
























































.svg)




































In this post we provide helpful information for Hadoop admins and data engineers looking to hit their Hadoop BI SLAs.
We explore preemptive actions that can prevent unpleasant and in some cases catastrophic failures. We divide it in the following 3 sections, and recommend Acceldata enterprise customers adopt it in ways that enables their Hadoop BI to perform better:
In-Flight Alerting
Alerts have historically been used to understand and limit risk. So is the case with the Hive and Hadoop ecosystem in general. However, Acceldata has tried to make it a lot more convenient and flexible. Our approach allows:
The unique ability to get in-flight, correlated data which gives Data Administrators sufficient time to react and respond with confidence
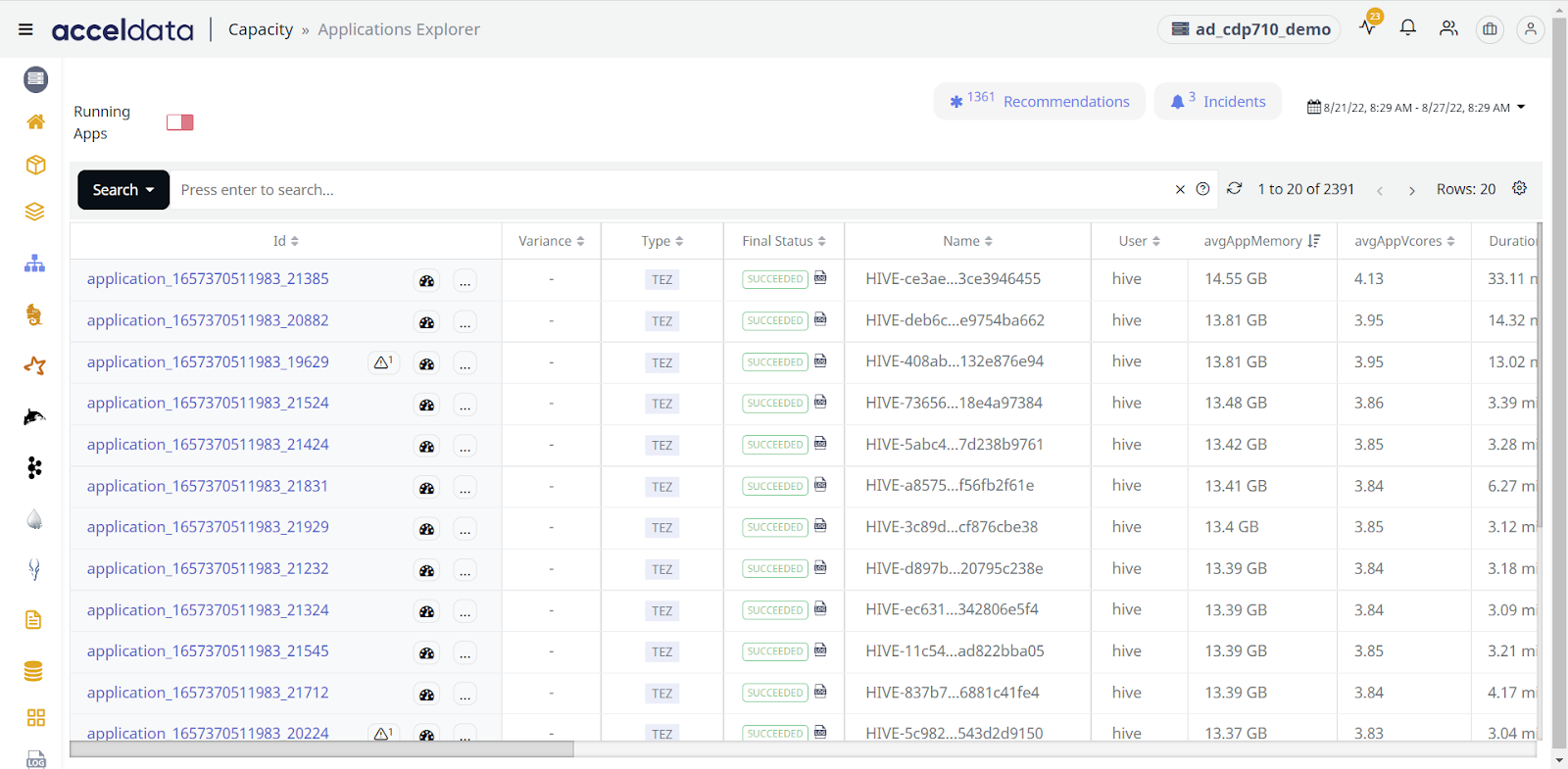
Acceldata displays all the counters/metrics of importance in the UI for rule creation which include:
- Mathematical functions for computing on one or more metrics
- Over 2000 metrics which upon which the alerts can be executed
- In-flight alerting, while the query is executing.
- Complex combinatorial conditions across various metrics
- Filters — avoid mission critical jobs for further actions
Incident reports are available out of the box, for a post fact analysis and improvement verification:
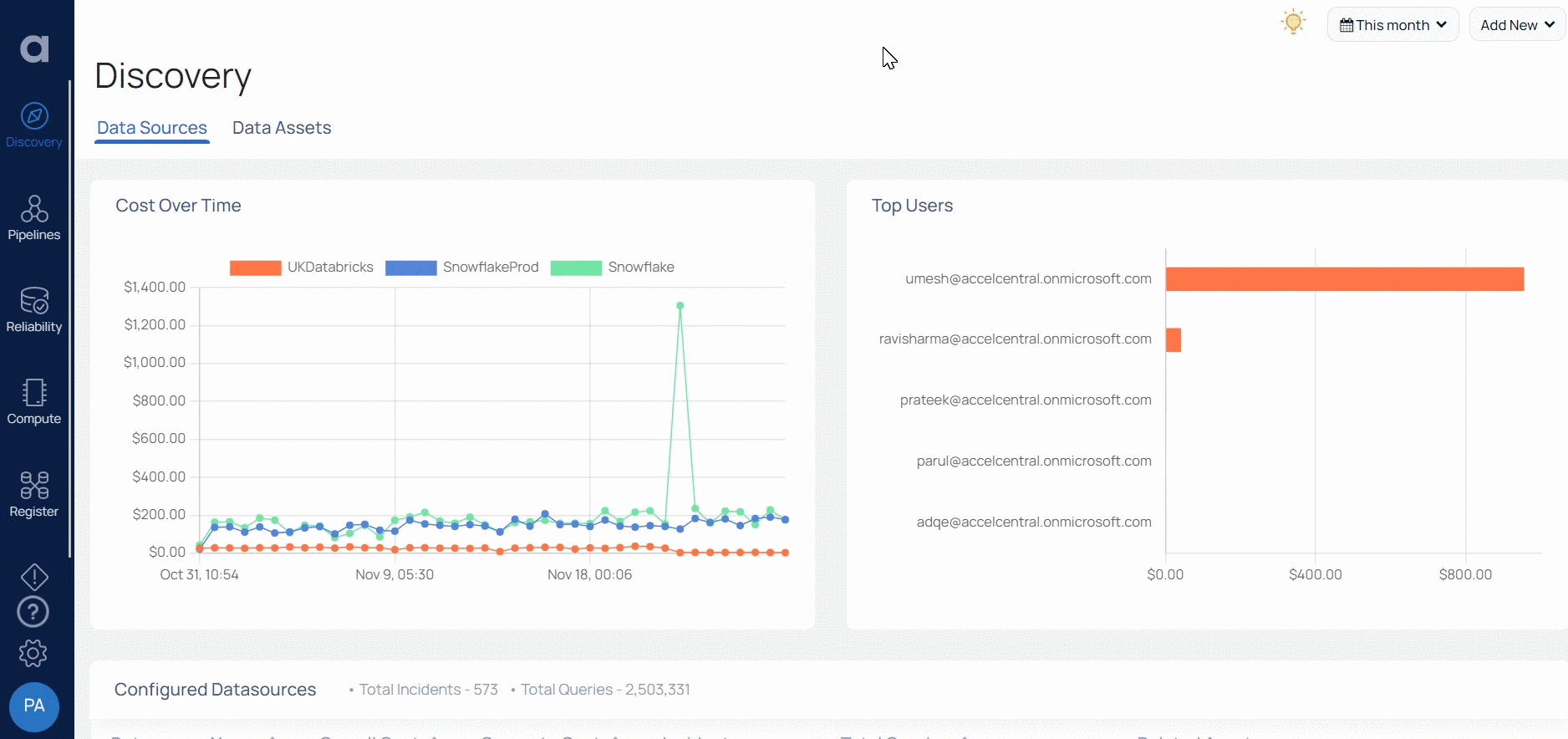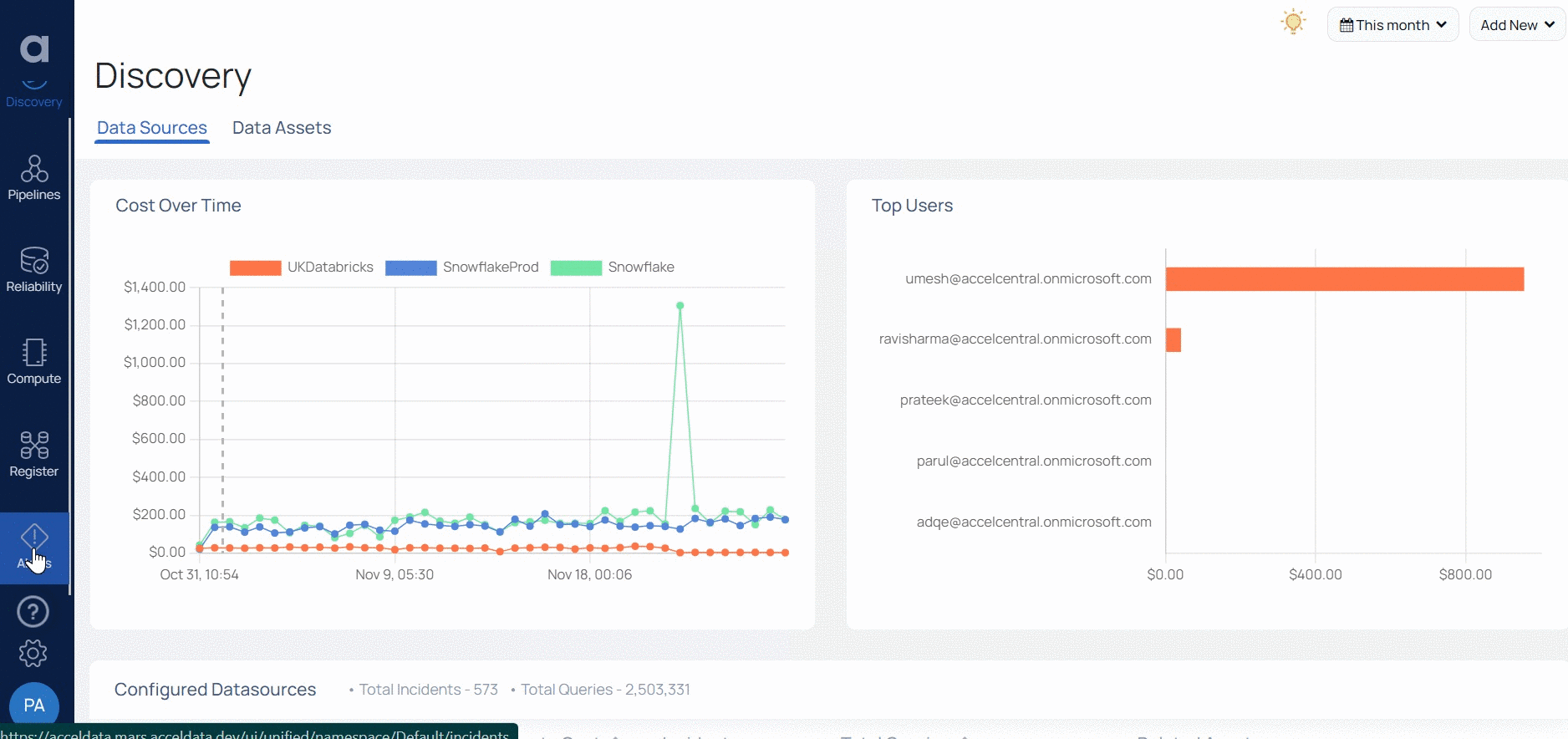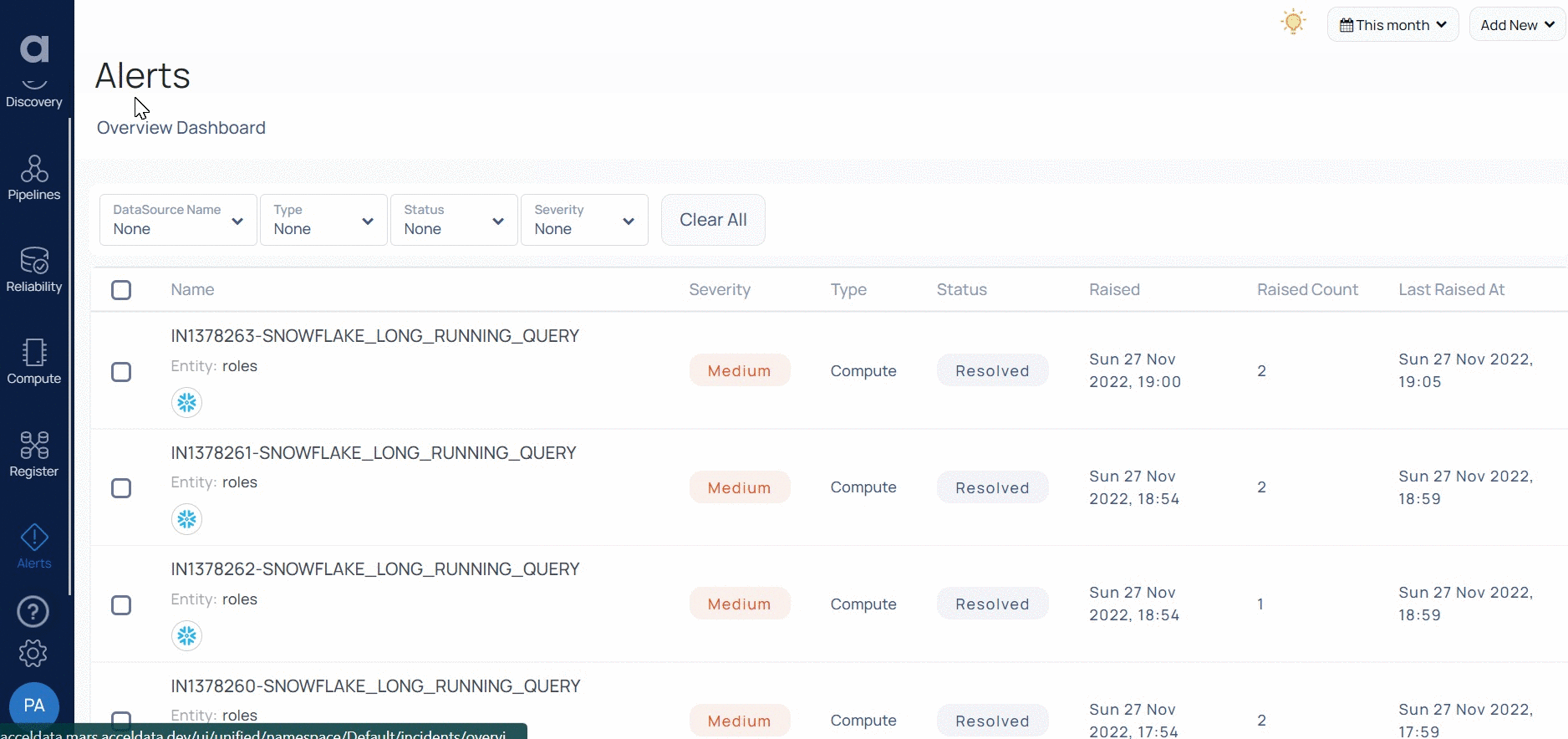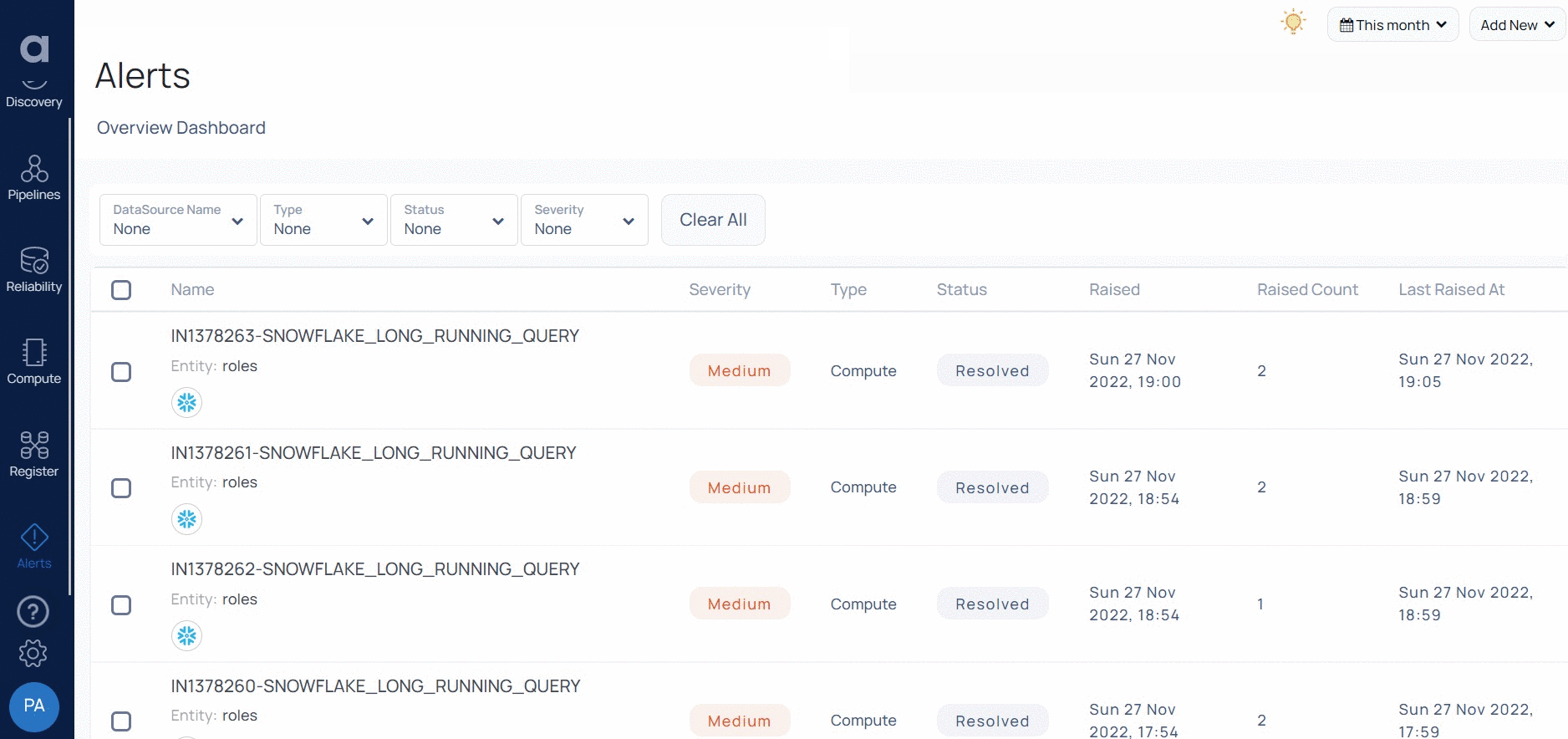
SLA Enforcement through Automated Actions
In many cases alerts are not enough, there has to be immediate action. Acceldata supports several actions out of the box.
This is a natural extension our alerting mechanism, and Administrators can configure this as part of their alert settings itself. Acceldata also provides the additional ability to integrate with enterprise specific operational run-books. Some examples are:
- Killing a particular application when it exceeds a duration, memory bound, or other metric bounds
- Reducing priority of the application to ensure mission-critical jobs are not suffering because of these issues.
- Resume/resubmission of the same job with appropriate parameters which may range from the size of the containers, to memory and in the case of spark jobs it may refer to the number of executors.
- Custom workflow integration examples such as addition of Spot Cloud instances, when there is a lack of capacity, which might cause outage in the case of concurrent users
- Intercept poorly written SQL’s preemptively

The image above shows an automated-action workflow which kills yarn applications which have greater than 25 mappers. Our automated-action framework is an extensible workflow engine which can be used to automate process workflows — through integration of bash/shell or python scripts, which are well outside the cluster management scope.
Better Data Alerts
With the above strategies along with a completely self-serve experience around data exploration, Hadoop Interactive BI on Hive and Spark can be managed well instilling confidence in the user-groups.
Get a demo of the Acceldata Data Observability Platform to see how to quickly and easily create alerts and automated actions.
Photo by Jenn on Unsplash







