In today’s business world, analytics are business-critical. Companies are making near real-time decision-making to support new agile business models and strategies. Organizations are also creating new “data products” for consumers both internally and externally to use the vast amounts of data being produced. This makes data and the data pipelines that feed these analytics mission-critical.
The definition of mission-critical for data and data processes also includes the need for accurate, high-quality, and highly reliable data. Without this, consumers will not trust the data provided to them and use the data products provided, keeping organizations from monetizing their data. In some industries, poor data reliability can also keep organizations from complying with new regulations around data.
In the shift to modern, cloud-based analytics many aspects have changed from the legacy data analytics and warehousing world. Formerly batch data processes are now near real-time and on-demand. Higher data volumes put tremendous performance stresses on the underlying data systems. And, more complex data pipelines force data reliability checks at each hop whether the data is at rest, in motion, or in final form for consumption.
Modern data reliability provides data teams with complete visibility into their data assets, pipelines, and processes necessary to make data products successful. Data reliability is a major step forward from traditional data quality. It includes data quality but covers much more functionality that data teams need to support for modern, near-real-time data processes.
Legacy Data Analytics, Data Warehousing, and Data Quality
Historically, data processes to deliver data for analytics were batch-oriented. These processes focused heavily on highly structured data, both at the source and in the final formats in the data warehouses. Data teams had very limited visibility into the data processes and processing, in particular as to what was happening to the data along the pipeline.
Legacy data quality tools and processes were used and designed with the limitations of data processing and warehousing platforms of the time. Data quality processes:
Were run in batch performing semi-regular “data checks” weekly or monthly,
Only performed your basic quality checks,
Was only run on the structured data in the data warehouse.
Were manual queries or performed by “eyeballing” the data
Due to performance and operational limitations, data quality checks could only be performed on the “data-for-consumption” at the end of data processes and NOT on the source data or as the data was being transformed. This allowed low-quality data to leak all the way downstream into the analytics.
Data Quality is a Major Concern
Censuswide recently conducted a survey of more than 200 data leaders (which includes Chief Data Officers, VPs of Data Platforms, Data Engineers, and a variety of other titles from across the United States. In this survey, the data leaders were asked questions about their data pipeline health and data quality. The results showed that:
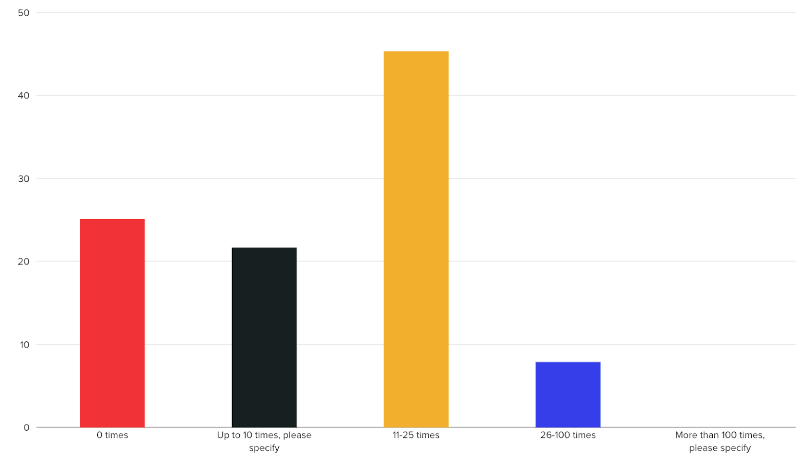
45% have experienced data pipeline failure 11-25 times in the past two years due to data quality or errors that were discovered too late.
Of that 45%, 63% said that the customer experience their organization delivers suffered from data pipeline failures.
Over half (53%) state that their data teams spend 1-6 days per month addressing data quality issues.
58% indicate that dealing with issues related to data quality interferes with other job responsibilities and higher-priority projects.
How many times in the last two years have your data pipelines failed due to data quality or errors that were caught too late?
How much time, if any, do you spend per month addressing issues related to data quality?
Today’s World of Modern Analytics
Modern, agile business processes need to be supported by near-real-time analytics. Give examples. (recommendations, next best action, shortest routing, 24-hour decision-making for business loans or funding, near real-time ad spend, etc.)
As analytics needs grew, other background factors affected data pipelines:
Data volumes continue to grow, both at the source level and in copies of data transformed and moved for analytics,
Source data formats have grown to include semi-structured and unstructured data and come from many different applications, including SaaS ones
Data pipelines and processes work with data in various stages: at-rest, in-motion, and to-be-consumed, and
Data resides in and moves through a hybrid environment of both on-premises and cloud
No longer could data teams offer simple, manual data quality checks. They needed to continuously check on the “data reliability” to ensure the proper flow of high-quality data.
Data reliability is a major step forward from traditional data quality. Data reliability includes data quality but covers much more functionality that data teams need to support for modern, near real-time data processes, including:
More advanced monitoring, detection, and remediation techniques such as data cadence, data-drift, schema-drift, and data reconciliation,
Real-time alerts and continuous processing of data policies as data changes and flows through pipelines,
360-degree insights about what is happening with data processes and how to remediate problems,
Scalable processing of data rules and policies to cover the ever increasing data volumes flowing through pipelines
As opposed to traditional data quality which was applied at the end of data pipelines on the data-for-consumption, data reliability helps data teams implement, check and work with data at all stages of a data pipeline across data-at-rest, data-in-motion, and data-for-consumption.
Adopting a “shift-left” approach to data reliability allows problems to be detected and isolated early in data pipelines, before it hits downstream data-for-consumption and the data warehouse. Early detection also allows teams to be alerted to data incidents and remediate problems quickly and efficiently.
Acceldata for Data Reliability
The Acceldata Data Observability Cloud (ADOC) provides data teams with end-to-end visibility into your business-critical data assets and pipelines to help you obtain the highest degrees of data reliability. All your data assets and pipelines are continuously monitored as the data flows from source to final destination and checks are performed at every intermediate stop along the way for quality and reliability.
Acceldata helps data teams better align their data strategy and data pipelines to business needs. Data teams can investigate how a data issue impacts business objectives, isolate errors impacting business functions, prioritize work, and resolve inefficiencies based on business urgency and impact.
The Acceldata Data Observability Cloud (ADOC) fully supports and embraces an agile, shift-left approach to data reliability. The ADOC platform performs this with five key capabilities:
Automation - ADOC augments and offers machine learning-guided assistance to help automate many of the data reliability policies and processes.
Data team efficiency - ADOC supplies recommendations and easy-to-use no- and low-code tools to improve the productivity of data teams.
Scale - ADOC has bulk policy management, user-defined functions, and a highly scalable processing engine to run deep and diverse policies across large volumes of data.
Operational Control - The ADOC tools provide alerts, recommended actions, and supports multi-layer data to identify incidents and drill down to find the root cause.
Advanced data policies - ADOC offers advanced data policies that go far beyond basic quality checks such as data cadence, data-drift, schema-drift, and data reconciliation.
ADOC supports the modern end-to-end approach to data reliability by monitoring data across all three states it can be in - data-at-rest, data-in-motion, and data-for-consumption - to ensure data quality is high across the entire pipeline and to isolate problems early in the pipeline stages. It also performs reliability checks on the various data formats that may be encountered in these stages - structured, semi-structured, and unstructured.
The ADOC platform exposes these capabilities to data teams through self-service tools and composable dashboards and alerting. For more advanced use, data teams can programmatically perform the functions they need and use developer-centric APIs.
Automation
The continuously growing number of data sources, destinations, and overall data volumes are constantly challenging data engineers to maintain and monitor their data reliability. The Acceldata Data Observability Cloud helps accelerate and expand an organization’s data reliability by automating many of the tasks involved.
Automated metadata classification, data profiling, and data cataloging is native to the Acceldata platform and is augmented using AI and machine learning (ML). This automation improves productivity and reduces errors while providing users with a clear understanding of data structure, content, and relationships. Data owners and consumers can further enrich the assets in the catalog with tags, annotations, ratings, and custom metadata to add further insights and build trust.
Acceldata uses data crawlers to automate metadata classification when a data source is first connected. Data teams can also schedule data crawling against data sources at regular intervals to monitor schema drift. Depending on the source type, Acceldata collects different types of metadata.
Use of automated data profiling examines and analyzes data available in data sources. During data profiling, Acceldata gathers information about data types. It collects statistics, tags data with classification or glossary terms, and performs data quality checks. Acceldata can automatically tag sensitive data and provides role-based access controls (RBAC) to mask data as appropriate.
Data Profiling in Acceldata
Acceldata stores metadata and business glossary terms in an internal, unified data catalog. This helps centralize an organization’s available asset inventory regardless of whether assets are in the cloud or on-premises. The catalog is searchable, allowing teams to easily discover assets at their disposal.
Acceldata provides automated data cadence monitoring of your data sources. Data about query usage, record counts, and data volumes are continuously gathered, providing usage dashboards about the data sources. A heatmap visualization displays important information on various metrics for each of your assets to identify hotspots requiring potential problems.
Machine learning assisted anomaly detection on a data asset is also provided in Acceldata. Each time an asset is profiled, various metrics such as completeness, distinct values, minimum value, mean, maximum value, standard deviation is calculated for each column and recorded. Acceldata applies ML to the recorded data points to continuously monitor for anomalies in the data.
Team Efficiency and Scale
The Acceldata tools increase the productivity and efficiency of the data engineering teams to create data quality and reliability policies. This allows data engineers to spend less time firefighting data incidents and spend more time producing innovative new data products for their organization.
The no- and low-code user interface, along with the underlying automation, makes it easy to apply even the most complex data policies and rules. Acceldata uses AI on the metadata and data profile to automate and recommend a wide array of policies and rules for a data asset. Additional policies can be defined via wizards without the need to write code. For each policy, a data engineer defines quality rules that can check for missing data, duplicate records, incorrect format, values or patterns, invalid tags, out-of-range values, or business rules.
For more complex data, Acceldata also allows data engineers to create reusable, user-defined functions and transformations for reliability checks using SQL, scripting (JavaScript), or coding languages (Scala, Java, and Python).
Policies can be templated and applied to any data asset that complies with the template. Using these templates, data teams can bulk manage and apply to various asset types. Segmentation can be applied to the various data assets for bulk application of policies or analysis across different dimensions.
The Acceldata platform architecture includes a highly scalable processing engine to analyze information and policies on the data assets, data pipelines, data sources, and other items in the data stack. This provides real-time visibility to identify incidents as they occur and covers the ever growing volume of data flowing across your data pipelines and in your data sources.
No-code Addition of Data Policies with AI-driven Recommendations in Acceldata
Operational Visibility and Control
Acceldata provides your data teams with an operational control center for your data to treat it like the mission-critical product it is. It is specifically designed for data teams with customizable dashboards, alerts, audits, and reports, providing a single pane of glass for all your data assets, pipelines, and sources.
Acceldata gathers deep insights up and down the data stack about the data, data pipelines, and the environment. This includes metadata, data lineage, data content statistics, results from data policy rules and data pipeline runs, compute use, query performance, and job performance. This multi-layered data is correlated so that when issues occur data engineers can quickly drill down into the data to identify the root cause of the problem and resolve it.
During data pipeline execution, Acceldata monitors data integrity against the quality rules, identifies incidents, and displays information and alerts to dashboards to help data teams resolve issues quickly. Dashboards and alerts are composable and customizable to meet the needs of the team and individuals. From dashboards and alerts, data engineers can quickly drill-down into the correlated multi-layered data gathered by Acceldata to identify the root cause of incidents and find ways to resolve problems.
Composable Alerts Dashboard in Acceldata
Timeliness/Freshness
Acceldata monitors query and data pipeline execution and timing to identify if data is not arriving on time and help optimize data pipelines. Teams can set SLA alerts for data timeliness (as well as other metrics) and get alerts if SLAs are not met. Data is followed all the way from source to consumption point to determine if the data arrived at all, how long it took to arrive, and if there are timeliness problems.
The rich set of multi-layered data gathered by Acceldata allows data engineers to drill down and identify performance and timeliness issues and find ways to optimize the pipelines to meet SLAs. Data engineers can use the Acceldata data pipeline replay feature to restart data pipelines and remedy data delivery problems with immediacy.
Advanced Policies
Using the ADOC automation and no-code interface, data engineers can apply advanced data reliability policies such as data-drift, schema-drift, and data reconciliation. Early detection of drift and reconciliation of data allows data engineers to resolve issues before they impact downstream applications or analytics.
Data-drift
A data drift policy measures and validates data against tolerance threshold data characteristics such as completeness, distinct values, mean, min, max, sum, standard deviation, and top 10 values. Data drift policies are executed every time an asset is profiled. During data profiling, information is gathered about how well data is structured, how parts are interrelated, and errors within individual records. Acceldata also tracks each profile that is performed. By comparing the difference between two profiles that have been run against the same data asset, a data engineer can identify when a data drift error first surfaced.
Schema-drift
Schema-drift occurs when a data source veers from the original schema used to define its structure. Schema drift policies are executed every time a data source is crawled. During data crawling, Acceldata collects metadata about the data source (for example, tables, columns, fields, and views) and displays changes made to the schema. When changes are unexpected, a data engineer can drill down into the schema change to understand what happened and resolve the issue before it impacts downstream applications.
Data Reconciliation
Acceldata offers data reconciliation capabilities to ensure that data arrives as expected. Acceldata addresses key challenges enterprises face regarding data reconciliation at scale by:
Simplifying reconciliation across diverse environments by abstracting source and target technologies, schemas, and formats with a simple UI for mapping sources and targets.
By handling pipelines that integrate multiple sources and/or targets and those that include aggregations, engineered features, and other transformations can be performed.
For each reconciliation policy, a data engineer names the data source and destination, the type of comparison to be performed, and the comparisons to check. Results are displayed in dashboards and may send an alert to a person or trigger a process for prompt action.
Data Pipeline Monitoring
Data engineers use the Acceldata platform to get visibility into their data pipelines and can identify the key components of each data pipeline they want to observe. This includes source, destination, flow, processing steps, and overall workflow.
Acceldata integrates into open-source workflow management tools for data pipelines, such as Apache Airflow. Airflow returns results to a dashboard, enabling a data engineer to see the data pipeline flow. The dashboard shows event errors and warnings and provides insight into the timeline of when and how events were executed. This enables data teams to track the reliability of a particular span in the data pipeline workflow.
With Acceldata, data teams can track data lineage across complex data pipelines, allowing them to visualize and understand the origin of data, what happens to the data as it is processed, and where the data is moved over time.
Data Pipeline Perfromance Analysis and Data Drill-down in Acceldata
All Type of Data at Various States
Acceldata works with all your data assets in all their various states - data-at-rest, data-in-motion, and data-for-consumption - and in a variety of data formats. This provides complete visibility into your data through all stages of your data supply chain.
By supporting these various states of the data across your data pipelines, data teams can “shift left” in data quality with Acceldata by identifying and isolating quality issues in files and data assets before they hit the warehouse. Data engineers can use the data lineage to identify where problems occur within a data pipeline.
Customer Story: Global Leader in Financial Data
One of Acceldata’s customers, a global leader in financial data, faced uncertain issues in improving and scaling their data products and comply with data regulations. Acceldata allowed this organization to bring their data products to market faster and, at the same time, comply with the ever growing set of regulations on the data produced.
In addition, using Acceldata, this organization was able to improve engineering outcomes using data reliability automation with the following results:
Can now comply with FTC guidelines and avoid harsh penalties
Improved speed and accuracy of rule creation by 20x in a 4 PB environment
Faster quality checks of up to 1,100% faster (8 hours vs 4 days)
The ability to detect schema and attribute-based changes
Processing over 400 million business records and 30 petabytes of quality checks monthly
Conclusion
Acceldata is a comprehensive solution for data reliability and observability that is designed to help organizations eliminate their blind spots. With Acceldata, organizations have:
The ability to improve recency and data timeliness,
Visibility into resource utilization to help reduce the over-provisioning of cloud resources and reduce costs,
The ability to help optimize data processing and pipeline execution,
Easy automation of data quality at scale to deliver trust in the data, and
Insights into design trade-offs for even greater data pipeline optimization
About Acceldata
Acceldata is the market leader in enterprise data observability for the modern data stack. Founded in 2018, Campbell, CA-based Acceldata, enables data teams to build and operate great data products, eliminate complexity, and deliver reliable data efficiently.
Acceldata's solutions have been embraced by global enterprises, such as Oracle, PubMatic, PhonePe (Walmart), Verisk, Dun & Bradstreet, DBS, and many more. Acceldata investors include Insight Partners, March Capital, Lightspeed, Sorenson Ventures, and Emergent Ventures.









































.svg)
























































.png)
