Thanks to its ease of use, Snowflake consumption can increase quickly and can result in user demand outpacing administrative capacity to manage consumption, performance, and operational best practices. Acceldata has automated many of these critical aspects of Snowflake administration in our Data Observability platform. It gives Snowflake users and managed service providers the ability to effectively scale their data operations (DataOps) performance and cost.
Data Observability for Snowflake monitors the Snowflake Infrastructure, data pipelines connecting the Snowflake Infrastructure, and the reliability of the data flowing through those pipelines. This How To Guide walks you through how Data Observability for Snowflake can be used to optimize a Snowflake environment.
Enterprise Data Observability provides a framework for data teams to optimize the operational efficiency of modern data infrastructures across the interconnected areas of data infrastructure, data pipelines, data reliability, and data users. This How To Guide focuses on the Snowflake data infrastructure and will walk you through the four phases of implementing Acceldata Data Observability platform to optimize Snowflake:
Understand Snowflake consumption
Implement best practices
Perform a hot-cold optimization review
Enable a continuous health check for Snowflake
The Acceldata Data Observability platform helps data teams align Snowflake consumption to the business goals your team is using Snowflake to achieve. It enables automation for ongoing operations, and frees up skilled operation resources to focus on high-value tasks.
Acceldata is a Snowflake Technology partner, a Powered by Snowflake partner, and works closely with Snowflake product management and field teams to continually improve the breadth and depth of our Data Observability for Snowflake solution. The Acceldata platform provides data insights into a client’s Snowflake deployment and delivers highly responsive observability analysis based on historical Snowflake meta data. The continuous health check provided by data observability provides DataOps teams with alerts they can use to remediate issues within their data infrastructure, regardless of whether they occur within the Snowflake deployment, the pipelines connecting Snowflake, and/or the data flowing through the environment.
Using this Guide
This guide will help you optimize your Snowflake environment using the Acceldata Data Observability platform. Anyone with a Snowflake SnowPro Core certification should be able to use this guide to accelerate their usage of Acceldata to optimize a Snowflake deployment.
The guide organizes the process of optimizing Snowflake into four phases:
Consumption Visibility and Alignment
Snowflake Best Practices Analysis
Hot-Cold Optimization
Continuous Health Check
After your initial optimization, phases 1, 2, and 3 can be revisited at any time.
Since the Acceldata Data Observability platform is provided as a service, its capabilities are continuously evolving with each platform release. Attempts will be made to update this guide to correspond to platform releases. The version of the guide can be found in the footer and is in the following format:
The current version of the platform can be found under your user profile option on the left sidebar of the user interface (colored circle with your initials in it)
Under each screenshot in this guide is the path to that screen within the user interface. The first part of the path indicates the left hand menu option under which that screen lives.
Phase 1: Consumption Visibility and Alignment
Optimization starts with understanding the big picture of the Snowflake environment from an overall consumption perspective. This can also include breaking down that consumption and aligning it to the business group that owns each warehouse. This overall view of your Snowflake deployment helps you to understand the macro level consumption and identify areas where impact can be made quickly. We’ll begin with account consumption and forecasting.
Snowflake Account Consumption & Forecasting
If your enterprise has multiple Snowflake Accounts, Acceldata can connect to all of them and aggregate the operational view at an enterprise level while also restricted access via role-based access controls.
First, start with a view of the Organizational Cost summary and trend for all Snowflake accounts observed. This gives a broad historical view of consumption and how that breaks down by different Snowflake service charges. Figure 1 illustrates a contract-level view in the top row. The middle row shows a breakdown of current consumption cost by Snowflake Services and by account. The bottom row shows forecasted consumption between now and end of contract by service and by account.
You can drill into each account individually. Figure 2 shows costs broken down by specific services over any specified period for which consumption has been observed. Snowflake saves historical account data for one year; anything older than one year is discarded. Acceldata can extract any amount of the Snowflake historical data for analysis. Once connected to your Snowflake environment, account data is extracted regularly and added to the initial historical data. This allows for historical analysis of your Snowflake environment for periods longer than Snowflake’s historical max. Figure 2 shows historical consumption for a full year and adds clarity to assumptions of service consumption ratios.
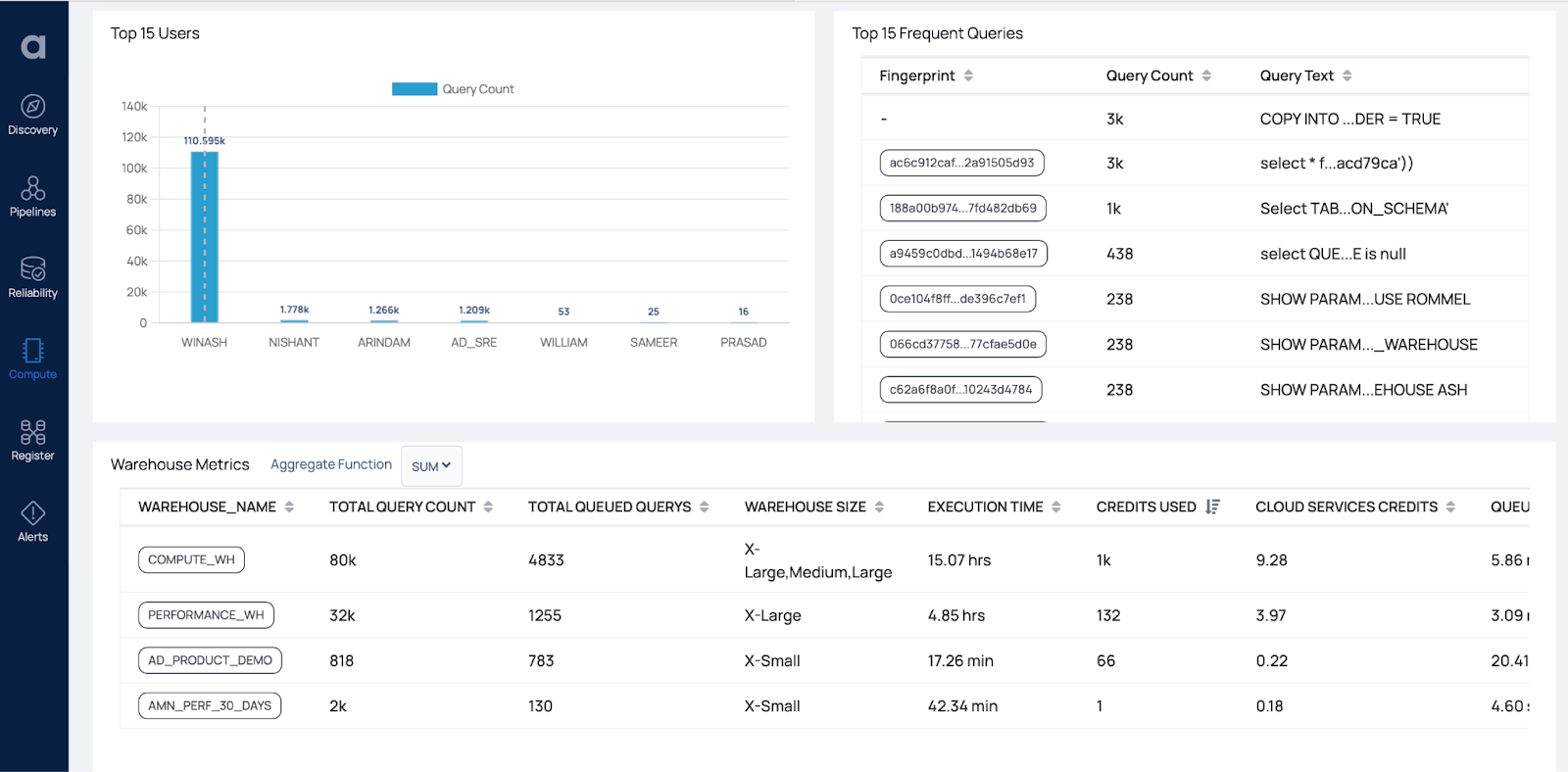
You can also view costs as consumed by individual Snowflake users. Figure 3 shows usage cost relative to an individual user’s activity as well as the activity volume to help identify anomalous user consumption. Acceldata also provides additional analysis of that user’s queries in the Query Studio (see Phase 3, Hot: Query Analysis section for more details about Query Studio).
These top-level views of the Snowflake environment become the baseline for any optimization and help you understand not only where to focus the deeper optimization efforts, but also quickly visualize the consumption impacts those optimization efforts drive.
Snowflake Consumption Across Business Units
Many shared services teams need to be able to track and report consumption to the individual business units within their organization. Acceldata supports this by aggregating consumption data across all configured data infrastructure observability connections within your account.
Figure 4. Path: Compute / Chargeback
Snowflake costs can be assigned to different units of an organization. If Snowflake tags are used, those tags can be used to auto assign resources to organization units. Once the organization units are configured, historic costs analysis by organization units is available with high consumption areas highlighted. This allows you to quickly prioritize organization unit consumption to prioritize for regular optimization reviews.
Creating and Tracking Business Unit Budgets
Figure 5. Path: Compute / Chargeback / Budgets
Early Release Feature: The new Budgeting feature allows you to set budgets per your business unit requirements. Once you set a budget, you can monitor your expenses and check how close you are to reaching it. Alerts can also be set for when your expenditures near your budget value. Budget configuration flexibility supports multiple budgets for each department to support departmental team budgets or multiple budgets for each quarter.
Phase 2: Snowflake Best Practices Analysis
As Snowflake environments scale quickly in usage, the overall configuration of Snowflake and warehouses can drift out of alignment with Snowflake’s recommended best practices. Acceldata automatically scans the configurations of the Snowflake environment, compares them to published Snowflake best practices, and highlights configurations that should be changed to align with these best practices.
System-Level Guardrails
There are many Snowflake system-level defaults and warehouse-level defaults that should have adjusted resource monitors set against them. This creates guardrails against consumption anomalies that can create surprise consumption spikes or recurring consumption waste within your Snowflake environment.
Figure 6 shows resource monitors that have not been configured (red warning icon on the left). Defining these resource monitors in Snowflake enables these guardrails across your Snowflake deployment.
High Churn Tables
Storage expenses for larger dimension tables that experience high levels of change can be substantial. These tables may come with high costs related to features such as failsafe/time-travel, auto-clustering, and materialized views. These serverless features are activated automatically in the background and billed according to the amount of work Snowflake performs, which is determined by how often the tables are modified. When these tables undergo multiple updates, all of the affected micro partitions are regenerated and then they proceed through the Snowflake storage cycle. As a result, tables that undergo frequent modifications, particularly high-churn dimension tables, can accumulate unforeseeable expenses.
Figure 7 identifies the top five most expensive high churn tables in your account. Clicking on a specific table, you can drill into the query details for that table in Query Studio. This allows you to quickly filter all the queries to that table to identify which queries are causing the high churn. This allows for quick evaluation of these queries to determine how they could be optimized to reduce churn. Converting a high churn table to a temporary or transient table or reduce the days of retention settings can help minimize the impact of the high churn table to your consumption (see Snowflake documentation, Managing Costs for Large, High-Churn Tables, for more details).
Figure 8. Path: Compute / Recommendations
The Acceldata Data Observability platform will also highlight high churn tables in the Recommendations summary page, as seen in Figure 8. Alerts can also be configured for the recommendations, which keeps your team aware of the latest recommendations as your Snowflake environment changes.
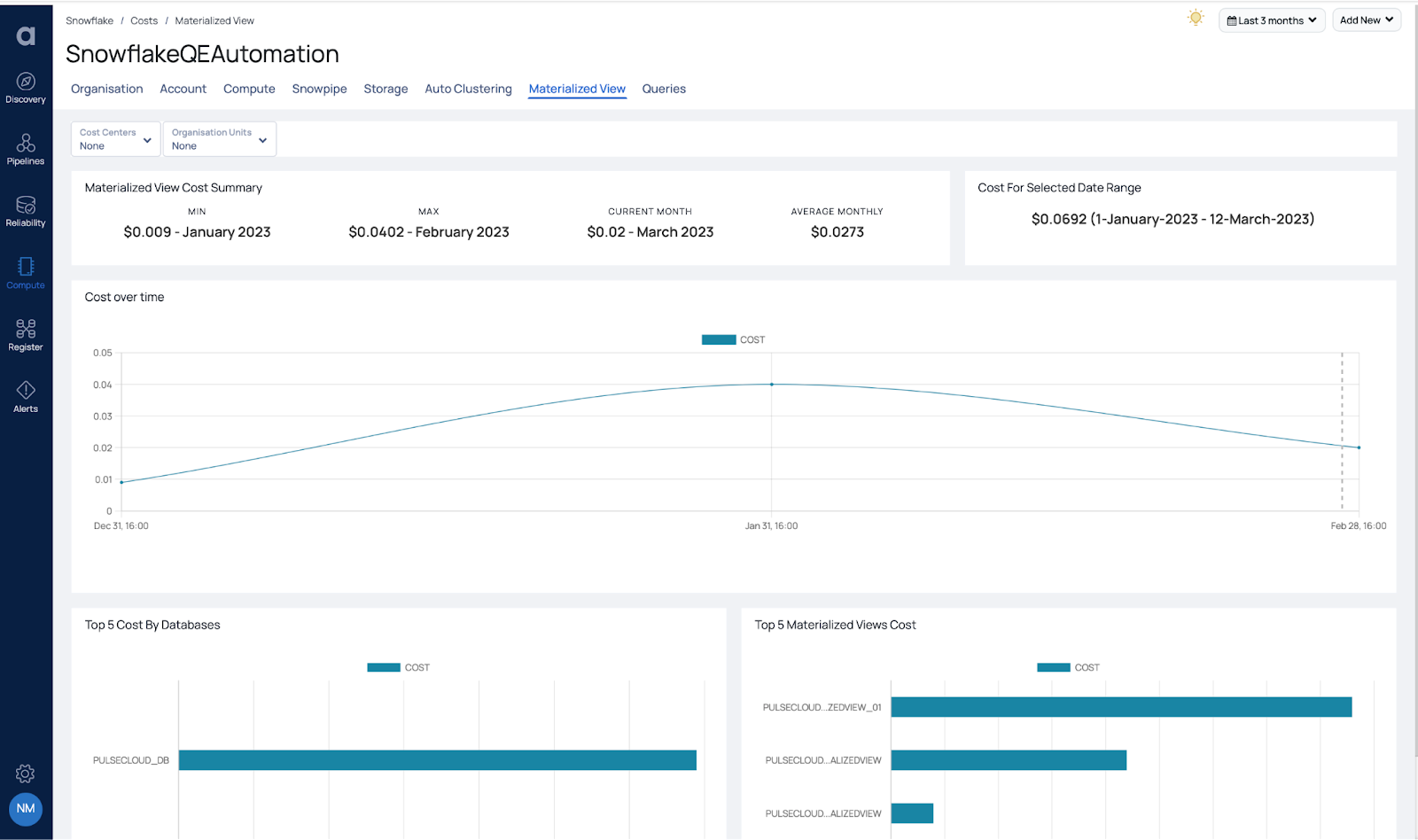
Materialized Views
A materialized view is a pre-calculated table obtained from a query definition and saved for future use. Whenever data is inserted or modified in the base table, the materialized view is automatically updated by Snowflake. Depending on the performance requirements, multiple views with similar insights can be generated using different clustering keys for the same base table. The principal disadvantage of utilizing materialized views is the extra expenses required to maintain separate materialized views. These include storage costs associated with creating a new copy of the data, fees for managing refreshes of each materialized view, and possible charges for automatic clustering on each materialized view. Thus, it is crucial for Snowflake users to take these additional expenses into account when utilizing materialized views.
In Figure 9, you can see the overall trend for the spend on Materialized Views and also the top five materialized views by cost. This allows data teams to perform a business analysis to determine the value being provided by the high cost Materialized Views. Based on this information, you can consider deleting low value Materialized Views to reduce consumption. Also, look at optimizing the update period for the tables behind the materialized view using tasks and streams to further optimize the cost of Materialized Views.
Snowflake Housekeeping
While usually not a significant contributor to consumption anomalies, the housekeeping items show below are called out to keep your Snowflake environment clean and protect you from future issues.
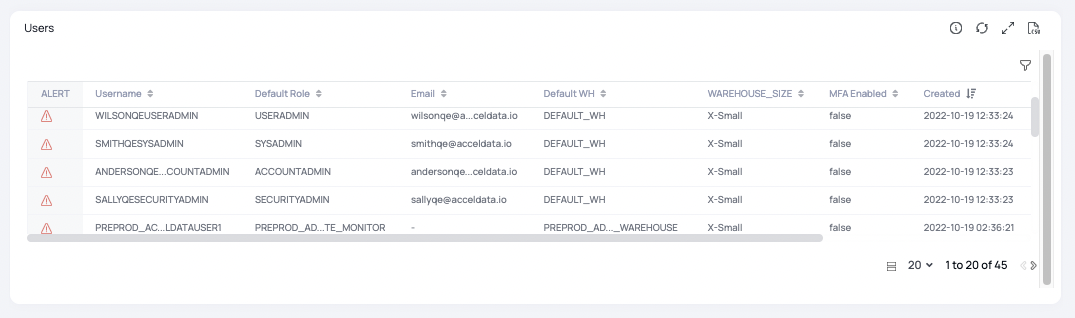
Snowflake user permission analysis highlights users that are not following best practices for various aspects of their account: no email address, wrong default role, multi-factor authentication not enabled, and other issues. These are user-related configurations that may lead to future issues with the Snowflake deployment, especially as usage starts to scale and users adoption grows rapidly.
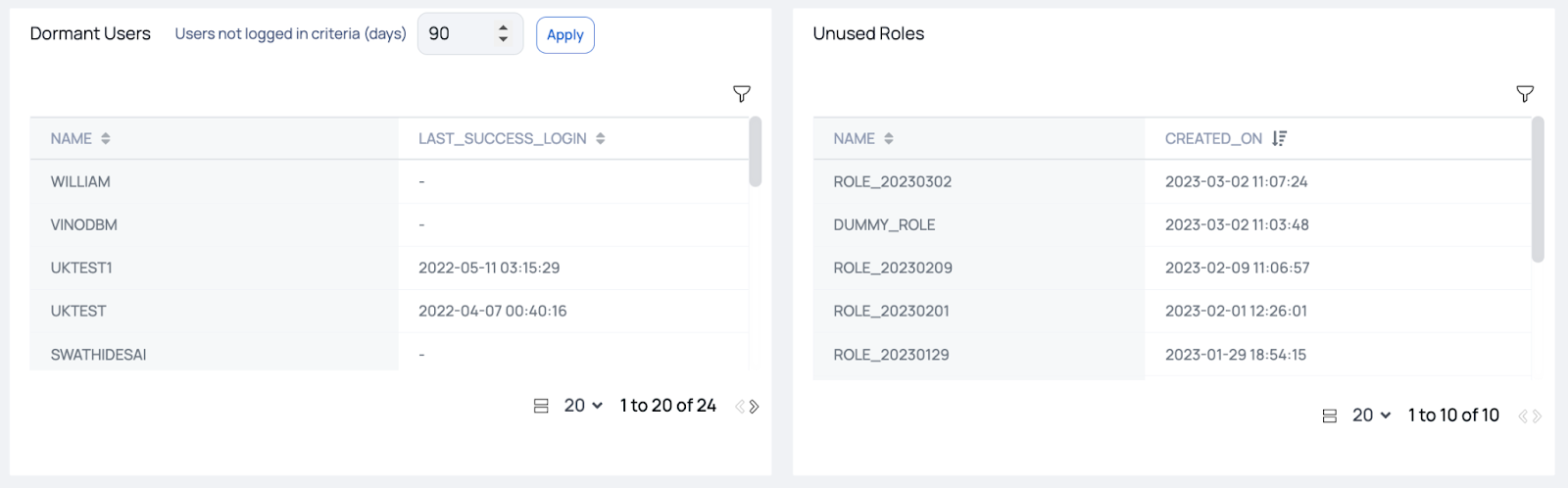
Analysis of dormant uses and unused roles protects your deployment from unauthorized access and unexpected consumption in the future. Cleaning up unused roles also protects your deployment from users accidentally getting access to warehouses that they should not have access to.
Users that are using deprecated drivers to connect to Snowflake are a future issue waiting to happen. To prevent these future connectivity issues to Snowflake, these users should be upgrading their drivers as soon as possible.
Phase 3: Hot-Cold Optimization
Hot-cold optimization reviews the most active (hot) and least active (cold) usage areas of your Snowflake deployment. Optimizing the hot areas has the biggest immediate impact on consumption. Cleaning up the cold areas prevents vampire costs from draining your budget month after month.
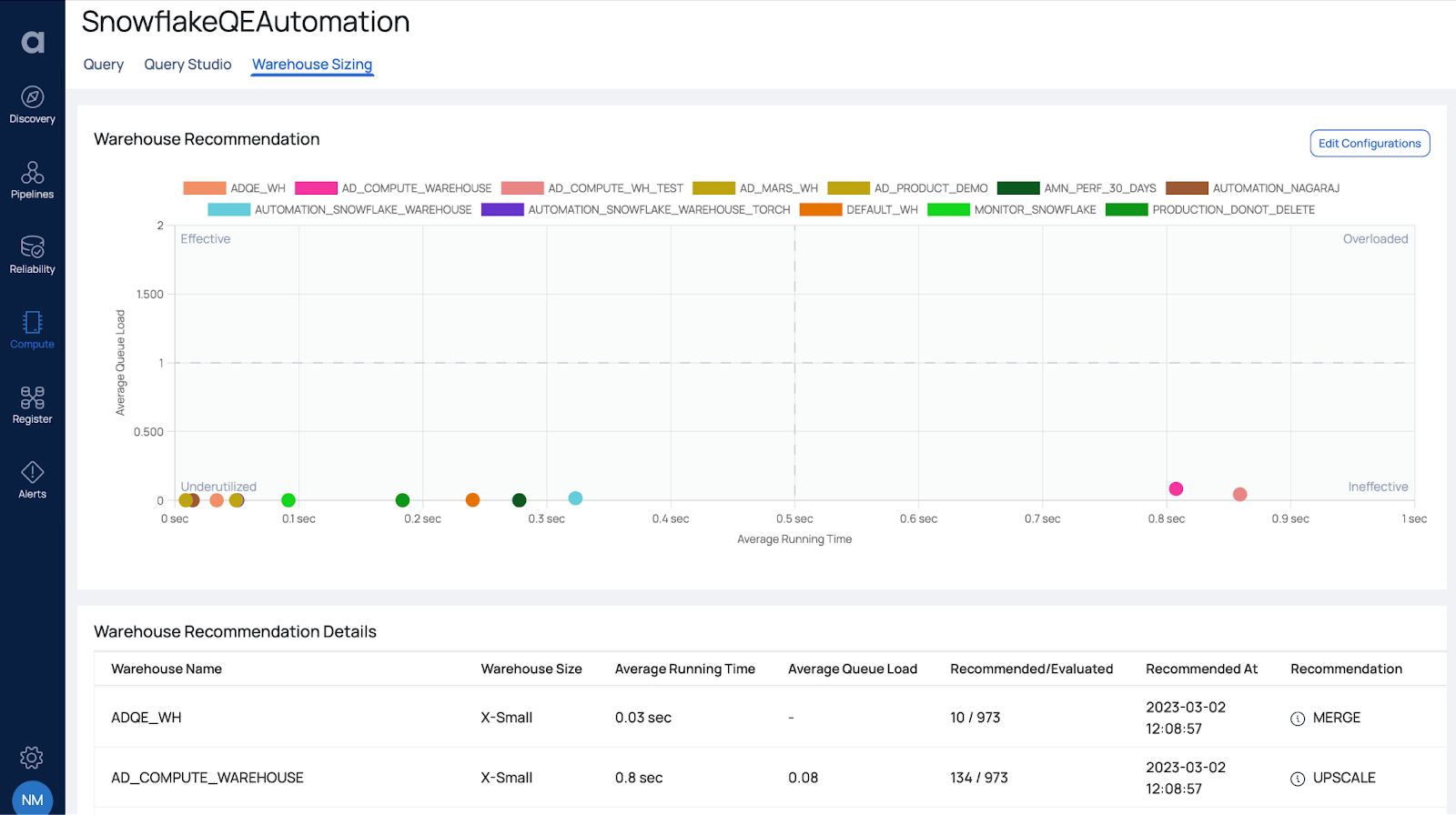
Early Release Feature: Use the warehouse sizing analysis to review suggestions for optimizing the utilization of your Snowflake warehouses. Among other things, this provides:
Assessment of the average queue size
Assessment of average running time of your warehouses
A list of recommendations to optimize the warehouses
At the top of the page, you can view the performance of your warehouses in relation to the baseline latency and queue load expectations. If you need to modify these values, simply click on the Edit Configuration button. The chart displays the placement of the warehouses in their respective quadrants, based on the observed latency/load compared to the expected latency/load. Ideally, all warehouses should be in the Effective quadrant, while those in the Ineffective, Overloaded, and Underutilized quadrants need to be optimized. You can refer to the recommendations provided in the Warehouse Recommendation Details table for guidance. With the appropriate configuration, you can also update the warehouse size directly from the recommendation table.
Next you identify the warehouses that have the highest cost. These are the initial targets for deeper optimization review, as even small increases in efficiency can result in substantial cost savings. Figure 14 shows analysis that identifies the warehouses with the highest cost in Snowflake Credits consumed, as well as other utilization metrics that drive consumption. You can also see who the top users (by query count) are, and also which query workloads (grouped together via fingerprinting) are dominant for the selected warehouses. Click on the query fingerprint or the warehouse name buttons to go to a filtered query view for further analysis and debugging.
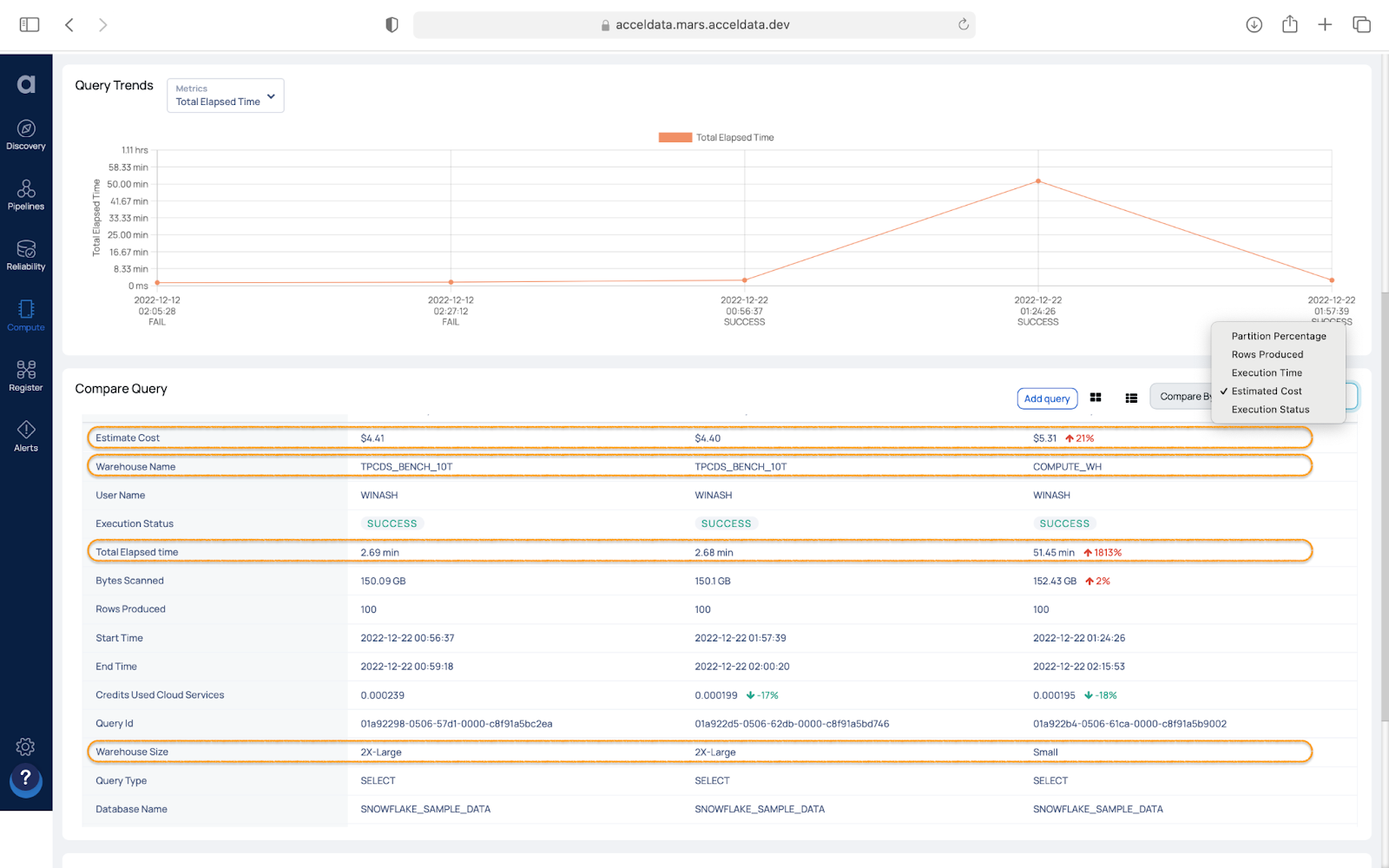
Figure 15. Path: Compute / Snowflake: Query Studio / Query Studio / Query Details
Additionally, when preparing to deploy a new warehouse, Snowflake suggests experimenting with running queries on warehouses of various sizes to determine the optimal warehouse size for your needs. Understanding the workload trends and comparing test queries side-by-side can help determine the appropriate size of a warehouse. When performing this exercise the Query Studio can be used to compare successive runs of the same query across different sized warehouses. Figure 15 shows that running the same TPC-DS benchmark query on different warehouse sizes shows that the query performs much better (the middle highlight shows completion in almost 1/20th the time) and is also more cost-effective (the top highlight shows it costs 21% less to complete the query) on the X-Large warehouse compared to the Small warehouse (right most column).
Hot: Query Analysis
The Acceldata Data Observability platform utilizes query history metadata and query fingerprinting techniques to group similar queries together. This provides a deeper understanding of your workloads and identifies the most demanding queries. Query fingerprinting enables insight into the execution frequency, cost, average latency, and schedule/frequency of the grouped queries within a selected interval. Query grouping can also be used to help identify the optimal data layout or partition clustering for a specific workload.
Figure 16. Path: Compute / Snowflake: Query Studio / Query Studio
Start with the overview analysis about the performance of all queries, as it can often point to warehouses with high cost queries, databases where most of the queries are running, or the dominant users of failed queries. But the analysis can also display the Top 50 Long Running Queries, the Top 50 Queries with Heavy Scans, the Top 50 Queries with Spillage, and other high cost categories for a selected time range. These lists help you quickly focus on the most expensive queries and their corresponding warehouse that should be reviewed for optimization.
Next, we can use Query Studio for insights into the most expensive queries. Double clicking on the query provides a historical analysis of the query’s trend, best and worst performing runs, the warehouse runtime state, and query execution state to help optimize the query execution.
Using Query Studio, you can also figure out which queries are frequently executed by setting the Query Grouping dropdown to Fingerprint. More often than not, you will find queries that are executed more frequently than the need of the application dictates. Use the Measure-Understand-Optimize features of Query Studio as a framework to continuous query optimization.
Cold: Identifying Stale Assets
To optimize Snowflake storage costs, users should delete unused tables, idle warehouses, and materialized views. Acceldata automatically identifies and calls out the most costly of these cold assets.
Figure 18 shows identification and analysis of unused tables and tables that have not been queried in the past 90 days (based on system default). The largest tables, and thus the ones costing you the most, are highlighted with the warning icon in the left hand column. These tables should be reviewed and prioritized for deletion to optimize your storage costs.
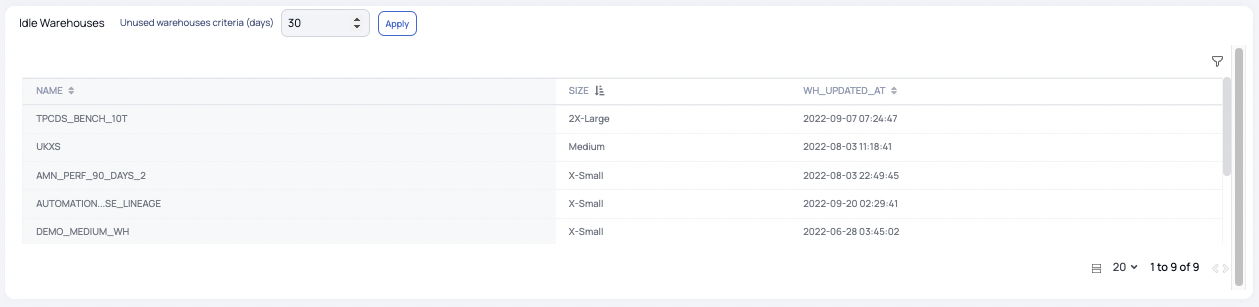
Warehouses that are idled for longer than a certain time with no usage should be considered for deletion. If auto-suspend is configured for these warehouses the cost is greatly reduced, but the housekeeping best practice is to delete them. This report highlights warehouses that have been idle for more than 30 days (based on system default). A business use case case review should be performed and unneeded warehouses deleted.
Unused Materialized Views can still generate costs for your organization if the underlying data is being updated regularly. This is especially true if multiple Materialized Views were created on the same data sets but only one was put into production. Figure 20 shows analysis of all unused Materialized Views within your deployment. The rightmost column describes the view type to help determine the cost implications of each view,
Phase 4: Continuous Health Check
Defining Monitors for the Future
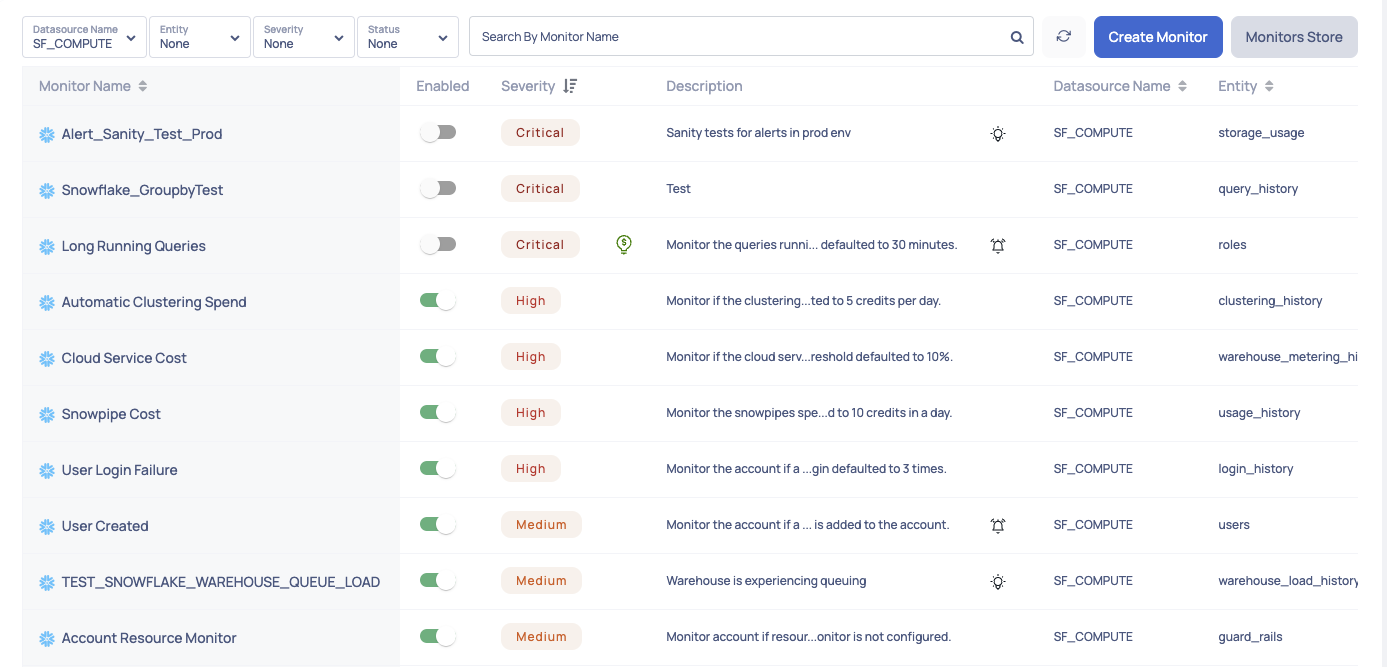
Figure 21. Path: Compute / Monitors / Monitors List
Acceldata features a broad set of default monitors for Snowflake out of the box, as seen in Figure 21. Additional monitors are continuously being added and can be brought into your Acceldata instance from the Monitor Store. These monitors apply to specific Snowflake entity types and monitor all deployments of that entity type across your Snowflake implementation. This is done by conducting a continuous health check on usage, cost, performance, and other critical activities occurring across your account. When a monitor is tripped, it sends an alert to the associated alert channel.
As unique business situations arise within your Snowflake environment, you can create new monitors within Acceldata. Figure 22 shows the Create Monitors screen, which is used to define complex logic and thresholds related to a monitor. Additionally, with the appropriate permissions, you can also choose to implement auto actions to be run when a monitor trips.
Integrating Alerts into Your Operations
Figure 23. Path: Alerts
When a monitor trips, it generates an alert. These alerts are archived within Acceldata, as seen above on the Alert page, but most teams want these alerts routed to them using their team’s default alerting process. This could be a Slack channel, ticketing system like Jira or ServiceNow, messaging system, email, or other system. This is achieved by configuring notification channels for different types of alerts.
Figure 24. Path: Settings / Notification Channels
The Notifications Channels page, Figure 24, shows you all configured notification channels for alerts. When an alert is triggered, all recipients who are members of the notification groups configured for that alert will receive a notification.The notification channels created here will appear in a dropdown menu on the notifications pages of the Compute sections.
Long-Term Snowflake Analysis
Snowflake keeps 365 days’ worth of historical performance and consumption data for every customer’s account. Querying this historical data for real-time analysis requires offloading this historical data from the Snowflake internal system to a warehouse dedicated to analysis. Acceldata does this automatically with your desired amount of historical data when you first connect to your Snowflake account; historical timeframes can be one week, one month, six months, or up to the full year stored in Snowflake. Once this historical data is populated into Acceldata, new performance data is added at regular intervals for as long as you want, enabling you to do historical analysis for longer than the Snowflake default of one year.
And now that you’ve completed your initial optimization of your Snowflake environment, the Acceldata Data Observability platform will continue to observe and alert you when:
Budgets are about to be exceeded or have been exceeded
Your overall Snowflake environment drifts from the Snowflake best practices
System level guardrails are close to be hit
New housekeeping items develop
Any of the default or customer Monitors are triggered
New optimization opportunities are detected
Essentially, Acceldata provides a continuous health check across your Snowflake environment.
Data Reliability Across Snowflake
Once your Snowflake environment is optimized, the Acceldata Data Observability platform can also help you optimize the reliability and quality of the data inside your Snowflake warehouses, back at the data sources, or within your ingest pipelines with the platform's data reliability capabilities. Acceldata data quality monitoring allows you to shift your view further left; to catch bad data as close to the data source as possible, where it is less expensive to fix, and before it can cause issues for the Snowflake data consumers.
First you can understand the most used tables across your Snowflake deployment with the Table Access heat map, which is shown in Figure 25. Once an Acceldata Data Plane is deployed close to your Snowflake deployment, data reliability can profile your most-used tables and recommend a set of data quality or data reliability rules based on the data in those tables.
Those rules can be run at a regular schedule across the data at rest in Snowflake, and the platform will calculate a data quality score for each table. Those same rules can also be called via APIs to monitor data in motion, allowing you to apply data quality to your Snowflake ingest pipelines. No additional rule configuration needed!
Figure 26. Path: Reliability / Data Performance
The Acceldata Data Observability platform can now combine observability data from the Snowflake infrastructure with data reliability insights to provide even more unique analysis, like the usage versus data reliability graph shown in Figure 26. You can quickly see if there are any data sets that drift into the red upper left quadrant, where they are being highly accessed but are also suffering from poor data quality.
Additional Data Planes can be deployed to continue to shift your view left back to the data sources. This gives you an operational view of data problems that allows your team to be even more proactive. The data quality that Acceldata calculates can also be shared with enterprise data catalogs and data governance tools.
Operating with Data Observability
Now your Snowflake deployment is optimized and able to operate with continuous operational and data health checks. Your data quality is being measured and bad data is being stopped before it reaches Snowflake. You and your team are now successfully operating a Snowflake-powered data product and you can focus on helping your enterprise build even more valuable data products for the future.









































.svg)


















































.png)