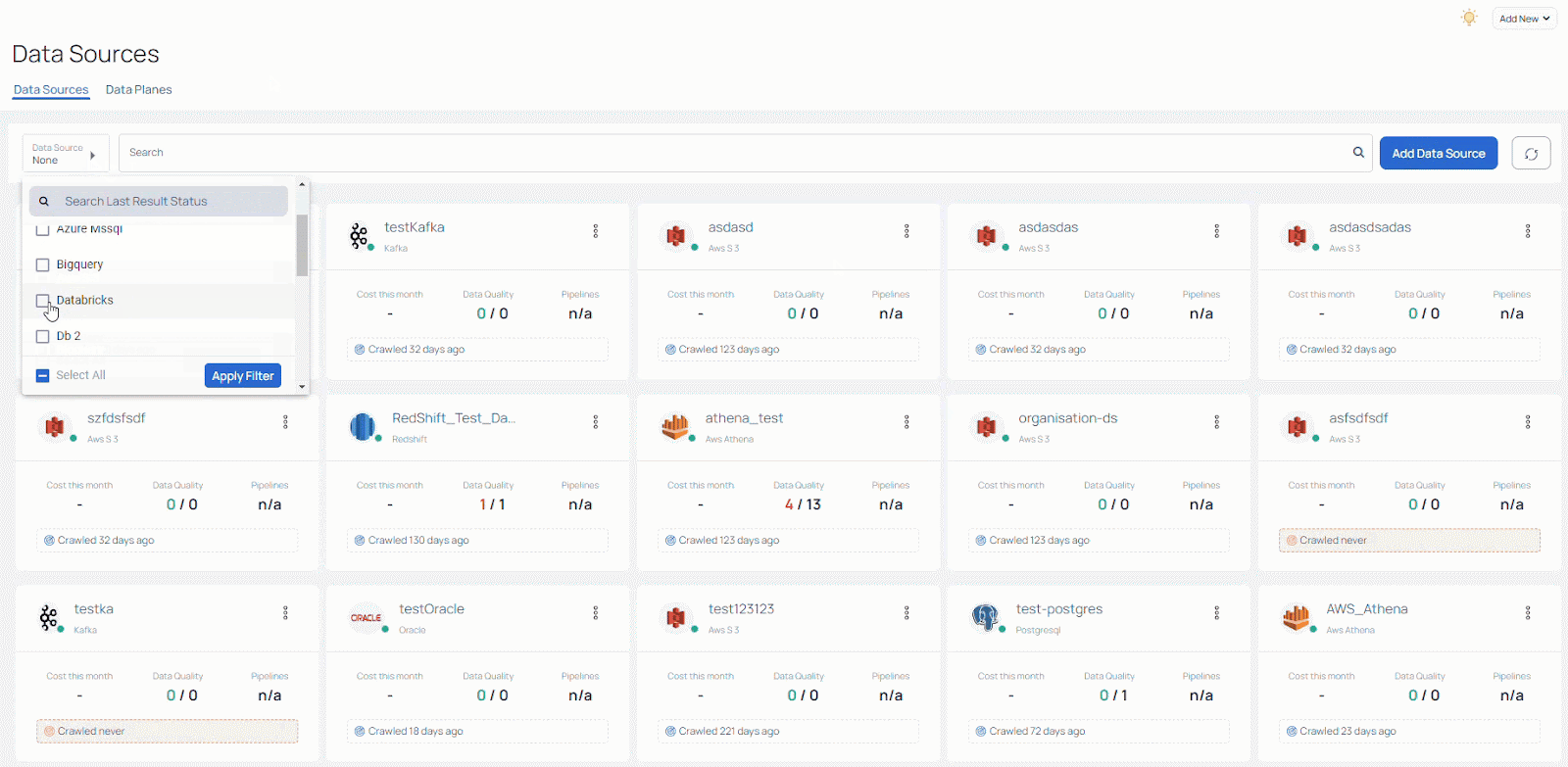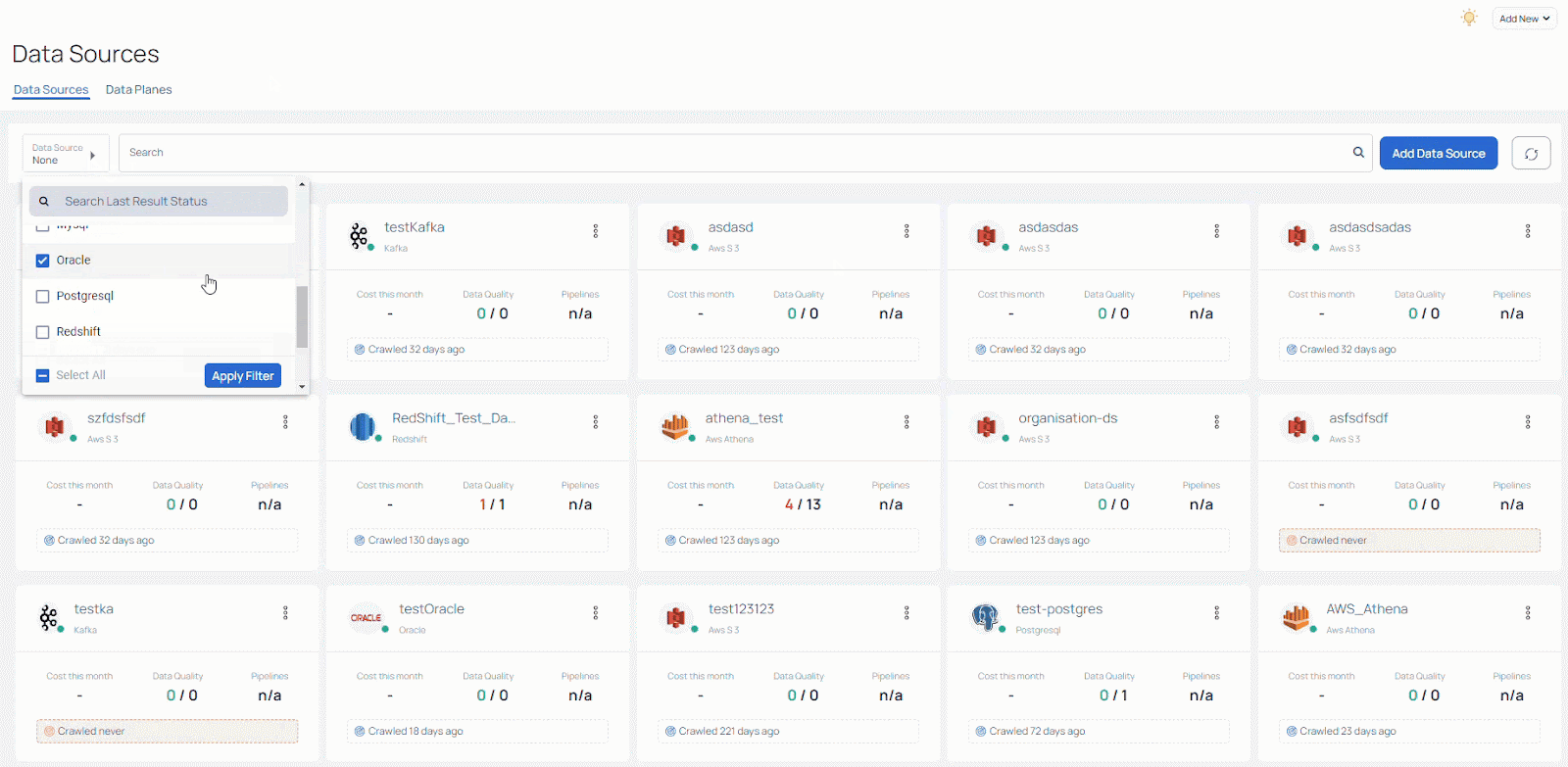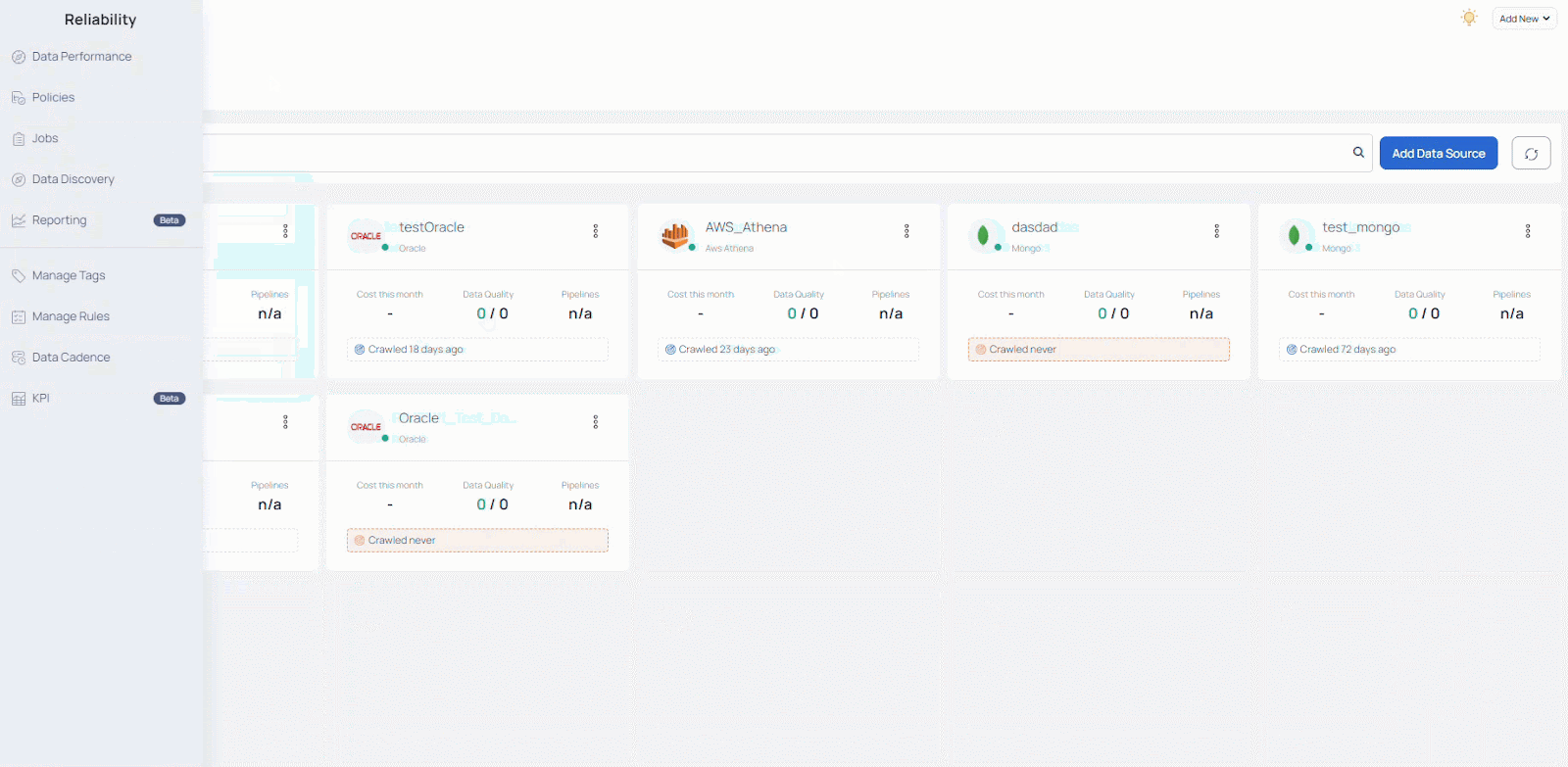
While these technologies undoubtedly aid data teams in rapidly constructing intricate data pipelines, they also generate fragmented and incomplete perspectives of these pipelines. Consequently, this can give rise to unforeseen alterations in data and behavior. As data engineers and scientists can confirm, such circumstances introduce complexity to data operations, particularly when they arise within mission-critical pipelines during production.
3. Help Data Engineers Reduce Their Data Anxiety with Data Observability
Data teams currently face an unprecedented need for a consolidated and comprehensive understanding of their data pipeline encompassing various technologies. To truly enhance data quality, it is imperative for data teams to transcend fragmented perspectives and obtain a holistic view of how data undergoes transformation throughout the entire data lifecycle.
Data teams can take a totally different approach and reduce data scope creep bypass using data observability. More importantly, they can be in control of their data, which enables them to predict, prevent, and resolve unexpected instances of data downtime or integrity issues stemming from fragmented data pipelines. Data teams can automate the monitoring of data from a centralized standpoint, ensuring the evaluation of data fidelity. It upholds data quality throughout numerous transformations across diverse technologies. Data observability enables the tracking of data lineage, guaranteeing the reliability and trustworthiness of data, thereby alleviating the need for data teams to endure sleepless nights while addressing urgent data escalations.
Let’s look at this more closely from the perspective of data lineage, which provides a clear depiction of how data flows from one table to another through a specific process. This process acts as the intermediary for transferring data from the source asset to the destination asset.
As an example, let's take a look at the following diagram, which showcases, in the Acceldata Data Observability Cloud, the derivation of the "mobile data" table from the "employee" table through an insert query.

4. Leverage AI to Automate, Data Reconciliation, Data Drift Detection, and Alerts
In the face of escalating data volume, velocity, and variety, relying solely on manual interventions to enhance data quality is akin to searching for a needle in an ever-expanding haystack. However, by leveraging a data observability solution that employs AI, it becomes possible to automatically identify errors, unexpected data behaviors, and data drift. This targeted approach allows data teams to narrow down problem areas and efficiently resolve data-related issues.
Note that AI is not some dark art that simply reduces the manual workload of teams based on tangential information. Some legacy solutions do provide AI-enabled capabilities that are built around pre-defined rules, but a comprehensive solution like Acceldata uses AI to create a customized rules-based engine tailored to an organization's specific business operations. This enables automatic flagging of missing, incorrect, and inaccurate data records, which streamlines the data quality assurance process.
Data observability helps data teams correlate data records with their original sources. This capability provides valuable insights into the reasons behind unexpected behavior changes and data peformance anomalies. By analyzing application logs, query runtimes, and queue utilization statistics, data teams can precisely identify and address the underlying factors causing these deviations.
These types of solutions are adept at detecting any structural or content changes that could lead to schema drift or data drift. By proactively identifying these issues, the risk of broken data pipelines and unreliable data analysis is significantly reduced. The system automatically spots issues, ensuring swift detection and resolution, thus maintaining data integrity and system reliability.
Solving Data Quality Challenges for Modern Data Teams
Data quality issues persist as a common problem across data-driven enterprises, regardless of their size or scale. However, companies tend to adopt one of two extreme approaches to address these challenges.
On one end of the spectrum, technology giants such as Netflix and LinkedIn invest substantial resources, including millions of dollars and years of effort, to build their proprietary data quality platforms. Meanwhile, the majority of enterprises today rely solely on manual interventions, lacking a platform that can effectively tackle data quality problems at scale, provide a unified view of data transformations, and automatically detect data drift or anomalies.
Developing a custom data quality platform is suboptimal for most companies, as it requires significant investments and lengthy implementation timelines. Conversely, neglecting to utilize a data quality platform that can scale with the organization's data needs can lead to disastrous consequences, including unreliable data and escalating data handling costs.
Fortunately, there exists a better solution. Enterprises seeking to enhance data quality can swiftly integrate a comprehensive data observability solution within a matter of days, with the cost equivalent to that of employing a single full-time staff member.
By integrating data observability into their business operations, enterprises create an environment conducive to continuous data quality improvement on a large scale. This approach not only maximizes the benefits derived from data quality best practices but also provides a pathway to a restful night's sleep and less data anxiety for engineers.
Get a demo of the Acceldata Data Observability Cloud to see how we help clients reduce operational complexity and reign in costs from their cloud environments.
Photo by Nathan Dumlao on Unsplash









