
























































.svg)




































Minimalism isn’t just cool because decluttering gurus like Marie Kondo say so. As the world gets ever more complicated, simplicity emerges as a rare and valuable commodity. So less becomes more, and 2 - 1 = 3.
The need for simplicity is never stronger than in the business technology realm. Most IT administrators are drowning in a long list of solutions from a multiplicity of vendors, ranging from aging legacy software stacks, cutting-edge cloud-native applications, obscure one-off point solutions — and everything in-between.
Experienced IT administrators are looking to cut complexity wherever possible. Some quixotically try to steer towards becoming a single-vendor shop, but it is the rare company that has the budget, time, resources, and willingness to successfully pull off such a massive wave of system consolidation and migrations (they would also have to halt all M&A activity that brings in new IT systems lest they be forced to start all over again).
So sprawling, convoluted back-end infrastructures remain the norm. In a pragmatic move, IT admins seeking visibility and productivity are turning to an area they can control. They are eschewing unidimensional and single-platform management tools, even when they are free or promise some tempting best-of-breed feature. And instead, they are choosing single, neutral multi-platform cloud solutions to cut the complexity, labor and cost of administration.
Three Reasons Why Less is More
There are three reasons why choosing one overall management tool rather than multiple ones is better:
- It costs less in licensing and subscription fees
- It’s easier to learn, which saves time and money (in the form of pricey IT salaries)
- It delivers a centralized view — a single-pane-of-glass — over your entire infrastructure. That not only saves you time, but ensures that everything is covered, and that you get the total picture that is lacking when you are forced to patch together alerts and metrics from multiple non-integrated tools.
All of this applies in the specific area of data monitoring and management.
Most modern enterprise data infrastructures have grown into wide-ranging, over-elaborate messes. The reason: the explosion in the supply and demand for data. On the one hand, there has been a mushrooming of new data sources: new applications, IT logs, IoT sensors, real-time streams, and giving individual users the ability to create apps and services on-the-fly.
On the other hand, there was a huge growth in analytics applications, including interactive data visualization tools and self-service apps, that became directly available to business decision makers. Armed with this valuable knowledge, they clamored for:
- More data
- More ambitious scenarios, including real-time, machine-to-machine, predictive, ML, and AI
- embedded in more processes, including customer-facing and mission-critical ones.
In the last decade and a half, vendors have released a flood of new data storage platforms and compute engines, mostly distributed, cloud-native and open-source solutions. Agile-minded businesses embraced these new technologies, quickly deploying data lakes that they promptly filled with unstructured data and connected to their analytics applications. Meanwhile, they held onto their aging but heavily-used on-premises relational databases and data warehouses.
Companies also created data operations teams and rapidly filled them with data architects, data engineers, data stewards, and more. However, in the rush to gain some semblance of control over their fast-growing data infrastructures while keeping the data flowing, most enterprise data ops teams made haphazard choices of the management tools that were at hand.
The problem is that the technologies were evolving so quickly, and the business requirements changing so fast, that data ops teams who have had a chance to take a breather are now regretting their choice of data monitoring tools. They tried to use Application Performance Management (APM) tools to manage data performance — and failed. Or they muddled along with free, open-source tools while constantly running up against facepalming limitations. Or worst of all, they struggled to juggle half-a-dozen unidimensional or platform-specific data monitoring tools, only to discover:
- The time-wasting inefficiency of managing so many tools;
- The crude, reactive nature of these tools, which bombarded them with alerts without providing a way to get ahead of potential problems.
The result is that many data ops teams are woefully unproductive, suffering from alert fatigue, consumed with daily firefighting, and fighting with their LOB counterparts over unmet service level agreements (SLAs) and service level objectives (SLOs). Data performance and data quality both suffer, while data costs spiral out of control.
Single Pane of Glass for Data Observability
There is a solution and it’s a simple one: a full-fledged, neutral, multi-platform data observability solution. It provides your data engineers, site reliability engineers, data scientists and other data ops team members with a single pane of glass to view, manage and optimize your entire distributed and hybrid data infrastructure, including your crucial data pipelines.
Data observability is a specific response to the rise of today’s distributed, hybrid data infrastructures and the fragile spiderwebs of data pipelines connecting them to AI, ML and real-time analytics applications. It was created by experts who observed the limitations of APM-based observability and prior-era data monitoring tools, and single-platform, cloud-bundled management tools — and made sure to transcend them.
The right neutral, multi-platform data observability solution will provide extensive visibility into all layers of your data infrastructure, including the engine/compute level (think Hadoop, Spark and Hive), the data level (including data quality and reliability), and the business layer (data pipelines and your data costs).
Solve Current Problems — and Prevent Future Ones
When combined with its machine learning analytics (because analytics must begin at home), data observability goes beyond visibility and monitoring of a distributed data infrastructure, but also provides data ops teams with synthesized performance metrics to rapidly troubleshoot bottlenecks, unreliable data, and other current issues, as well as predict and prevent future data performance, quality, or cost problems.
The ability to predict and prevent future problems is key. SLAs and SLOs are becoming ever more demanding, as analytics are used to inform more and more business processes and decisions. In this world, alerts are too late, and slow is the new down.
Data observability is the panacea for any enterprise IT and data operations team struggling with:
- The performance or scalability of their Hadoop clusters
- The time and cost of managing their byzantine hybrid network of data stores
- The technical intricacies of migrating data to the cloud or transforming themselves into a data-driven company
Despite the many benefits of data observability, there will be resistance and inertia, even from among your IT and data colleagues. Your Hadoop administrator may insist they are happy with their existing data monitoring tools, but their sluggish data performance, as well as their inability to diagnose the root causes why, undermine their argument. Moreover, sticking with one-dimensional or single-platform data monitoring tools — with their siloed visibility and limited capabilities — forces the rest of your data ops team to manually analyze and reconcile patchy, conflicting data when trying to trace and troubleshoot holistic data performance issues.
Cloud Native for the Cloud Era
Founded in 2018, Acceldata is the only true end-to-end Data Observability cloud solution on the market today built for the demanding needs of today’s data-driven enterprises. Other vendors may claim to offer data observability, but they tend to be glorified data monitoring or APM-based monitoring solutions built for a less-demanding era.
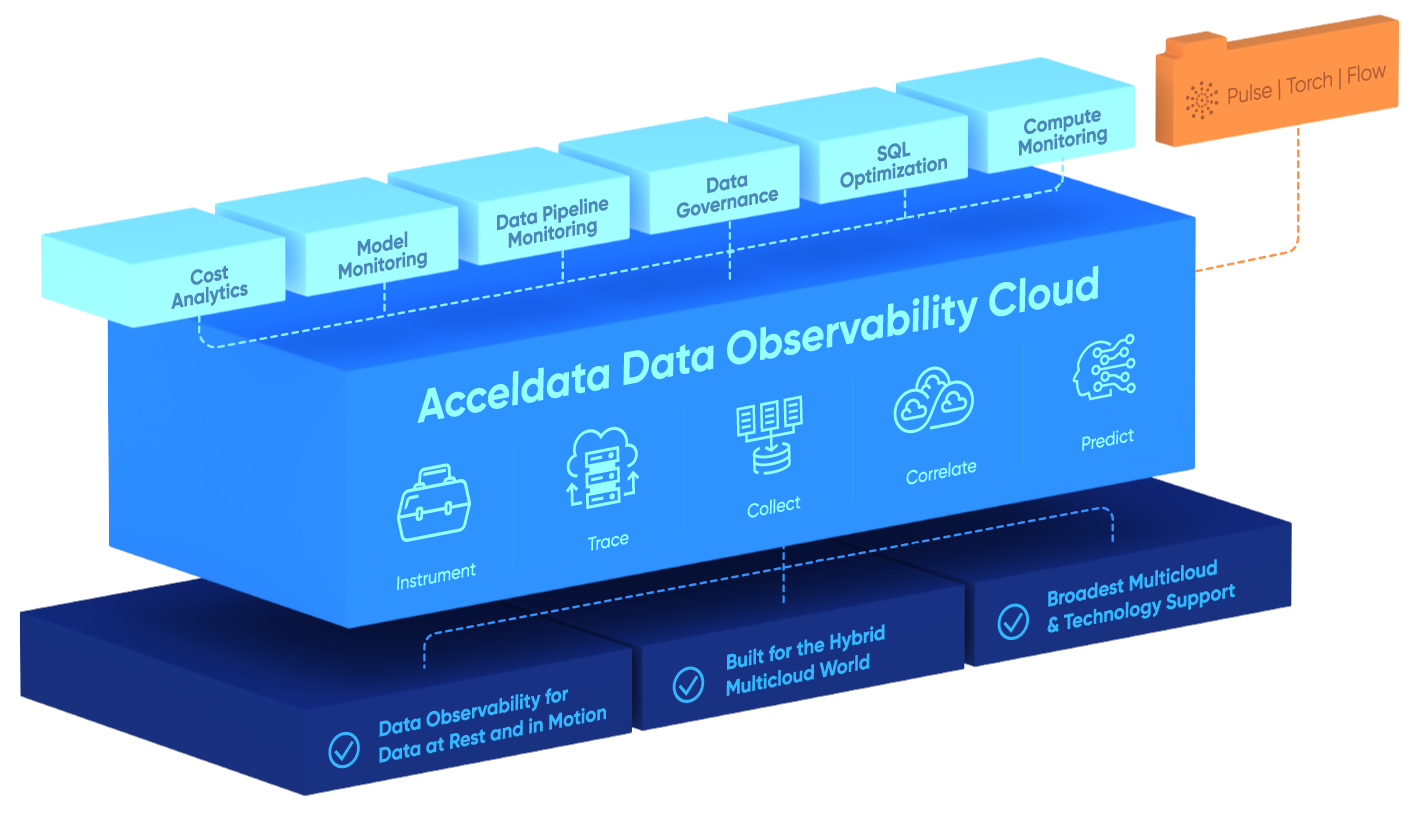
A three-part integrated suite, Acceldata provides comprehensive visibility, control, and optimization capabilities for today’s complex data operations. Its machine learning capabilities help businesses predict and prevent potential problems with their data pipelines, minimizing downtime and enabling them to meet their SLAs/SLOs.
As a neutral, multi-platform data observability solution, Acceldata enables data ops teams to efficiently manage their entire data infrastructure from a single UI, maximizing the productivity of data engineering teams, and the performance and uptime of your data models and analytics applications.
Learn more about the Acceldata platform at www.acceldata.io.









