We are using power of Acceldata for our data quality issues. Its integration is simple and we are able to identify various data quality issues quite easily.
Timothy C.
Senior Expert of Data Governance - Enterprise
Acceldata has opened quite a few doors for us at Nestle. We have started with the Data Reliability features of the product and moved into the Cloud/Cost Optimization aspects.
Jayanth Reddy G.
Senior DevOps Engineer - Enterprise
This combination of usability, seamless integration, and robust features makes Acceldata a powerful tool for enhancing data reliability and performance.
Mark. H
Manager Data Warehouse Operations - Enterprise
Onboarding our data into Acceldata was very quick and simple. Within 24 hours all production data was loaded and trends were easily established.
Chidambararajan M.
IT Consultant - Enterprise
Acceldata is giving the better quality checks for the data sources and the maintenance of the environment is good.
Prashanth. S
Director, Platform Engineering and Data Operations - Enterprise
Acceldata has been instrumental in enhancing our data platform management capabilities. Their solutions not only ensure platform stability but also drive significant cost savings.
As businesses navigate external changes, embrace new work methodologies, and grapple with escalating data volumes, the importance of establishing and managing an optimal data environment is critical for every organization. Effective data management encompasses all stages of treating data as a valuable, reliable asset, from identifying and integrating data sources, to managing data pipelines, and through all aspects of data performance.
Facilitating a consistent and dependable flow of data across individuals, teams, and business functions is one of the most essential components of any organization and is a fundamental driver of competitiveness and innovation. To gain accurate insights into how companies are tackling data-related hurdles, it is crucial to assess their approaches and strategies through the lens of all aspects of their data activity. This includes establishing operational intelligence and ensuring continuous data reliability, and because of the major investments made in data infrastructure, it also means that data teams must be dedicated to the practice of Cost Optimization.
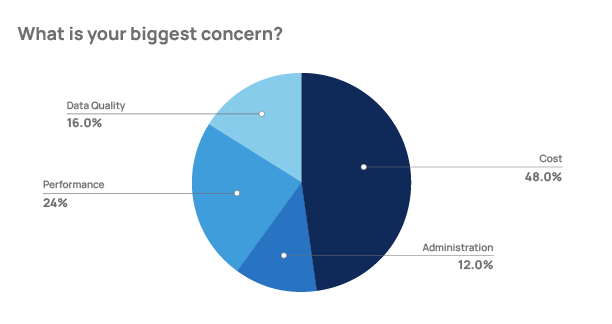
Cost is Top Concern for Data Leaders in Data Warehousing
In September 2022, Censuswide conducted a survey of data engineers, chief data officers, and other members of enterprise data teams to get insights into their data environments and the role that cloud data warehouses (including Snowflake, Databricks, Amazon RedShift, and Google BigQuery) play in their data strategies. In a series of questions about their overall data and business operations, the survey findings provided valuable insights about the expectations that data leaders have for their data stacks, and they highlight the key concerns of data teams regarding data quality, reliability, and manageability.
Perhaps the most striking outcome of the survey was that the biggest concern for data leaders is cost. You can see in the results below that almost half of these data leaders cite cost-related concerns as their top priority.
An intriguing aspect of this specific metric is its intrinsic connection to two other prominent concerns: data quality and performance. Remarkably, when an organization achieves consistent data quality, they often experience a significant enhancement in performance, leading to improved resource efficiency and a more favorable cost-to-value ratio. These interdependencies highlight the interplay among data quality, performance, and cost, emphasizing the importance of addressing these factors collectively for optimal outcomes.
There are unique aspects to cost control for companies who use the cloud, because, while the cloud delivers incredible operational efficiencies for workloads and data sources, it has also proven to be costly. Cloud providers and cloud data warehouses use pricing strategies intended to align with usage and performance, but without observability into data usage and activity, enterprise data teams often struggle to know where their data is, how it’s being used, and what they’re paying for.
The Promise of the Cloud Does Not Include Spend Controls
Cloud computing has undeniably emerged as a transformative force in the history of computing. With its unparalleled advantages such as unlimited scalability, flexible cost structures, and rapid time-to-market, cloud providers and cloud applications have become the fundamental backbone of modern digital businesses. Consequently, the market has witnessed exponential growth over the past decade as startups and enterprises eagerly migrated their workloads to the promising realm of the cloud.
However, as time has passed, the once-mythical perception of the cloud has shown some cracks. Organizations now find themselves grappling with unpleasant surprises in the form of unexpected bills, rigid contractual obligations, and soaring cloud egress costs. Companies regularly get staggeringly high bills for activities they didn’t know they had used. The financial impact can be pronounced, as these costs are unexpected and usually not budgeted for.
Cloud environment management operations can lead to unexpected costs due to several factors:
Storage Costs: Tools like Snowflake and Databricks charge for the storage space used to store data. If your data volume grows significantly or if you retain data for a long time, storage costs can accumulate.
Compute Costs: Many tools employ a pay-per-use model for computing resources. If your workloads require a high level of computational power or if you run complex queries frequently, it can result in increased compute costs.
Unused or Idle Resources: Cloud resources that are provisioned but not actively utilized can incur costs. Instances, storage, and other resources left idle or forgotten can accumulate charges over time (and it’s easy to forget about these because of “set and forget” default settings that are common in cloud environments).
Overprovisioning: Overestimating resource requirements and provisioning more capacity than necessary can result in higher costs. Paying for unused resources or maintaining larger instances than needed can significantly impact the budget.
Lack of Cost Optimization: Failure to implement cost optimization strategies can lead to inefficient resource usage and increased expenses. This includes not leveraging discounted pricing options, using inefficient storage options, or running underutilized instances continuously.
Data Transfer and Egress Costs: Moving data in and out of cloud environments and applications can incur additional charges, especially when dealing with large volumes of data or transferring data across different regions or cloud tools.
Ineffective Governance and Monitoring: Insufficient governance practices and monitoring mechanisms can result in uncontrolled spending. Without proper visibility into resource utilization, cost allocation, and monitoring of cloud services, it becomes challenging to identify cost anomalies or optimize resource usage.
Lack of Auto-Scaling and Automation: Failing to implement auto-scaling mechanisms or automated resource management can lead to inefficient resource allocation. Without dynamically adjusting resources based on demand, organizations may overspend on unnecessary capacity during periods of low usage.
Complex Pricing Models: Many cloud tools offer a range of pricing models, such as on-demand, reserved instances, spot instances, and different tiers of storage. Understanding and optimizing these pricing models can be challenging, leading to potential cost inefficiencies.
To mitigate these unexpected costs, it is crucial to implement effective cost management strategies, closely monitor resource utilization, leverage automation and scaling capabilities, optimize storage and data transfer, and regularly review and adjust resource provisioning based on actual needs.
Organizations now find themselves grappling with unpleasant surprises in the form of unexpected bills, rigid contractual obligations, and soaring cloud egress costs…
Doing all of that while managing an effective data environment requires the insights about Cost Optimization that can only be provided with data observability.
Optimizing Cloud Costs with Cost Optimization
Companies require Cost Optimization for their cloud environments to effectively manage and optimize their cloud costs. That includes all aspects of cloud data operations and orchestration. This is no longer an accompanying component for cloud users, but a necessity that enables data teams to maximize their cloud data investments and support their organizational needs. Here are a few key reasons why Cost Optimization is crucial:
Cost Optimization: Cloud services often involve complex pricing structures and multiple cost components. Cost Optimization provides visibility into how cloud resources are being utilized and helps identify areas of inefficiency or excessive spending. By analyzing spending patterns and trends, companies can make informed decisions to optimize their cloud costs, eliminate wasteful expenditures, and ensure better resource allocation.
Budget Planning: Understanding and predicting cloud costs is essential for accurate budget planning. Cost Optimization enables companies to track and forecast their cloud spending, allowing them to allocate resources and plan budgets accordingly. It helps businesses avoid unexpected cost overruns and align their spending with their financial goals and projections.
Resource Rightsizing: Cost Optimization provides insights into resource utilization, allowing companies to identify underutilized or idle cloud resources. By optimizing resource allocation, businesses can reduce costs by rightsizing their infrastructure, scaling resources based on demand, and maximizing the efficiency of their cloud investments.
Cost Accountability: With multiple teams and individuals accessing cloud resources, it's important to have cost accountability. Cost Optimization helps track and allocate costs to specific departments, projects, or users, enabling companies to understand which areas or teams are driving the majority of cloud expenses. This information can facilitate cost allocation, financial transparency, and effective cost management across the organization.
Overall, Cost Optimization empowers companies to gain control over their cloud costs, make data-driven decisions, optimize resource allocation, and align cloud spending with business objectives. It plays a crucial role in maximizing the value of cloud investments while maintaining cost efficiency and financial sustainability.
Understand How Data Warehouse Management Affects Compute Costs
Let’s look at this from the perspective of Snowflake users. As you probably are aware, Snowflake is a widely popular SaaS platform that offers robust data warehousing capabilities and services, and it has become almost obligatory for modern data operations.
Like most service providers, Snowflake follows either a flat fee or a usage-based pricing model. As a flexible cloud-computing provider, Snowflake enables users to effectively manage and control costs by overseeing three key functions:
Storage
Compute
Cloud Services
The reason why Snowflake illustrates these cost-related issues so well is because Snowflake users often face challenges when it comes to gaining visibility into the data activity within their environment. This lack of visibility can give rise to various issues related to data performance, data quality, and cost management.
Without a comprehensive understanding of how data is functioning and without awareness of the cost implications of operating within Snowflake, data teams run the risk of overspending or underutilizing this crucial component of their data infrastructure.
There is growing recognition among data teams about the positive impact of data observability as a critical factor in achieving data optimization goals. What these people also recognize is that implementing data observability within Snowflake environments empowers data teams of all sizes to specifically improve the cost-effectiveness and performance of their data investments.
Snowflake Cost Insights
In Snowflake's service, the compute and cloud services stages involve loading data into the virtual warehouse and executing queries, which are billed to the customer in the form of Snowflake credits. On the other hand, data storage is charged based on a flat-rate fee determined by expected monthly usage.
Customers have the flexibility to purchase storage and Snowflake credits on-demand or in advance, depending on their working capacity and requirements.
You can see here how this all plays out in Snowflake.
Analyze How Much You’re Currently Paying for Cloud Data Warehousing
Let’s back up and remember that, a decade ago, the cost-benefit ratio of building a data warehouse was not particularly favorable. At that time, most data warehouses were constructed from scratch and deployed on-premises. This involved significant expenses related to hardware, software, and the personnel needed to manage them. Even if the data warehouse was hosted externally, you still had to invest in the necessary hardware and software for its operation.
For large organizations, building a data warehouse remained a worthwhile investment. Despite being costly, the primary focus was on the valuable business insights derived from analyzing vast amounts of data. However, the majority of the budget was allocated to overhead expenses.
Fortunately, the landscape has transformed today, leading to significantly reduced data warehouse costs. The emergence of Data Warehouse as a Service (DWaaS) providers like Redshift, BigQuery, and Azure has led to lower infrastructure expenses. Additionally, some of the complexities associated with setup and maintenance are now managed by these services. Furthermore, comprehensive DWaaS solutions like Panoply have contributed to a significant drop in both setup and maintenance costs.
As a result, utilizing a modern data warehouse enables organizations to allocate fewer resources to overhead expenses and focus more on extracting valuable insights from their business data. These insights can make a substantial difference between failure and success.
But as we’ve established, managing cloud data warehouse costs is challenging because cloud environments are complex. Here are the primary areas where costs are incurred:
Storage Costs
Determining storage costs within the Snowflake platform follows a relatively straightforward pricing model. Most customers are billed a standalone fee of approximately $23 per month per terabyte (TB) of data, which is accrued on a daily basis. However, it's important to note that different customers may have slightly varied rates based on their specific contractual agreements and obligations with Snowflake. For instance, a customer utilizing Azure in Zurich, Switzerland, would have a fixed rate of $50.50 per TB per month, while another customer in Washington would pay $40 per TB per month on demand.
Compute Costs
Snowflake offers two options for calculating compute costs: on-demand or pre-purchasing capacity. Opting for on-demand means you pay only for the services you utilize. Snowflake calculates the total cost of the resources you provisioned throughout the month, and payment is made retrospectively.
This is where the Snowflake credit system comes into play. Each credit is associated with a specific rate, which typically falls within the range of $2.50 to $6.50 per credit. The actual rate depends on factors such as the region, criticality of function, and the chosen cloud service provider.
Virtual Warehouse Credit Usage
In simple terms, this refers to the cost incurred when executing queries, loading data, or performing data operations on multiple compute clusters. The total cost is determined by the size of the warehouse on which the query is run and the time taken to execute the query.
For example, Snowflake also offers customers data warehouses of varying sizes, allowing them to run queries on increasingly powerful warehouses for enhanced performance. However, it's important to note that the credits consumed per hour are dependent on the size of the warehouse. The following illustration provides an overview of the credit usage based on warehouse size.
To determine the cost of running a single query, we can utilize the credit usage per hour cost provided above and multiply it by the elapsed time (T) taken to execute the query. hi
This resulting value is then multiplied by the cost of each credit, which is specified in the customer agreement.
While this cost may appear relatively small when considering the overall expenses of running a data environment, it can quickly escalate as operations grow in size and scale. Large enterprises and conglomerates often run thousands of queries per day, leading to substantial costs. It typically breaks down like this:
Credit Usage = (Credit Usage per Hour) × (Elapsed Time [in hours]) × (Cost per Credit)
Let's consider a scenario where a query runs on an extra-large warehouse for 300 seconds. Since time is measured in hours, T = 300/3600 = 0.083 hours. Assuming the cost per credit is $3, the credit usage cost would be 16 × 0.083 × 3 = $3.98 per query.
Note: Even if a query runs for only five seconds, Snowflake charges a minimum of one minute.
How Data Observability Helps Optimize Cloud Costs
Data observability plays a crucial role in optimizing cloud data warehousing cost control by providing organizations with enhanced visibility and insights into their data pipelines, usage patterns, and overall data ecosystem. Here's how data observability contributes to cost optimization:
Resource Utilization: Data observability tools monitor and analyze resource utilization within the data warehouse environment. They provide valuable insights into resource allocation, usage patterns, and bottlenecks. By identifying underutilized resources or inefficient query execution, organizations can optimize resource allocation, right-size their infrastructure, and avoid unnecessary costs.
Query Performance Optimization: Data observability helps identify poorly performing queries, query patterns, or data processing bottlenecks. By analyzing query execution plans, query runtime, and data access patterns, organizations can identify opportunities to optimize query performance. This optimization not only improves data processing efficiency but also reduces the cost associated with query execution, as faster queries consume fewer resources.
Data Quality and Governance: Data observability tools monitor and assess the quality, consistency, and reliability of data within the data warehouse. By detecting anomalies, data discrepancies, and data quality issues, organizations can proactively address data integrity issues that can impact query results and decision-making. Ensuring data quality and governance minimizes the risk of costly errors and rework.
Cost Monitoring and Analysis: Data observability platforms provide cost monitoring and analysis capabilities specifically tailored to cloud data warehousing environments. They track data processing costs, storage costs, and other related expenses. By visualizing cost trends, identifying cost drivers, and analyzing cost patterns, organizations gain actionable insights to optimize spending and identify areas for cost reduction.
Anomaly Detection and Alerts: Data observability tools employ anomaly detection techniques to identify unusual data behavior, unexpected cost spikes, or inefficient resource utilization. Real-time alerts enable organizations to promptly address and investigate anomalies, preventing potential cost escalations and optimizing resource usage.
Continuous Improvement and Iterative Optimization: Data observability fosters a culture of continuous improvement by providing ongoing visibility into data operations and costs. Through iterative analysis, organizations can identify opportunities for optimization, implement changes, and measure the impact on cost control. This iterative approach ensures that cost optimization efforts are data-driven and continuously refined.
Data observability provides continuous monitoring and analysis of your data infrastructure, allowing you to gain valuable insights into its performance, efficiency, and resource utilization. With these insights, you can identify areas of wastage or inefficiency and take proactive measures to address them.
By leveraging data observability practices and tools, organizations can gain comprehensive insights into their cloud data warehousing environment. This enables them to optimize resource utilization, improve query performance, ensure data quality, monitor costs, and drive continuous cost optimization initiatives for more efficient and cost-effective operations. Specifically, data observability addresses cost and spend issues in these ways:
Optimizing Resource Performance
Implementing standard practices is crucial for optimizing a business's data resources and maintaining data quality. For example, enabling auto-suspend for virtual warehouses ensures they pause when not processing queries, reducing unnecessary costs. Filtering out irrelevant data minimizes the workload and improves efficiency.
Data observability plays a vital role by providing real-time alerts when deviations from established standards and best practices occur. It notifies users when data is being processed inappropriately or when timeouts are missing from requests and queries.
Think about it this way: data observability facilitates the analysis and management of bottlenecks, data spillage, compilation time, data volume, and resource allocation, ensuring optimal data quality and efficient utilization. It helps identify and address issues related to latency, enabling companies to proactively resolve them. Additionally, it aids in planning for potential failures in the data architecture.
Acceldata offers a comprehensive data observability platform that enables businesses to track the performance and quality of their data pipelines within and outside of data tools like Snowflake and Databricks. By adhering to best practices, Acceldata ensures optimal cost management. Whenever violations occur, Acceldata promptly sends notifications and recommendations, helping businesses maintain compliance and maximize the value of their cloud data investment.
Provisioning Warehouse Usage
Over-provisioning is a persistent challenge in cloud services, often leading to performance inefficiencies. In Snowflake, for example, the size of your warehouse directly impacts the consumption of processing request credits. Larger warehouses offer faster response times but require more credits. In contrast, smaller warehouses consume fewer credits but may result in slower responses. Data observability empowers data teams to analyze and compare the advantages and disadvantages of different warehouse sizes. This enables informed adjustments based on the unique requirements of your enterprise, optimizing performance while effectively managing credits.
Optimizing Cloud Resources Usage
A common reason for unexpectedly high cloud expenses is a lack of visibility into the usage of cloud resources. Often, these resources are either left unused or overused, resulting in unnecessary costs. It's possible to unintentionally run test code on-demand, which adds little value to your business and wastes your budget. Alternatively, you might have purchased excessive capacity that remains unused, yet you continue to incur charges for it.
The key to optimizing cloud spend is understanding which resources to provision and their associated costs. Data observability offers valuable insights by examining factors such as data volume, update frequency, and usage patterns, providing recommendations on the most efficient utilization of cloud services.
Data observability also enables you to forecast and plan for cloud costs. Solutions like Acceldata offer comprehensive features, including contract planning, spend analysis (current and projected), department-level tracking, budgeting, and chargeback capabilities. By leveraging such tools, businesses can avoid the challenges often encountered during the transition to cloud platforms, ensuring cost-effectiveness and efficient resource allocation.
Acceldata: Enhancing Data Observability for Your Cloud Environments
Increasingly, companies are developing new revenue opportunities by commercializing their data into data products. If that data is not reliable, accurate, and accessible, it puts these companies at risk for revenue loss, poor customer experiences, and compliance violations.
The good news is that you have the power to optimize your cloud resources and tailor them to your budget and computing needs.
By implementing data observability in your data systems and structures, you can effectively reduce your cloud costs. Acceldata offers a solution that enables you to track the performance and quality of your data pipeline both within and outside of tools like Snowflake and Databricks, which results in optimized cost management.
The Acceldata Data Observability Platform empowers companies to adhere to the best practices of all cloud data tools, promptly notifying them and providing recommendations when any violations occur.
By leveraging Acceldata, you gain valuable insights that enable your data teams to develop a comprehensive contract plan, conduct in-depth spend analysis (current and projected), establish department-level tracking, facilitate budgeting, and enable chargeback processes. Moreover, Acceldata helps mitigate the challenges typically associated with businesses transitioning to cloud platforms.
Acceldata can efficiently and affordably facilitate your migration to data tools by offering enhanced visibility and insights that boost the efficiency, reliability, and cost-effectiveness of your data. If you're unsure of where to begin, Acceldata provides a seamless and effective integration that enables you to quickly embark on your data optimization journey.









































.svg)