
























































.svg)



































.png)
Ever since the introduction of Gallup Polls in the 1930s and customer surveys in the early 90s, the role of the “customer” was cemented at the core of all crucial business decisions.
Whether it was customer satisfaction, requirements, or demands, businesses began to lean heavily on public consumer sentiment to gauge product reception and quantify market acceptance. Even from a product development perspective, the “needs of the customer” weighed in. While customer requirements helped organizations create products that captured larger market shares, product managers realized this was not the route toward business sustainability. They needed data!
Businesses today are ingesting far more data than before, and it goes beyond merely “counting numbers” or projecting dashboards. Data is being leveraged to define business goals, build product roadmaps and create more efficient GTM strategies. Hence, the weight of a company’s success sits heavily on the shoulders of an efficient data team. It also presents some interesting economic opportunities.
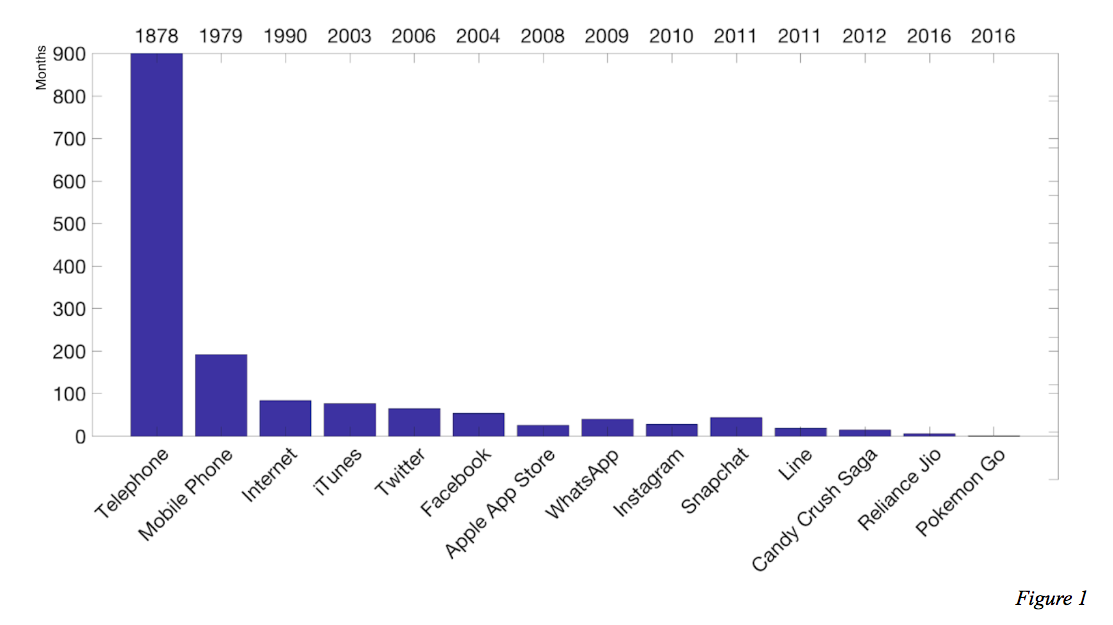
Jeff Bezos, CEO of Amazon, said that data played a pivotal role in the company’s meteoric rise to $100 billion in sales. Similarly, the time taken for digital companies to reach 100 million active monthly users has declined sharply as a result of accurate data science.
Now you’re probably wondering that by saying "data product’" we’re referring to big data products. Actually, it’s quite the opposite. We’re referring to every single product across industries and domains that can leverage data for fine-tuning. And once you look at it from this perspective, boundaries become limitless.
If we take PaaS companies (like Netflix, Hulu, or Spotify), it’s easier to understand the role of data in making recommendation engines more effective. IT Service (ITeS) enterprises utilize data for seamless process optimization and internal mobility. What about manufacturing? The arrival of JIT (Just-In-Time) engineering management showed how data eliminated storage and handling fees. Logistics uses data to optimize final-mile operations, Hospitality for dynamic pricing, and banking for forecast modeling and risk analysis.
So, how can a business decide if its product is a data product? Easy. We’re in the era of data products. Whether you’re building airplanes or toasters, data factors in at some point across the product journey.
Which brings us to the next crucial question: How do you even build data products?
Building Great Data Products: The 5 Step Program
To successfully churn out data products that deliver business value, you need to operationalize the process from end to end.
Step 1: Defining the business need
Before leveraging data, you need to figure out where certain datasets fit across the product journey. For example, consumer behavior data helps in sharpening product UI/UX. Similarly, different data sets help mold product capabilities such as discoverability, security, handiness, efficiency, and stability. In addition to this, unstructured data that flows into warehouses is used to run queries and project KPIs, performance indicators, cost vs. profitability, and other factors. With each step you take during product development, different datasets come into play.
Step 2: Prioritize according to the plan
It’s difficult to establish which data product is more important than any other, simply because requirements pivot according to business demands. Hence, all stakeholders must come together and decide on a detailed plan of action coupled with contingencies to maintain flow.
Step 3: Iterate and evolve
After detailing the plan of action, teams need to move on to prototyping. When we talk about building data products, we’d have to figure out what type of data goes into particular stages of the product journey. Datasets relating to TA, usage frequency, overall usability, and maneuverability goes into fleshing out market fitment, design outlines, platform navigation, and UI/UX.
The requirements are neatly laid out based on critical factors such as data ingestion rate, storage, and big data application usage. After this various teams can begin to sketch their data models to identify their pathways.
Step 4: Create the product/architecture
If you’re relying on data to build a product, you need to set up the architecture that outlines the ingestion-storage-workability-consumption of data. By establishing the data-flow architecture, you’ll get a bird's eye view of the different teams, resources, and potential bottlenecks.

Step 5: Data Observability and Monitoring
For enterprises and businesses that have multiple data sources, the volume of data flowing through an organizational data ecosystem is vast. With distributed pipelines come possible knee-jerk data moments. Erroneous datasets, duplicated datasets, and system/hardware failures are common occurrences for enterprise systems. When we’re in the motion of building data-led products, these bottlenecks can bring processes to a grinding halt!
Data observability as a solution provides end-to-end data monitoring, remediation, and reports for seamless operability. By getting an overview of the entire data ecosystem, organizations can mitigate data-related risks, breakdowns, or disputes.
Whether it’s on-premises or on the cloud, solutions like Acceldata’s Data Observability platform give you detailed insights to help you align cost to value.
Get a demo of the Acceldata Data Observability platform to learn how data observability can help your enterprise.
Photo by Edgar Chaparro on Unsplash







