





Executive Summary
As organizations process ever-growing data volumes, the demand for faster insights is relentless. Apache Spark has become the de facto standard for distributed analytics, but its row-based execution model often becomes a performance bottleneck at scale.
Acceldata’s ODP Spark with Gluten + Velox delivers a breakthrough by combining:
Key performance gains on TPC-DS 100 GB benchmarks:
- ✅ 1–3× faster query execution
- ✅ 20–30 % fewer CPU cycles per row
- ✅ 15–20 % lower memory allocation pressure
- ✅ Reduced shuffle and I/O overhead
Quantified ROI Example (1000-core Spark cluster)

And the best part? These improvements require no changes to your existing Spark applications.
The Problem: Spark’s Row-Based Execution
Traditional Spark processes data one row at a time inside the JVM. While flexible, this model introduces:
- High function call overhead
- JVM GC pressure from frequent object creation
- Poor CPU cache utilization
- Limited opportunities for SIMD/vectorization
This results in suboptimal performance for analytical workloads such as aggregations, joins, and window functions on large datasets.
The Solution: Vectorized Execution with Gluten + Velox
Vectorized execution processes data in columnar batches rather than rows, unlocking:
- SIMD (Single Instruction, Multiple Data) acceleration
- Improved CPU cache locality
- Reduced function call overhead
- Native (C++) execution performance
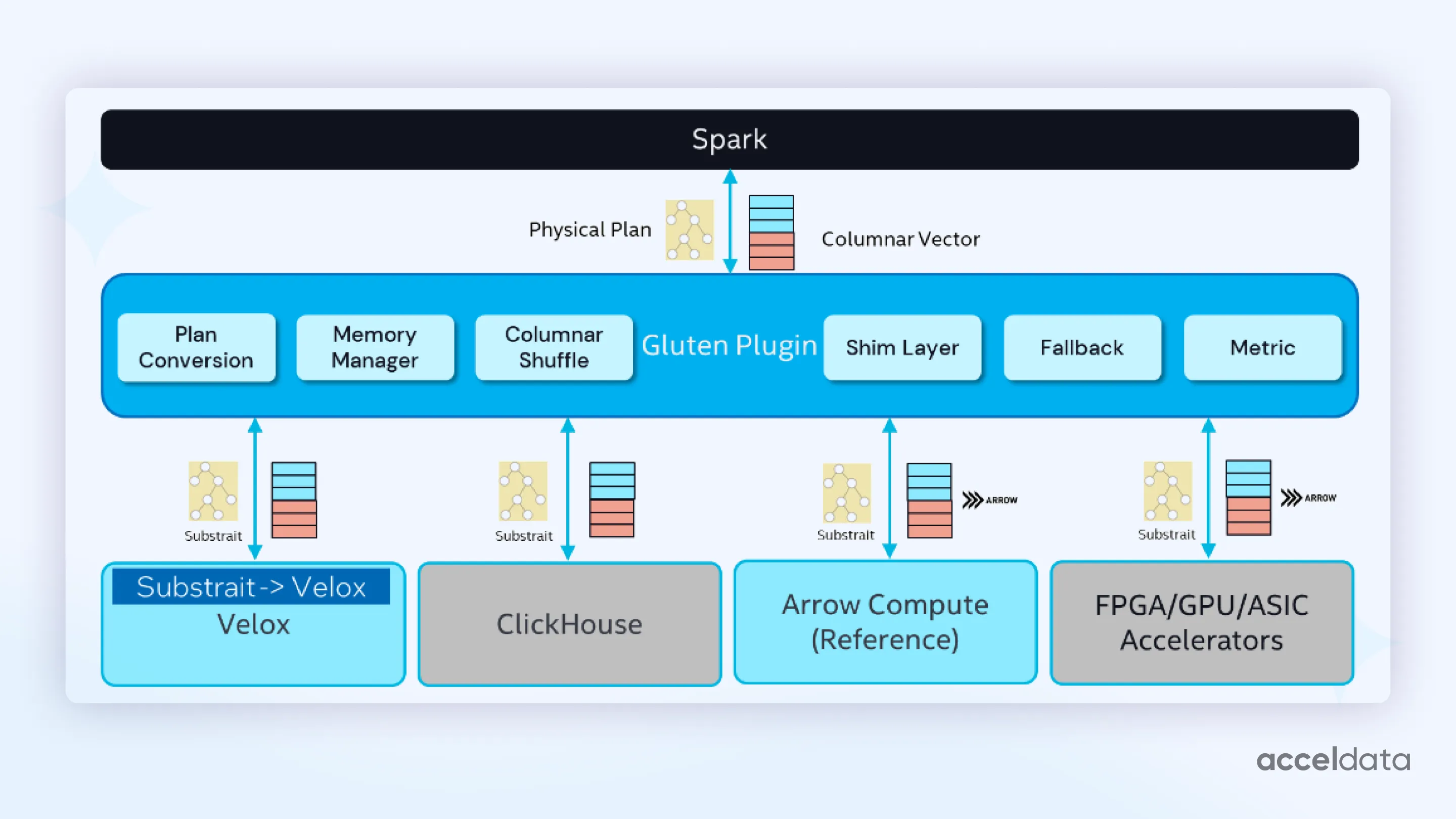
Gluten Framework
Gluten acts as a bridge between Spark and native engines, replacing parts of Spark’s physical plan while maintaining full API compatibility.
Highlights:
- Catalyst integration for rule-based plan transformation
- Extensible backend support (Velox, ClickHouse, Arrow)
- Apache Arrow-based zero-copy columnar data exchange
Velox Execution Engine
Velox is the native vectorized runtime originally developed by Meta for Presto. It provides:
- Columnar batch processing (1024–4096 rows per batch)
- SIMD-enabled expression evaluation and subexpression elimination
- NUMA-aware memory management
- Vectorized operators for joins, aggregates, and window functions
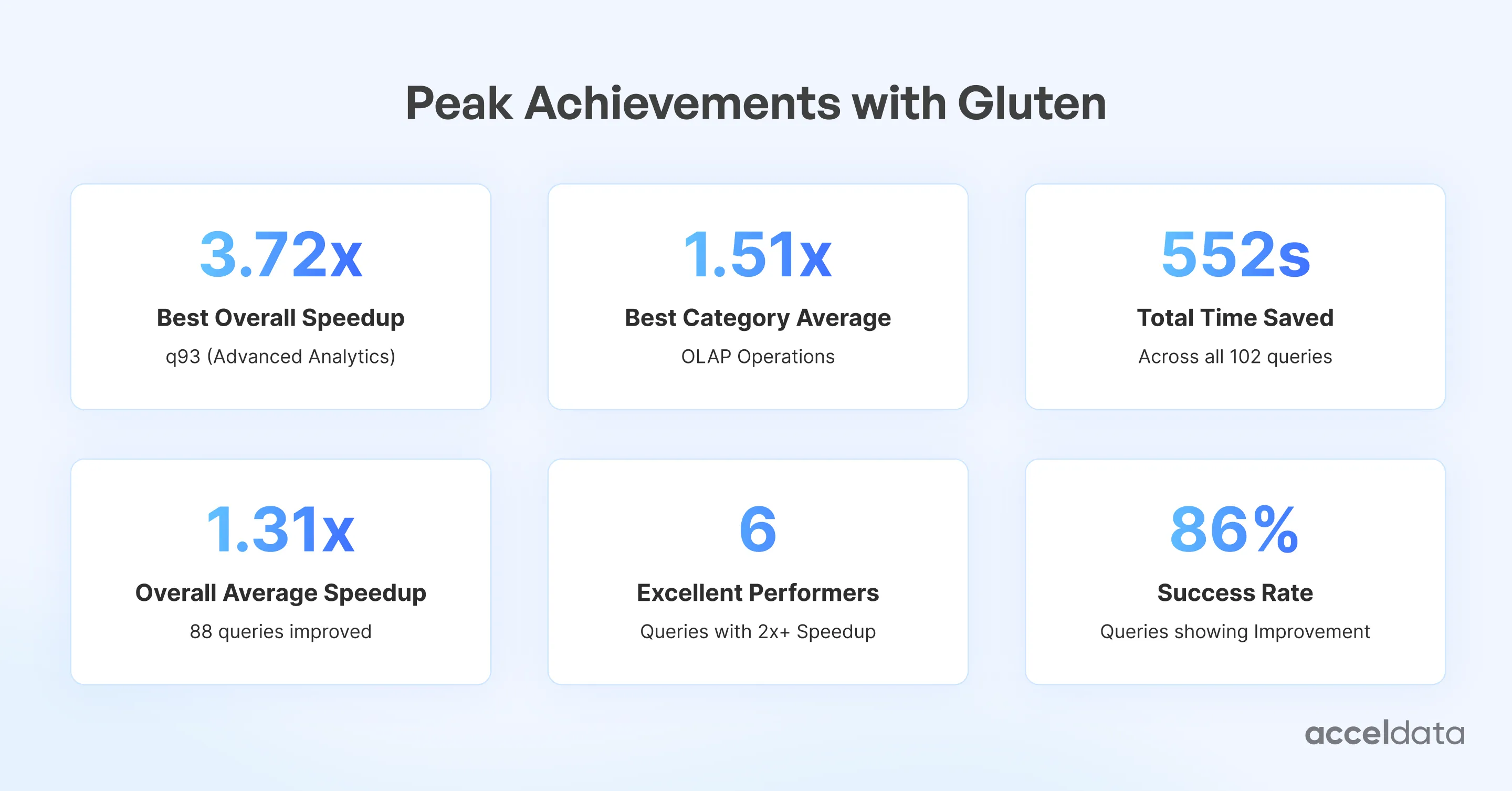
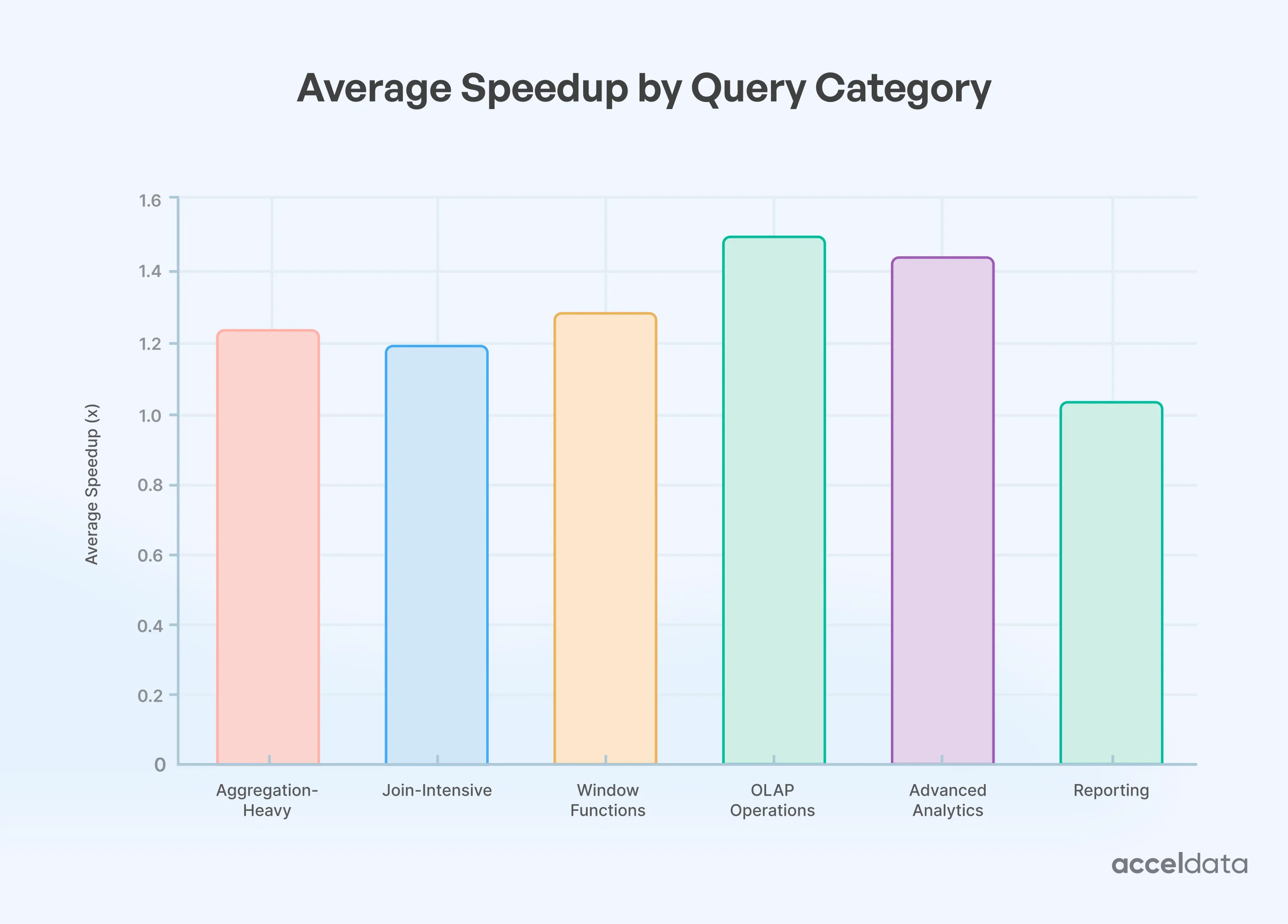
Benchmark Results: TPC-DS on 100 GB
Resource Utilization Gains:
- CPU: 20–30 % fewer cycles per row; better instruction cache hit rate
- Memory: 15–20 % lower allocation pressure; reduced JVM GC
- I/O: better predicate pushdown, improved compression, lower shuffle volume
Implementation Guide
Cluster & Storage Requirements
- Native Velox libraries deployed on all executors
- glibc ≥ 2.28, libstdc++ ≥ 11.2
- Parquet/ORC columnar storage formats
- Modern CPUs with SIMD support
Key Spark Configuration
# Enable Gluten
spark.gluten.enabled=true
spark.shuffle.manager=org.apache.spark.shuffle.columnar.ColumnarShuffleManager
# Memory tuning
spark.gluten.memory.overAcquiredMemoryRatio=0.3
spark.gluten.sql.columnar.backend.velox.memCacheSize=4g
# Vector batch tuning
spark.gluten.sql.columnar.batchSize=2048
spark.gluten.sql.columnar.backend.velox.vectorBatchSize=1024
spark.gluten.sql.columnar.backend.velox.adaptiveBatchSize=true
# NUMA optimization
spark.gluten.sql.columnar.backend.velox.numaAware=true
spark.gluten.sql.columnar.backend.velox.numaMemoryPolicy=preferred
spark.gluten.sql.columnar.backend.velox.numaLocalThreadPools=true
These settings are ideal for TPC-DS style OLAP workloads on multi-socket servers.
Real-World ROI Example
Tuning Velox for Peak Performance
- Vector batch size tuned to CPU L1 cache for better locality
- Memory pools adjusted for OLAP vs streaming workloads
- NUMA awareness enabled to reduce cross-socket memory access
- Built-in monitoring scripts for perf counters, memory usage, and Spark executor stats
Deployment & Compatibility
- No application code changes needed — unsupported queries fall back to JVM.
- Best performance on Parquet; ORC partially supported; JSON/CSV may fall back.
- Structured Streaming not yet supported.
Monitoring tips:
- Spark UI → SQL Plan Tab: look for operators like
VeloxHashAggregateExec,VeloxProjectExec - Stage & task metrics show distinctive CPU and memory patterns for native execution
Roadmap
Gluten + Velox is evolving rapidly:
- Broader SQL function coverage
- Streaming support under development
- GPU acceleration integration
- Advanced compression & query compilation optimizations
- Deep Iceberg, Delta Lake, and Hudi support
Conclusion
Acceldata ODP Spark with Gluten Velox marks a new era of vectorized, native execution for Spark. Enterprises can expect:
- 1–3× performance improvements on analytical queries
- Significant infrastructure savings
- Better CPU, memory, and I/O efficiency
- No application code rewrites
Gluten/Velox is production-ready today for OLAP workloads and is rapidly expanding its capabilities — positioning itself as the next-generation execution engine for Spark analytics.
References
- Apache Spark Documentation
- Gluten Project Repository
- Velox Documentation
- TPC-DS Benchmark
- “Velox: Meta's Unified Execution Engine” — VLDB 2022 Proceedings










.webp)
.webp)



