
























































.svg)


































.webp)
.png)
That’s hardly an exaggeration. With 406 million active users and 180 million paying subscribers, Spotify remains the dominant music streaming service in large part because of its exhaustive analysis of user behavior in order to deliver the best, most personalized experience for every listener.
Instead of a single platform and UI, Spotify executives like to say they deliver 406 million “individual versions of Spotify, each one filled with different Home pages, playlists, and recommendations.”
These personalized recommendations and customer experiences are powered by Spotify’s 220+ active ML projects, all run through its internal ML gateway, ML Home. These projects analyze user interaction and system data, everything from the 4 billion+ user-created playlists, listening history, likes, page load times, and more.
Crunching that data is one side of the coin. Spotify first needs to reliably log, publish and store all of this data (600 different types, in fact). This is accomplished through Spotify’s Event Delivery Infrastructure (EDI), which constantly ingests an incredible volume of event data from Spotify user apps. According to a blog post published in October 2021, EDI ingests up to 8 million events per second, with an average of 500 billion events a day. In storage terms, that is the equivalent of 70 TB of compressed data per day (350 TB uncompressed). See below:
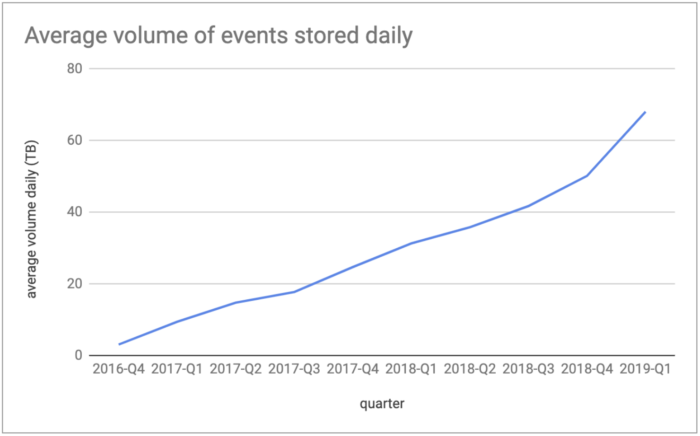
Those statistics were from the first quarter of 2019. Based on Spotify’s continued user growth, the amount of event data ingested daily is probably double or even triple today in 2022. That would translate to many tens of petabytes of compressed data per year.
Lift and Shift to the Cloud
To handle that scale, Spotify has had to upgrade EDI twice in the last six years.
Prior to the first upgrade in 2016, Spotify’s EDI was built around an on-premises system with two major components:
1) A Kafka stream processing system that gathered the logs and pushed them to
2) A Hadoop cluster that stored the ingested streams of events using Hive and the Avro format on HDFS in hour-long partitions
That pre-2016 version of EDI could comfortably handle up to 700,000 events per second. Besides the limits on growth, there were several problems with this infrastructure. First, data jobs only read data once from each hour-long partition. Data streams that were interrupted due to network or software problems would not be backfilled, Spotify decided, because it would create too much additional re-processing for EDI to store it correctly. This led to incomplete and inaccurate data.
Second, EDI was designed around an older version of Kafka that could not persist or store events. That meant event data was only persisted after it was written to Hadoop, making Hadoop a single point of failure for all of EDI. “If Hadoop is down, the whole event delivery system stalls,” Spotify’s data engineers wrote.
Such system stalls and outages grew as the volume of events grew. To fix this, Spotify decided it needed to move the Event Delivery Infrastructure to the cloud — Google’s Cloud.
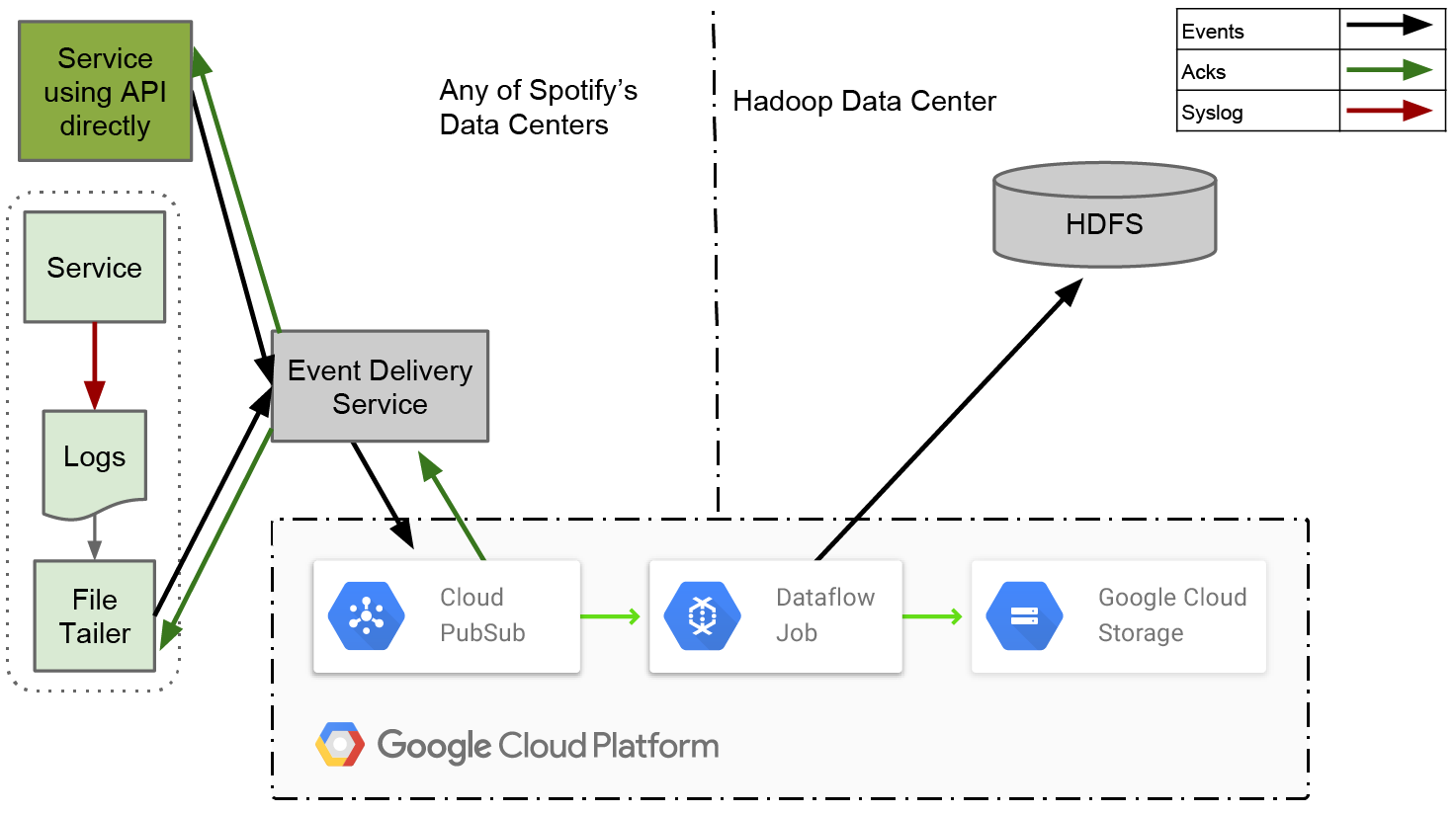
In 2016, Spotify lifted and shifted Hadoop into the Google Cloud Platform (GCP) (above) by migrating to Google’s managed Hadoop solution, Dataproc. While keeping the hourly data partitions, Spotify also slowly migrated Hive and HDFS to BigQuery and Google Cloud Storage. Spotify went all-in on other Google services. It replaced Kafka with Google Pub/Sub, and also added Google Compute Engine, CloudSQL, Dataflow, and more.
Switching EDI from Hadoop to Google’s stack of data services not only increased its scale to half a trillion daily ingested events (70 TB compressed data), but “improved operational stability and the quality of life of our on-call data engineers.” It also made Spotify’s data compliant with GDPR.
Over the next several years, though, cracks slowly began to appear. Bottlenecks emerged. Keeping even a managed version of Hadoop along with some other remnants of legacy technologies made it hard to perform some upgrades and satisfy feature requests from data scientists and more. There was also the lingering issue of incomplete and low-quality data that was “degrading the productivity of the Spotify data community. Whoops!”

Rebuilding for Greater Scale
In 2019, Spotify decided to bite the bullet and build a whole new version of EDI. It constructed a new data processing engine in-house called Scio (Scala API for Apache Beam) that runs on top of Google Dataflow. Scio, which Spotify has subsequently open-sourced, enables companies to run both batch and streaming pipelines at scale. This broke all backward compatibility to Hadoop and other legacy technologies, as well as older versions of Spotify apps that were still streaming user data.
The other major change was the new ability for Spotify user apps to resend or backfill event data. This solved the data incompleteness problem. However, re-sent data can create duplicated data. So Spotify also introduced event message identifiers that enabled the generation of lookup indexes so duplicate data could be quickly found and deleted.
While Spotify migrated its ML and data users over to the new EDI platform, it had to keep the older version live to keep ingesting data from non-upgraded data sources and old clients. Spotify also built a data transformation pipeline importing data from the legacy EDI into the new one.
Spotify does not detail how long it took to build the new version of EDI, migrate users and data sources, or maintain dual infrastructures before it could shut down the old EDI platform for good. But it asserts that overall transition was efficient and problem-free:
“As we neared the end of the migration, we had thrown out nearly all the old, obsolete infrastructure in favor of the state of the art. We successfully changed the wheels of the moving bus, and gave Spotify’s data community a smooth ride.”
Modernizing and Unifying the Data Orchestration Platform
What is data orchestration? Data orchestration platforms source data from different repositories, combining and then transforming the data into the right formats ready for data warehouses, ML models, and other analytical tools.
Data orchestration platforms, also called workflow automation platforms, help data engineers and DIY-inclined data scientists build, schedule, and monitor data pipelines and workflows. They give visibility into what would otherwise be dark data silos, standardize data of different schemas and formats, and then synchronize data from storage through data pipelines to the destination data warehouse or analytical application.
In the pre-big data era, data transformation was handled by ETL data pipelines, with simple scheduling handled through manually-created cron jobs.
As the amount of data, data repositories, data pipelines, and analytical applications exploded, businesses started looking for a more powerful way to manage its complex network of workflows and data pipelines.
“Data orchestration solutions are becoming a core piece of the data stack,” wrote enterprise technology venture capitalist Astasia Myers in a recent Medium blog post.
Spotify certainly fit the profile of a heavy data orchestration user. Every day, Spotify runs 20,000 batch data pipelines defined in more than 1,000 repositories owned by 300+ teams, according to a March 2022 post on the Spotify Engineering blog.
Replacing Legacy Data Tools
Most of these data pipelines had long been managed using two tools: Luigi for Python users and Flo for Java users.
Spotify data engineers developed both Luigi and Flo in-house in the early 2010s, releasing them both open-source within several years of each other.
Using Luigi and Flo, data workflows, libraries and logic were packaged into a Docker image and deployed to another Spotify-built-turned-open-source tool, the data processing job scheduler, Styx. Data is then processed and then published to different locations.

By 2019, Spotify was experiencing increasingly-significant “problems” with Luigi and Flo. One was the high maintenance burden of maintaining and updating features for both applications. Another was the inability to force automatic upgrades to the latest versions (as upgrades were controlled locally). Finally, the workflow containers were “a black box,” meaning that it was impossible to track the progress and health of data as it travels.
Myers, writing separately, agrees. Luigi and another popular data orchestration solution, Airflow, are “first generation solutions” that focus on “being task-driven, decoupling the task management from the task process. They have limited knowledge of the data the task is processing.”
Spotify decided it needed a change. In looking for a new solution, it had two big goals:
- “Make upgrades as frictionless as possible.” Spotify data engineers wanted to automatically install all features and fixes to users and repositories to avoid having to monitor how many updates had been installed, or manage fragmented versions.
- “Enable the development of platform automation functionality.” This was impossible due to the lack of visibility into the status of the workflows.
To achieve that, Spotify decided its solution needed to support three things:
- A managed service that orchestrated the tasks in the workflow
- Business logic controllable by the solution
- Users can define workflows and tasks using SDKs distributed by platform teams
Data-Driven Data Orchestration
Spotify did “extensive comparisons” of data orchestration systems on the market. In the end, it chose to build and manage its data orchestration workflows using an open-source tool called Flyte. Flyte had been developed for in-house use at Lyft in 2017, and released open-source in 2020.
(Side note: data orchestration is one of the areas where open-source data tools created in-house by data engineers at Big Tech companies abound. Airflow was originally developed by AirBnB while Metaflow came from Netflix. Another area where Big Tech has developed and open-sourced its custom-built tools is in metadata for data catalogs and data discovery. These include Dataportal (AirBnB), Lexikon (Spotify), and Databook (Uber), and open-sourced tools such as DataHub (LinkedIn), Amundsen (Lyft), Marquez (WeWork), and Metacat (Netflix).)
According to Myers, second-generation data orchestration solutions such as Flyte “focus on being data driven such that they know the type of data that will be transformed and how it will be manipulated. They have data awareness, can perform tests on data artifacts, and version not just the code but the artifacts.”
Myers also praises Flyte’s active approach to sharing and orchestrating data, calling it “an advancement” compared to first-generation systems like Luigi. She also notes Flyte has a “full-fledged ML orchestrator” and is Kubernetes-native.
All of that translates into numerous benefits for using Flyte, according to Spotify’s data engineers, including:
- “A similar entity model and nomenclature as Luigi and Flo, making the user experience and migration easier.”
- “Extensibility to integrate Spotify tooling”
- “Maintenance of overall platform much simpler than our existing offering”
- “Scalable and battle hardened”
- And more.

While the music streaming company says “the Flyte journey at Spotify is still ongoing — we’re happy to be running critical pipelines, but we still need to migrate all the existing ones from Luigi to Flyte.”
A Unified Data Observability Solution
As illuminating as Spotify is, the company differs significantly from most enterprises.
Its data engineering team is much bigger.
Its IT budget is much larger.
That means Spotify has the resources to acquire, deploy, and custom data engineer around a large number of best-of-breed point solutions.
Such a strategy doesn’t necessarily make sense for your organization.
Instead, a data observability data platform may be a more efficient, powerful way for your data engineering team to gain visibility and control over your data repositories, workflows and data pipelines, improve your migration to the cloud, and cost optimize your data.
Data observability platforms such as Acceldata enable you to monitor and manage your data repositories and pipelines. Acceldata provides compute performance monitoring and correlation to eliminate unplanned outages and scale your workloads with a single click.
Acceldata's data reliability capabilities provide connectors to Hive, HBase, HDFS, Redshift, Azure SQL, Snowflake, Amazon Web Services, Google, Kafka, MySQL, MemSQL, PostgreSQL, and Oracle. That means Torch can automatically crawls virtually any data repository in order to profile the data, verify its quality, and reconcile data when it is transported and transformed using ETL, or when you move it from Hadoop into a modern cloud data warehouse like Snowflake.

Photo by Jace & Afsoon on Unsplash







