
























































.svg)



































.png)
As data engineers know all too well, data quality problems can degrade for many reasons.
Schema changes can break processes that feed analytical applications and dashboards.
API calls can fail, interrupting the flow of data.
Manual, one-off data retrievals can create errors and hidden pools of duplicate data.
Data can be duplicated for good reasons, such as to improve query performance. Without strong data governance, though, this can eventually lead to a confusing overabundance of expensive data silos. Data quality also has a major impact on machine learning algorithms.
Migrations from on-premises infrastructures to the cloud can also create a new set of data quality and management challenges. The lack of a unified view of the entire data lifecycle can also create inconsistencies that drag down your data quality.
Finally, there’s one problem that virtually all enterprises face today: scale. The amount of data that enterprises are collecting and storing is growing at an incredible rate — a whopping 63 percent growth per month, according to an IDG survey. The number of data sources is also huge: 400 for the average company, 1,000+ sources for 20 percent of firms.
There is also a tidal wave of data tools in every layer of the modern data stack. Companies have no shortage of choices, from event and CDC streaming platforms, ETL/ELT tools, reverse ETL tools that push insights to business apps, data API and visualization tools, real-time analytics databases, and more.
Many of these data tools are point solutions, early entries in the market. Though each has their merits, trying to cobble a stack from these unintegrated tools helps create fragmented, unreliable, and broken data environments.
Why legacy data quality strategies fail
Companies have tried to solve data quality for years, typically by manually creating data quality policies and rules, often managed and enforced by master data management (MDM) or data governance software.
MDM vendors like Informatica, Oracle, SAP, SAS and others have been around for many decades. Their solutions were born and matured long before the cloud or big data existed.
Unsurprisingly, these antiquated software and strategies can’t scale for today’s much larger data volumes and ever-changing data structures. Scripts and rules must be created and updated by human data engineers one by one. And when alerts are sounded, your data engineers will also need to manually check anomalies, debug data errors, and clean datasets. That’s time-consuming and exhausting.
A good example of the failings of the legacy approach to data quality are manual ETL validation scripts. These have long been used by data engineers to clean and validate recently-ingested data. Applied to data-at-rest, ETL validation scripts are easy to create and flexible, as they can be written in most programming languages and support any technology, data system or process.
However, manual ETL validation scripts are often poorly suited for the volume, velocity and dynamic nature of today’s enterprise data environments. Take streaming data. Event and messaging streams can be too high volume, too dynamic (with constantly-changing schemas) and too real-time for ETL validation scripts to work. These scripts can only process data in batches and must be manually edited with every change to the data structure.
This results in significant validation latency. And this delay is unacceptable for companies undergoing digital transformation, as it rules out use cases such as real-time customer personalization, data-driven logistics, fraud detection and other internal operations, live user leaderboards, etc.
Beyond real-time data, manual ETL validation scripts have other problems. Any change to your data architecture, systems, schemas or processes will force you to update an existing script or create a new one. Fail to keep them updated and you can transform and map data wrong and inadvertently create data quality problems.
To prevent this, organizations need to constantly check if their ETL validation scripts have become outdated, and then have their data engineers spend hours writing and rewriting repetitive ETL validation scripts. This requires significant ongoing engineering time and effort. And it pulls your data engineers away from more-valuable activities such as building new solutions for the business.
Also, if and when your data engineers leave the organization, they take specific knowledge around your ETL validation scripts with them. This creates a steep learning curve for every replacement data engineer.
To handle today’s fast-growing, constantly-changing data environments, data ops teams need a modern platform that leverages machine learning to automate data quality monitoring at whatever scale is required.
Acceldata’s approach to enterprise data observability
The Acceldata Data Observability platform provides an end-to-end solution that helps organizations continuously optimize their data stacks so data teams have clarity – and context – for all data activity and how it relates. Acceldata makes this a reality by providing customers with a single pane of glass into:
- Data pipelines: Stay informed about potential data pipeline issues. Monitor performance across multiple systems and data environments.
- Data reliability: Leverage a variety of data reliability features, including automated data quality monitoring, anomaly detection, and a built-in data catalog.
- Performance: Predict potential performance issues and receive notifications of incidents. Monitor data processing health across your cloud environments.
- Spend: Visualize your spend, detect waste, and easily identify anomalies that require additional investigation.
Advanced AI/ML features of Acceldata can automatically identify anomalies based on historical trends of your CPU, memory, costs, and compute resources. For example, if there is a significant variance in the average expected cost per day, when compared to the historical mean or standard deviation values, Acceldata will automatically detect this and send you an alert.
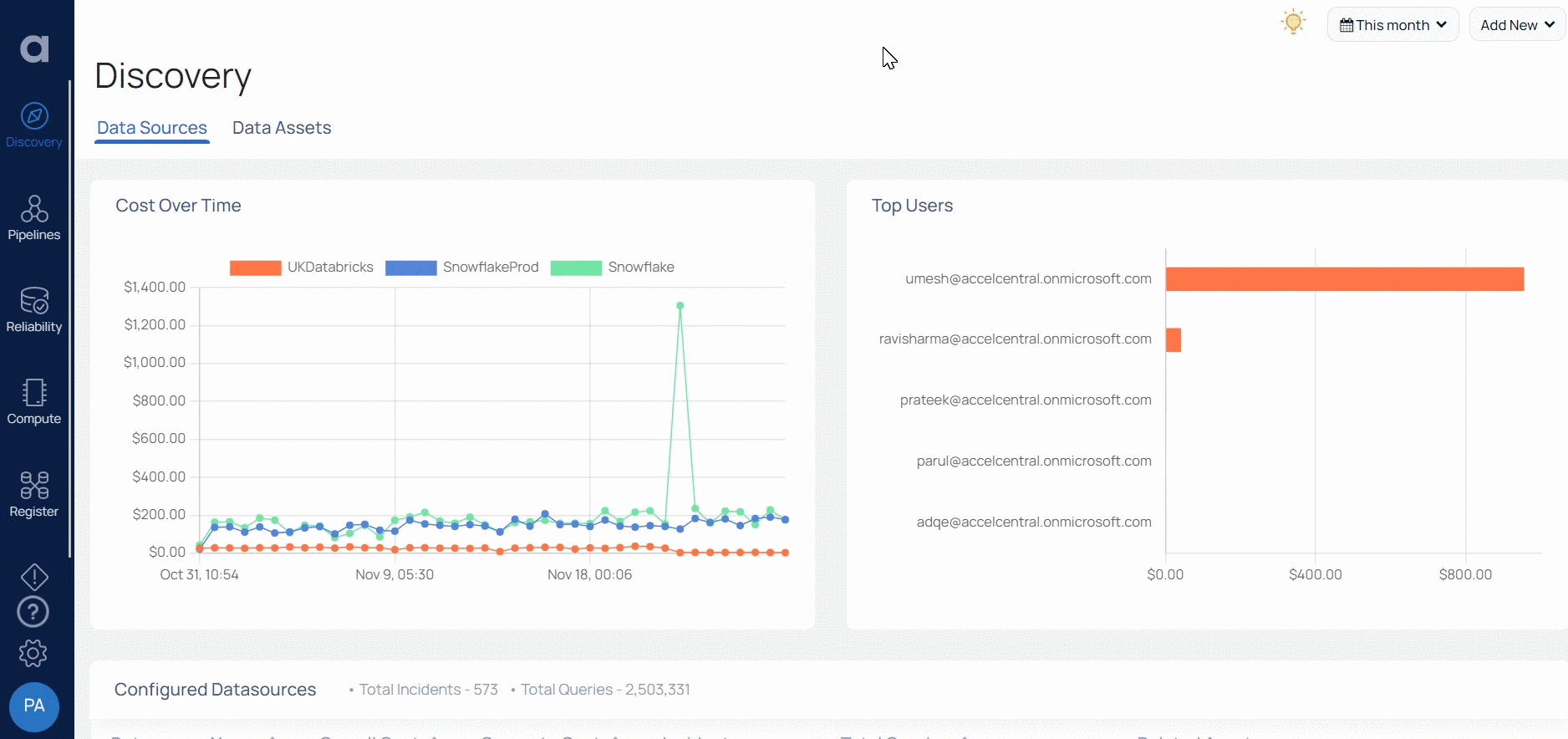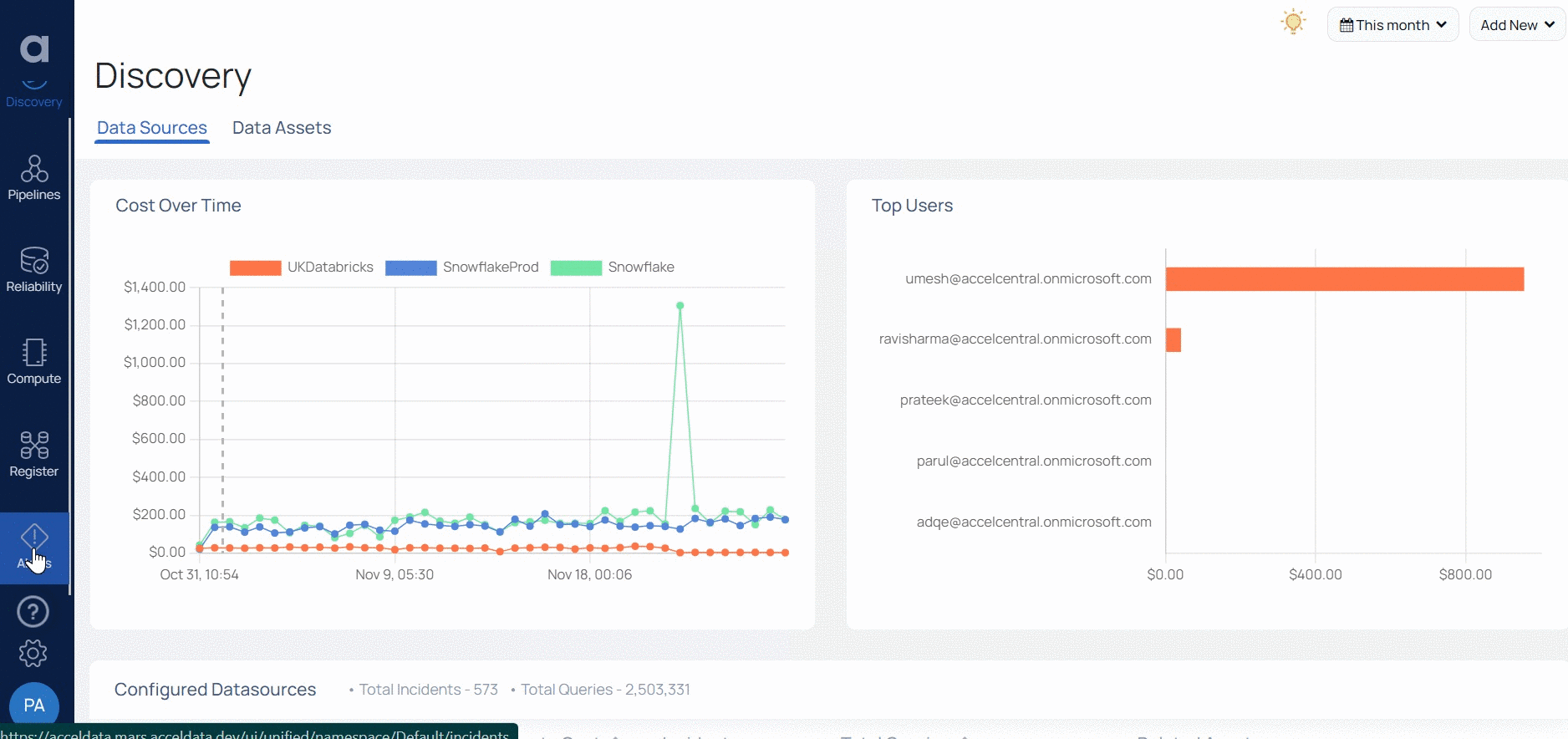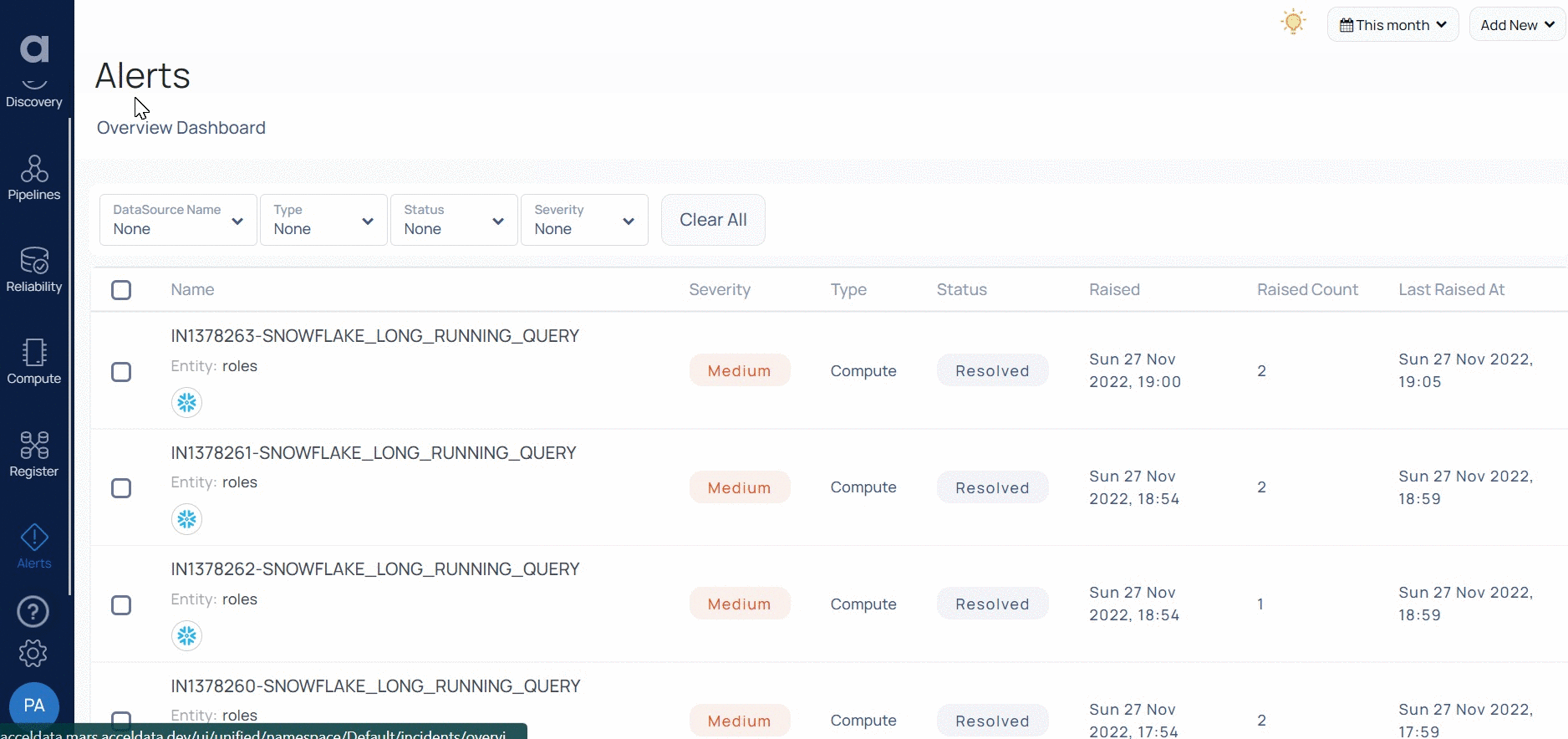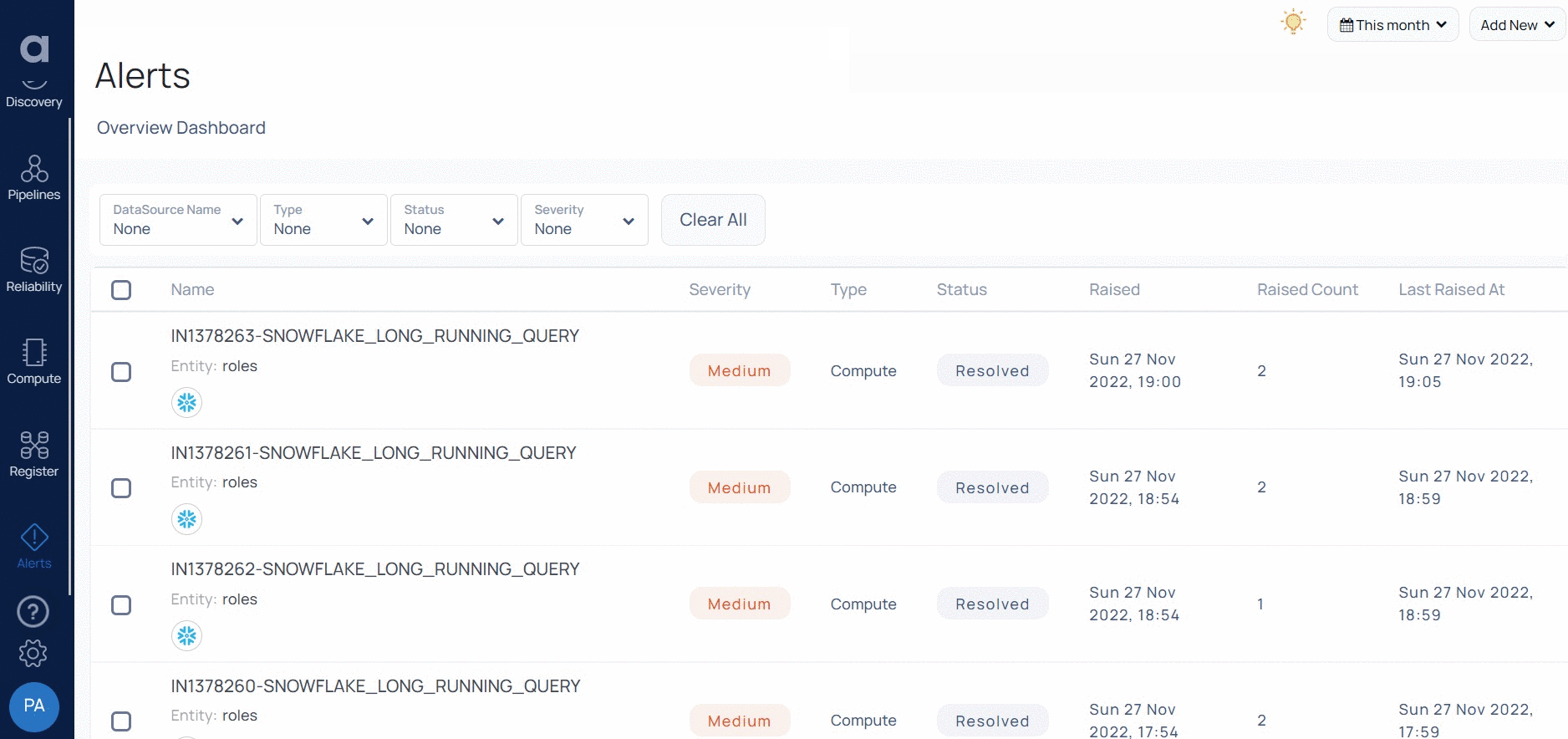
Acceldata can also automatically identify root causes of unexpected behavior changes by comparing application logs, query runtimes, or queue utilization statistics. This helps teams spend less time sifting through large datasets to debug data quality problems.
With enterprise data observability, data teams can correlate events based on historical comparisons, resources used, and the health of your production environment. This can help data engineers to identify the root causes of unexpected behaviors in your production environment faster than ever before. With this type of solution, data teams can analyze changes in systems or behaviors so that data teams can identify root cause problems. It offers data teams the tools to:
- Get an overview of all application logs as a time histogram, searchable by severity or service
- Identify slow queries and their runtime/configuration parameters
- Understand how queue utilization varies for different queries
Overcome data quality challenges with enterprise data observability
Ready to get started with enterprise data observability? Request a demo of Acceldata’s Data Observability platform to see how it can help your organization.
Photo by Jackson Simmer on Unsplash







