

Maximize Snowflake Warehouse Efficiency with Acceldata

The Snowflake cloud data platform allows organizations to store, process, and analyze vast amounts of data. However, running queries and performing data processing operations in Snowflake can still be resource-intensive and time-consuming, especially for large datasets. There are a myriad of considerations and it is critical that data teams use a data observability solution to help them achieve their Snowflake cloud data platform optimization goals.
This is where optimizing the warehouses in Snowflake becomes crucial. By optimizing warehouses, organizations can improve the performance of their data processing operations and reduce their costs. This involves a number of critical tasks, including:
- Selecting the appropriate warehouse size
- Choosing the right number of clusters
- Setting up automatic scaling based on workload demands.
- Additionally, organizations can leverage features such as caching, materialized views, and clustering keys to further optimize their warehouse performance.
In this blog, we'll explore two key techniques for optimizing Snowflake warehouses: query grouping and rightsizing. We will see how a modern approach which uses the Acceldata Data Observability platform offers an extremely easy way to rightsize Snowflake warehouses by implementing an advanced query fingerprinting technique and easily consumable warehouse sizing/utilization insights and recommendations.
Snowflake Queries and Query Optimization
The Snowflake environment processes millions of queries, each with a unique identifier. While Snowflake originated as a data warehouse, the majority of its queries stem from batch processing workloads that are executed periodically. With Snowflake’s Snowsight or classic web console, it is not possible to group these similar or batched queries into a single workload in order to gain cost and performance insights across workloads.
Query grouping via fingerprinting allows the user to easily compare selected executions of grouped queries, along with all the associated metrics, for better understanding. This, in turn, allows for the optimization of queries and improved performance, making the cloud data platform more reliable and cost-effective.
Query grouping can also be used to help identify the optimal data layout or partition clustering for a specific workload. By utilizing query history metadata and query fingerprinting techniques to group similar queries together, the user can gain a deeper understanding of their workloads and identify the most demanding queries. It provides insight into the execution frequency, cost, average latency, and schedule/frequency of the identified workloads within a selected interval. The Acceldata data observability platform utilizes a fingerprinting technique and provides query analysis views that make it easy to understand grouped query behavior.

Rightsizing involves selecting the appropriate size for a warehouse based on the organization's workload. To determine the optimal warehouse size for your newer workloads, Snowflake suggests experimenting with running queries on warehouses of various sizes. Understanding the workload trends and comparing queries side-by-side can help answer questions such as determining the appropriate size of a warehouse based on historical trends and also identifying reasons for slow query performance compared to previous runs.
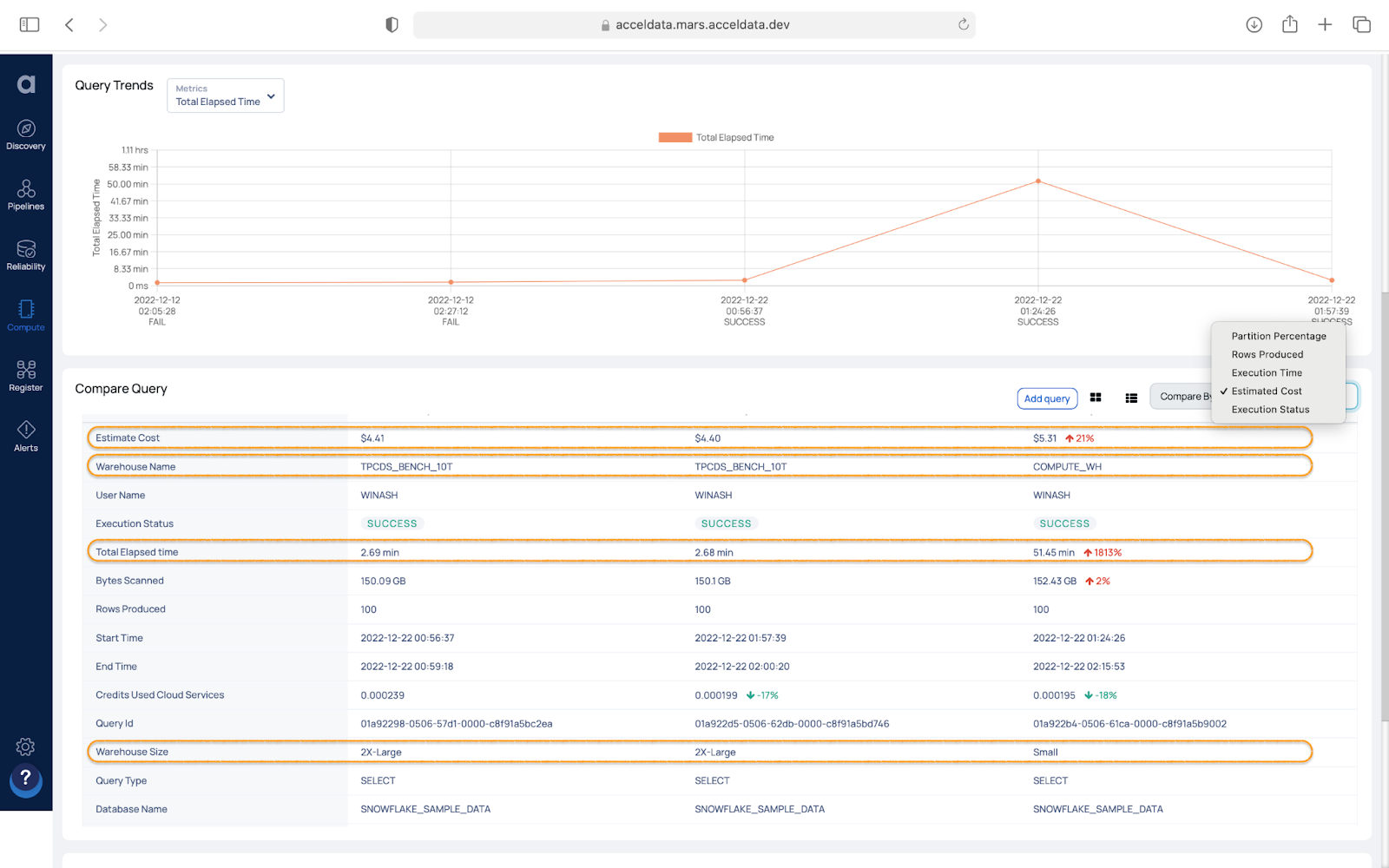
In the given example, running the same TPC-DS benchmark query on different warehouse sizes shows that the query performs much better and is also more cost-effective on the 2X-Large warehouse compared to the Small warehouse.

For workloads that have already been deployed and have some historical statistics, Acceldata data observability platform provides a Snowflake Warehouse resizing page that offers suggestions for optimizing the utilization of your Snowflake warehouses. This functionality assesses the average queue size and average running time of your warehouses and generates recommendations accordingly. You can adjust the average queue size and latency parameters to explore different recommendation options.

To optimize warehouse size, it's important to analyze warehouse utilization based on metrics such as number of queries executed, query execution time, query types, dominant users, frequently executed queries, cache spillage, and credits consumed. The Acceldata data observability platform provides views with various slicing and dicing options for analyzing these metrics along all possible dimensions.
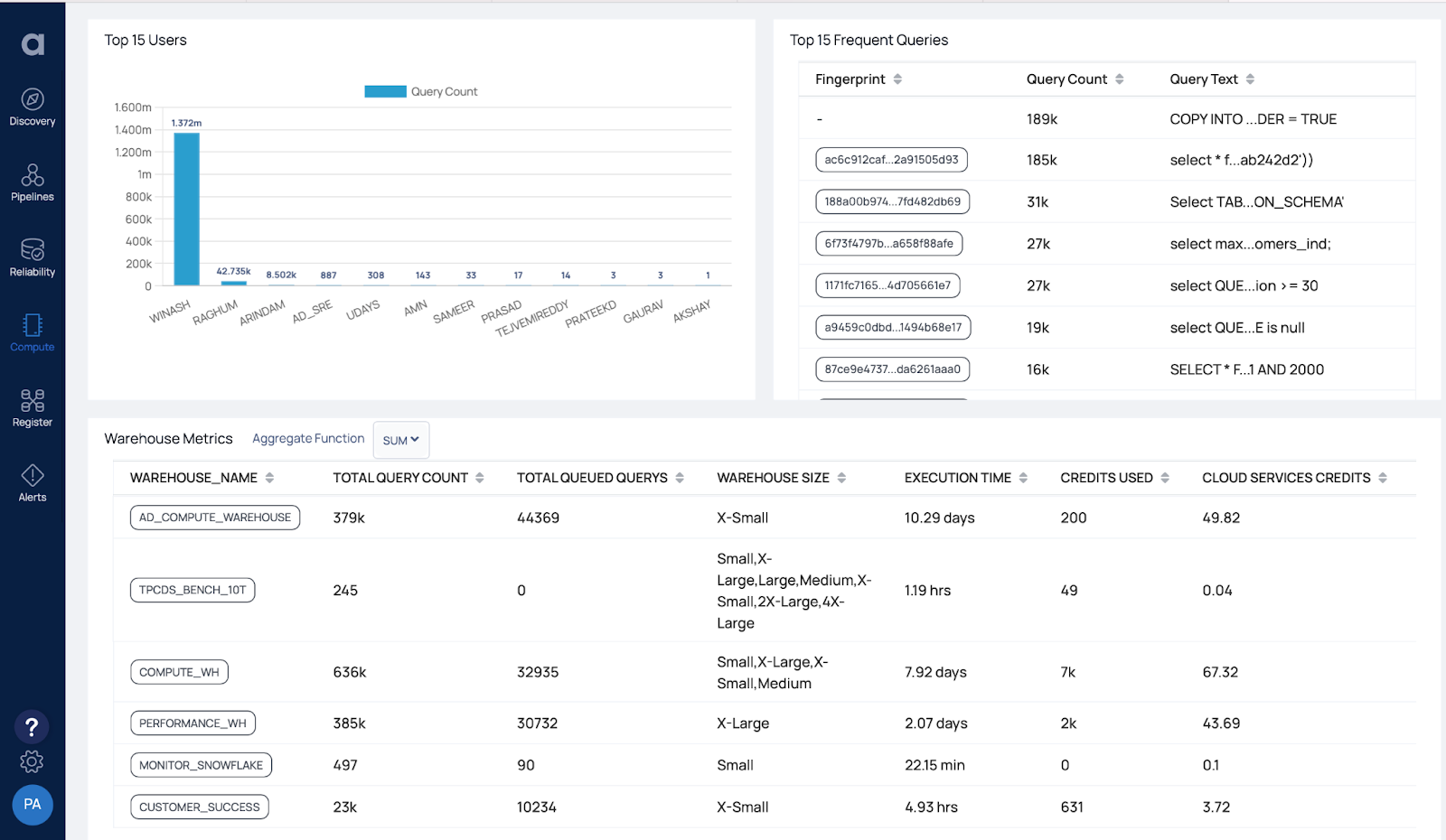
In addition, the platform provides warehouse guardrails to prevent cost overruns and identify any missing or poorly configured safeguards that could lead to costly unintentional errors.

By utilizing these two techniques of rightsizing and query analysis, organizations can optimize their Snowflake warehouses, reduce costs, and improve query performance. This leads to a more efficient use of resources and faster insights into their data, ultimately helping organizations make data-driven decisions and gain a competitive advantage in their industry.
Take a tour of the Acceldata Data Observability platform to see how it helps data teams optimize their Snowflake operations, reliability, and spend performance.
Photo by Marcin Jozwiak on Unsplash

Similar posts
.webp)


Ready to start your
data observability journey?

.webp)
.webp)